 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaBank: Monolingual Bitext Generation and Sentential Paraphrasing via Lexically-constrained Neural Machine Translation
Paper and Code
Jan 11, 2019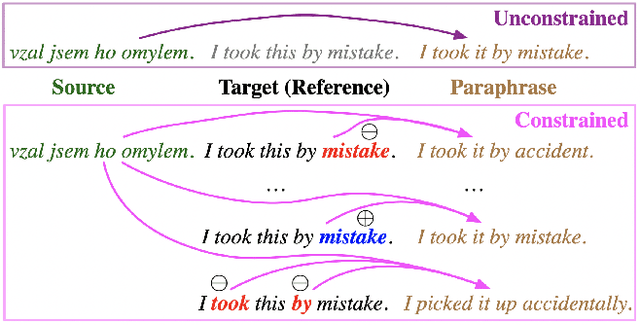

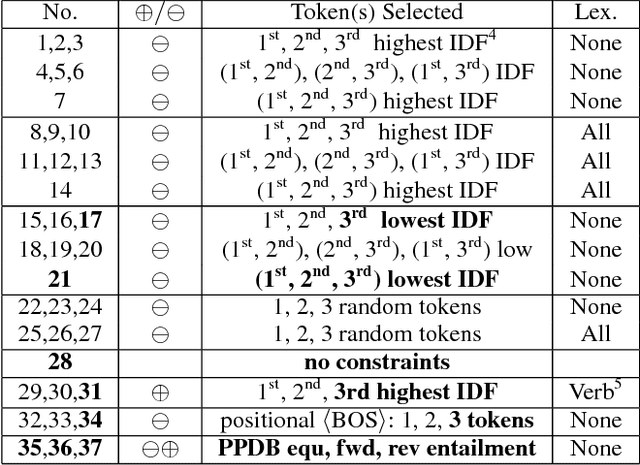
We present ParaBank, a large-scale English paraphrase dataset that surpasses prior work in both quantity and quality. Following the approach of ParaNMT, we train a Czech-English neural machine translation (NMT) system to generate novel paraphrases of English reference sentences. By adding lexical constraints to the NMT decoding procedure, however, we are able to produce multiple high-quality sentential paraphrases per source sentence, yielding an English paraphrase resource with more than 4 billion generated tokens and exhibiting greater lexical diversity. Using human judgments, we also demonstrate that ParaBank's paraphrases improve over ParaNMT on both semantic similarity and fluency. Finally, we use ParaBank to train a monolingual NMT model with the same support for lexically-constrained decoding for sentence rewriting tasks.