 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEASE: Entity-Aware Contrastive Learning of Sentence Embedding
May 09, 2022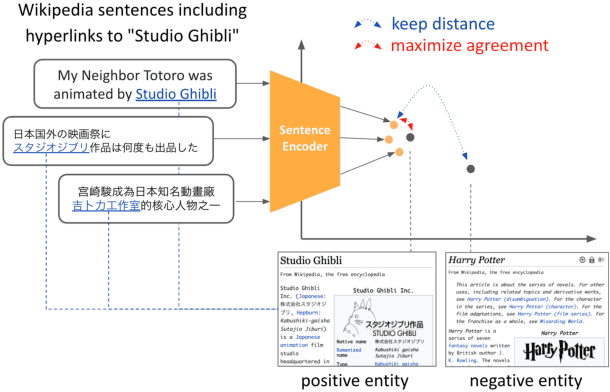
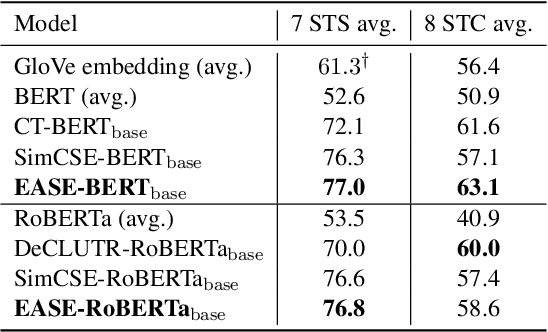

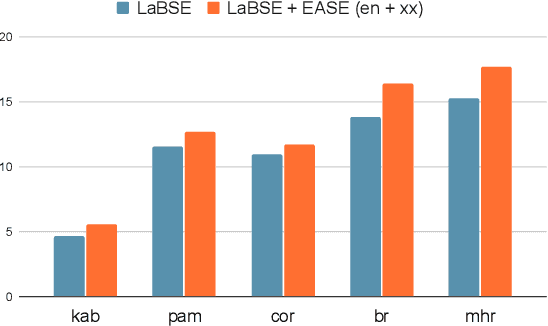
We present EASE, a novel method for learning sentence embeddings via contrastive learning between sentences and their related entities. The advantage of using entity supervision is twofold: (1) entities have been shown to be a strong indicator of text semantics and thus should provide rich training signals for sentence embeddings; (2) entities are defined independently of languages and thus offer useful cross-lingual alignment supervision. We evaluate EASE against other unsupervised models both in monolingual and multilingual settings. We show that EASE exhibits competitive or better performance in English semantic textual similarity (STS) and short text clustering (STC) tasks and it significantly outperforms baseline methods in multilingual settings on a variety of tasks. Our source code, pre-trained models, and newly constructed multilingual STC dataset are available at https://github.com/studio-ousia/ease.
Closer Look at the Transferability of Adversarial Examples: How They Fool Different Models Differently
Dec 29, 2021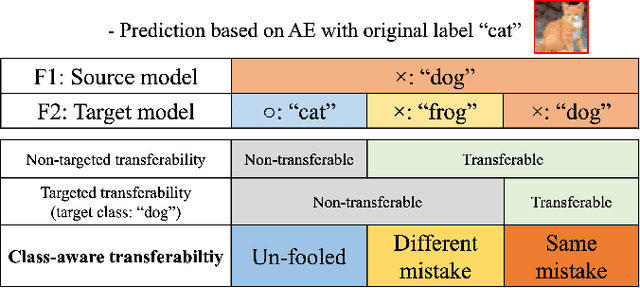
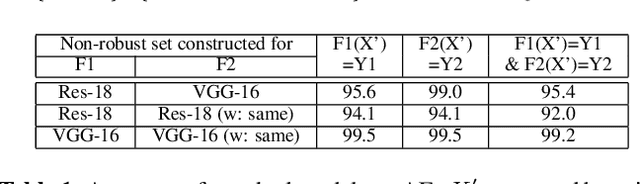
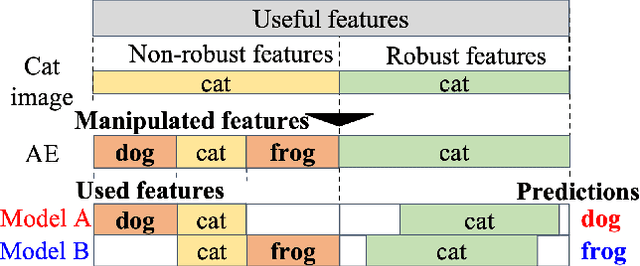
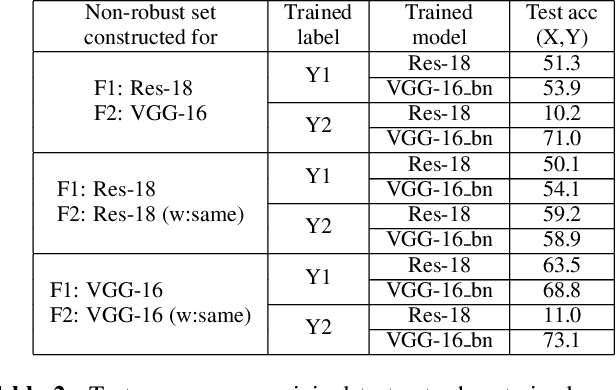
Deep neural networks are vulnerable to adversarial examples (AEs), which have adversarial transferability: AEs generated for the source model can mislead another (target) model's predictions. However, the transferability has not been understood from the perspective of to which class target model's predictions were misled (i.e., class-aware transferability). In this paper, we differentiate the cases in which a target model predicts the same wrong class as the source model ("same mistake") or a different wrong class ("different mistake") to analyze and provide an explanation of the mechanism. First, our analysis shows (1) that same mistakes correlate with "non-targeted transferability" and (2) that different mistakes occur between similar models regardless of the perturbation size. Second, we present evidence that the difference in same and different mistakes can be explained by non-robust features, predictive but human-uninterpretable patterns: different mistakes occur when non-robust features in AEs are used differently by models. Non-robust features can thus provide consistent explanations for the class-aware transferability of AEs.
A Multilingual Bag-of-Entities Model for Zero-Shot Cross-Lingual Text Classification
Oct 15, 2021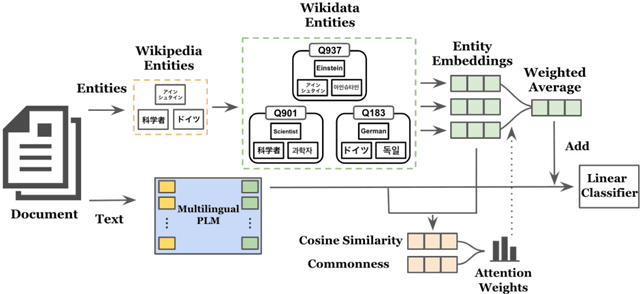
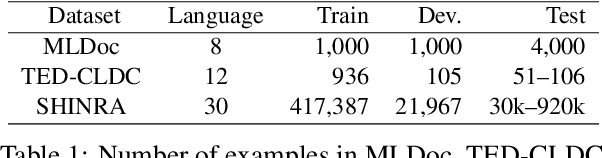
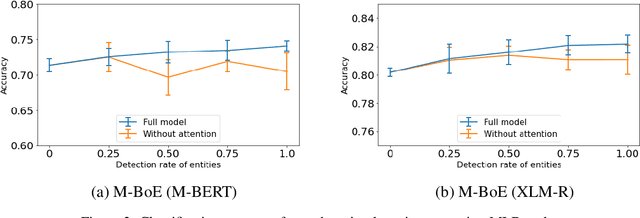
We present a multilingual bag-of-entities model that effectively boosts the performance of zero-shot cross-lingual text classification by extending a multilingual pre-trained language model (e.g., M-BERT). It leverages the multilingual nature of Wikidata: entities in multiple languages representing the same concept are defined with a unique identifier. This enables entities described in multiple languages to be represented using shared embeddings. A model trained on entity features in a resource-rich language can thus be directly applied to other languages. Our experimental results on cross-lingual topic classification (using the MLDoc and TED-CLDC datasets) and entity typing (using the SHINRA2020-ML dataset) show that the proposed model consistently outperforms state-of-the-art models.
Data Augmentation for Learning Bilingual Word Embeddings with Unsupervised Machine Translation
May 30, 2020



Unsupervised bilingual word embedding (BWE) methods learn a linear transformation matrix that maps two monolingual embedding spaces that are separately trained with monolingual corpora. This method assumes that the two embedding spaces are structurally similar, which does not necessarily hold true in general. In this paper, we propose using a pseudo-parallel corpus generated by an unsupervised machine translation model to facilitate structural similarity of the two embedding spaces and improve the quality of BWEs in the mapping method. We show that our approach substantially outperforms baselines and other alternative approaches given the same amount of data, and, through detailed analysis, we argue that data augmentation with the pseudo data from unsupervised machine translation is especially effective for BWEs because (1) the pseudo data makes the source and target corpora (partially) parallel; (2) the pseudo data reflects some nature of the original language that helps learning similar embedding spaces between the source and target languages.