 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Generation of Cause and Effect
Jul 21, 2021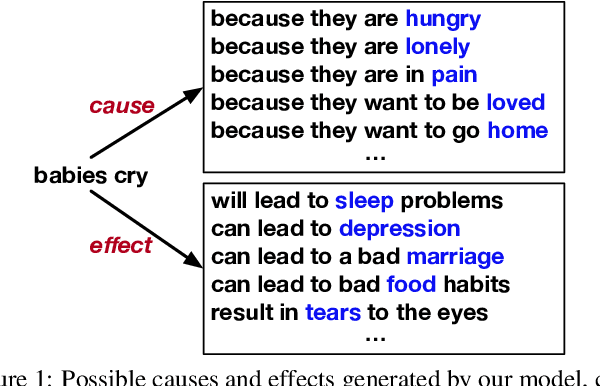
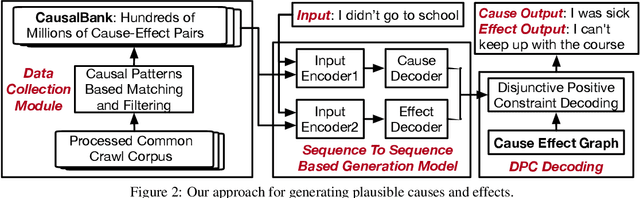
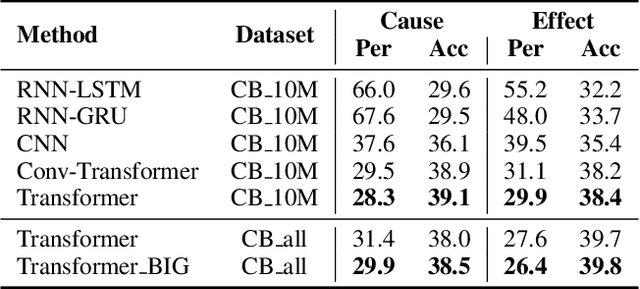
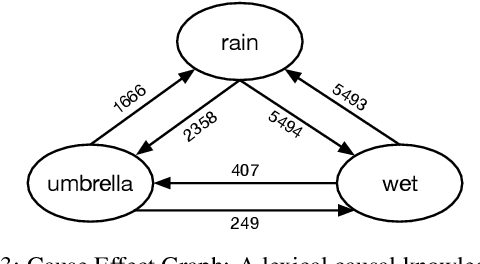
We present a conditional text generation framework that posits sentential expressions of possible causes and effects. This framework depends on two novel resources we develop in the course of this work: a very large-scale collection of English sentences expressing causal patterns CausalBank; and a refinement over previous work on constructing large lexical causal knowledge graphs Cause Effect Graph. Further, we extend prior work in lexically-constrained decoding to support disjunctive positive constraints. Human assessment confirms that our approach gives high-quality and diverse outputs. Finally, we use CausalBank to perform continued training of an encoder supporting a recent state-of-the-art model for causal reasoning, leading to a 3-point improvement on the COPA challenge set, with no change in model architecture.
Iterative Paraphrastic Augmentation with Discriminative Span Alignment
Jul 01, 2020
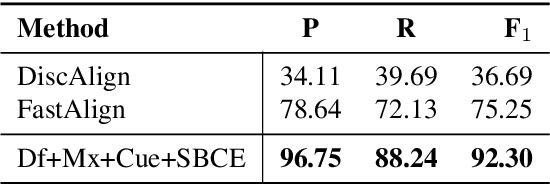

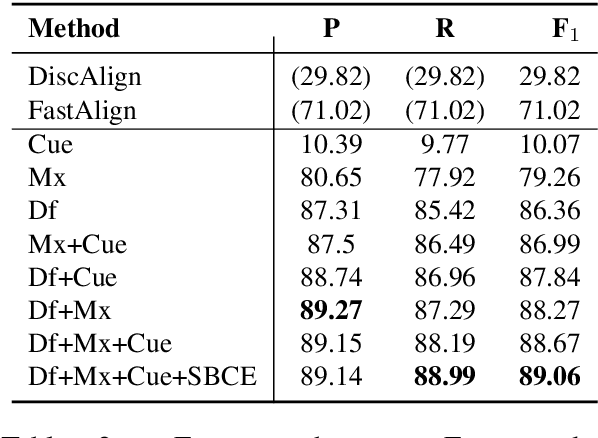
We introduce a novel paraphrastic augmentation strategy based on sentence-level lexically constrained paraphrasing and discriminative span alignment. Our approach allows for the large-scale expansion of existing resources, or the rapid creation of new resources from a small, manually-produced seed corpus. We illustrate our framework on the Berkeley FrameNet Project, a large-scale language understanding effort spanning more than two decades of human labor. Based on roughly four days of collecting training data for the alignment model and approximately one day of parallel compute, we automatically generate 495,300 unique (Frame, Trigger) combinations annotated in context, a roughly 50x expansion atop FrameNet v1.7.
Improved Image Wasserstein Attacks and Defenses
Apr 26, 2020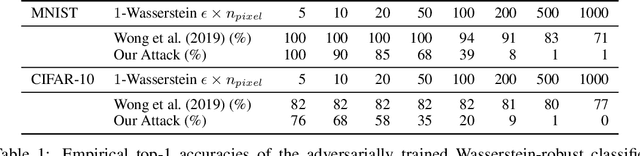
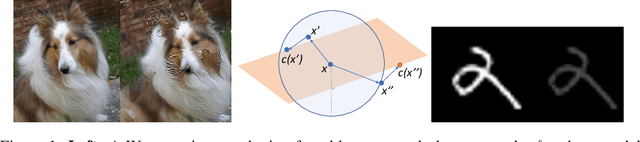

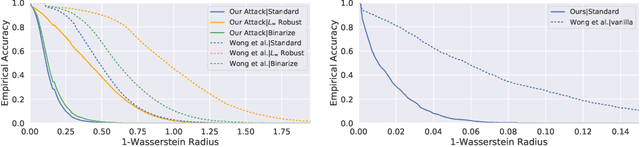
Robustness against image perturbations bounded by a $\ell_p$ ball have been well-studied in recent literature. Perturbations in the real-world, however, rarely exhibit the pixel independence that $\ell_p$ threat models assume. A recently proposed Wasserstein distance-bounded threat model is a promising alternative that limits the perturbation to pixel mass movements. We point out and rectify flaws in previous definition of the Wasserstein threat model and explore stronger attacks and defenses under our better-defined framework. Lastly, we discuss the inability of current Wasserstein-robust models in defending against perturbations seen in the real world. Our code and trained models are available at https://github.com/edwardjhu/improved_wasserstein .
Randomized Smoothing of All Shapes and Sizes
Mar 04, 2020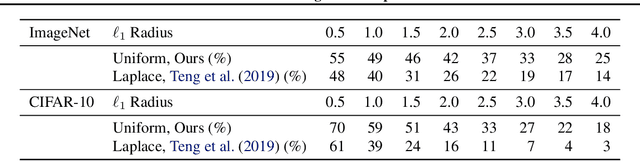

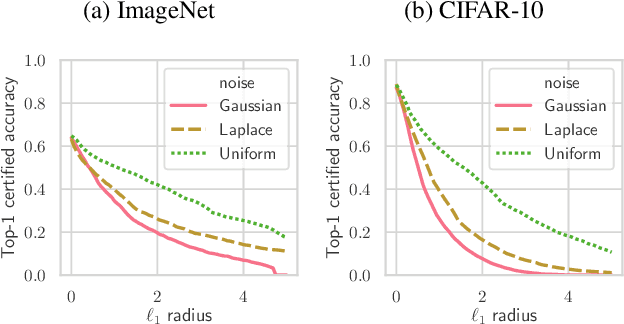
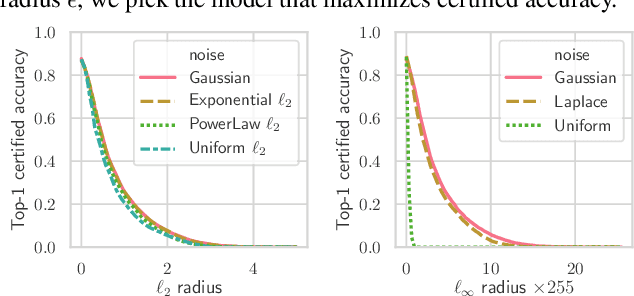
Randomized smoothing is a recently proposed defense against adversarial attacks that has achieved state-of-the-art provable robustness against $\ell_2$ perturbations. Soon after, a number of works devised new randomized smoothing schemes for other metrics, such as $\ell_1$ or $\ell_\infty$; however, for each geometry, substantial effort was needed to derive new robustness guarantees. This begs the question: can we find a general theory for randomized smoothing? In this work we propose a novel framework for devising and analyzing randomized smoothing schemes, and validate its effectiveness in practice. Our theoretical contributions are as follows: (1) We show that for an appropriate notion of "optimal", the optimal smoothing distributions for any "nice" norm have level sets given by the *Wulff Crystal* of that norm. (2) We propose two novel and complementary methods for deriving provably robust radii for any smoothing distribution. Finally, (3) we show fundamental limits to current randomized smoothing techniques via the theory of *Banach space cotypes*. By combining (1) and (2), we significantly improve the state-of-the-art certified accuracy in $\ell_1$ on standard datasets. On the other hand, using (3), we show that, without more information than label statistics under random input perturbations, randomized smoothing cannot achieve nontrivial certified accuracy against perturbations of $\ell_p$-norm $\Omega(\min(1, d^{\frac{1}{p}-\frac{1}{2}}))$, when the input dimension $d$ is large. We provide code in github.com/tonyduan/rs4a.
ParaBank: Monolingual Bitext Generation and Sentential Paraphrasing via Lexically-constrained Neural Machine Translation
Jan 11, 2019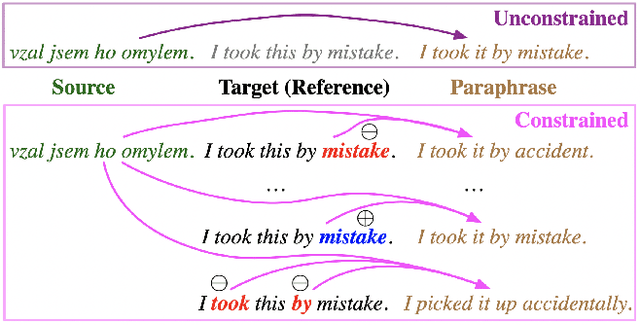

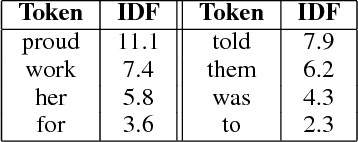
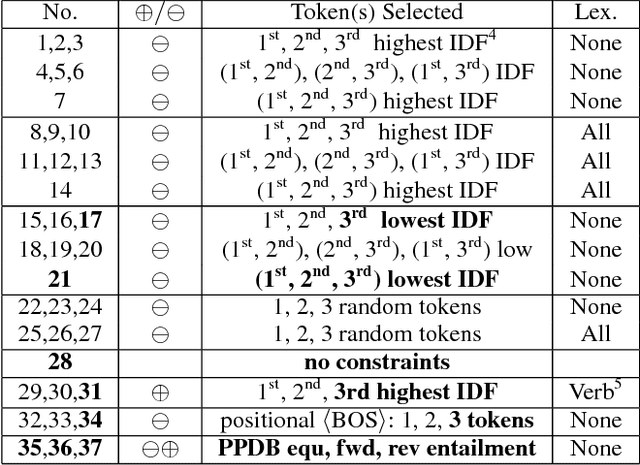
We present ParaBank, a large-scale English paraphrase dataset that surpasses prior work in both quantity and quality. Following the approach of ParaNMT, we train a Czech-English neural machine translation (NMT) system to generate novel paraphrases of English reference sentences. By adding lexical constraints to the NMT decoding procedure, however, we are able to produce multiple high-quality sentential paraphrases per source sentence, yielding an English paraphrase resource with more than 4 billion generated tokens and exhibiting greater lexical diversity. Using human judgments, we also demonstrate that ParaBank's paraphrases improve over ParaNMT on both semantic similarity and fluency. Finally, we use ParaBank to train a monolingual NMT model with the same support for lexically-constrained decoding for sentence rewriting tasks.
Collecting Diverse Natural Language Inference Problems for Sentence Representation Evaluation
Aug 29, 2018
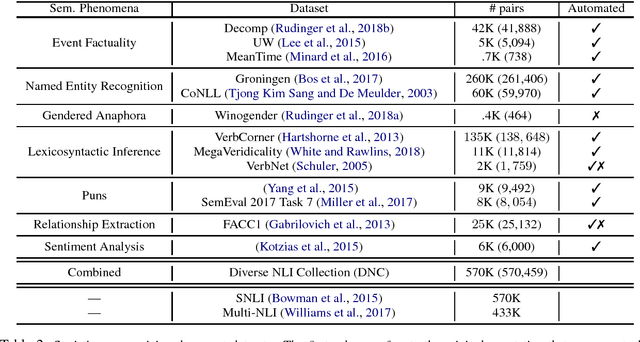
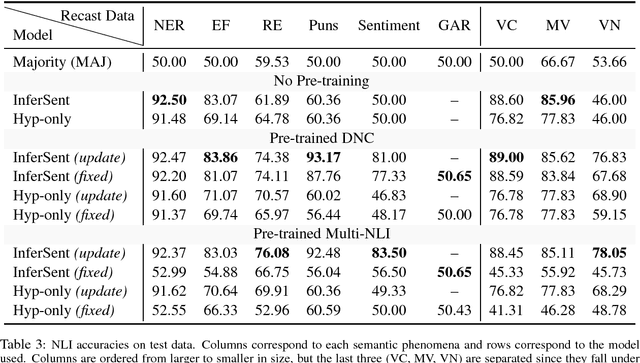
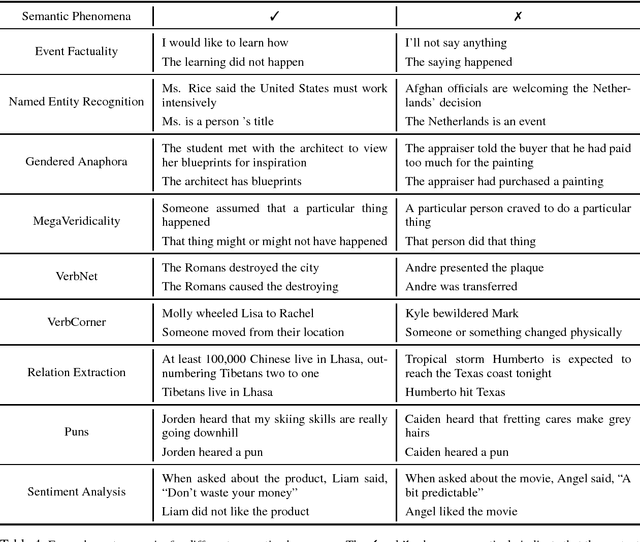
We present a large-scale collection of diverse natural language inference (NLI) datasets that help provide insight into how well a sentence representation captures distinct types of reasoning. The collection results from recasting 13 existing datasets from 7 semantic phenomena into a common NLI structure, resulting in over half a million labeled context-hypothesis pairs in total. We refer to our collection as the DNC: Diverse Natural Language Inference Collection. The DNC is available online at https://www.decomp.net, and will grow over time as additional resources are recast and added from novel sources.