 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD-Inference: Fully Serverless Distributed Inference with Scalable Cloud Communication
Mar 22, 2024



Serverless computing offers attractive scalability, elasticity and cost-effectiveness. However, constraints on memory, CPU and function runtime have hindered its adoption for data-intensive applications and machine learning (ML) workloads. Traditional 'server-ful' platforms enable distributed computation via fast networks and well-established inter-process communication (IPC) mechanisms such as MPI and shared memory. In the absence of such solutions in the serverless domain, parallel computation with significant IPC requirements is challenging. We present FSD-Inference, the first fully serverless and highly scalable system for distributed ML inference. We explore potential communication channels, in conjunction with Function-as-a-Service (FaaS) compute, to design a state-of-the-art solution for distributed ML within the context of serverless data-intensive computing. We introduce novel fully serverless communication schemes for ML inference workloads, leveraging both cloud-based publish-subscribe/queueing and object storage offerings. We demonstrate how publish-subscribe/queueing services can be adapted for FaaS IPC with comparable performance to object storage, while offering significantly reduced cost at high parallelism levels. We conduct in-depth experiments on benchmark DNNs of various sizes. The results show that when compared to server-based alternatives, FSD-Inference is significantly more cost-effective and scalable, and can even achieve competitive performance against optimized HPC solutions. Experiments also confirm that our serverless solution can handle large distributed workloads and leverage high degrees of FaaS parallelism.
Low-bit Quantization for Deep Graph Neural Networks with Smoothness-aware Message Propagation
Aug 29, 2023



Graph Neural Network (GNN) training and inference involve significant challenges of scalability with respect to both model sizes and number of layers, resulting in degradation of efficiency and accuracy for large and deep GNNs. We present an end-to-end solution that aims to address these challenges for efficient GNNs in resource constrained environments while avoiding the oversmoothing problem in deep GNNs. We introduce a quantization based approach for all stages of GNNs, from message passing in training to node classification, compressing the model and enabling efficient processing. The proposed GNN quantizer learns quantization ranges and reduces the model size with comparable accuracy even under low-bit quantization. To scale with the number of layers, we devise a message propagation mechanism in training that controls layer-wise changes of similarities between neighboring nodes. This objective is incorporated into a Lagrangian function with constraints and a differential multiplier method is utilized to iteratively find optimal embeddings. This mitigates oversmoothing and suppresses the quantization error to a bound. Significant improvements are demonstrated over state-of-the-art quantization methods and deep GNN approaches in both full-precision and quantized models. The proposed quantizer demonstrates superior performance in INT2 configurations across all stages of GNN, achieving a notable level of accuracy. In contrast, existing quantization approaches fail to generate satisfactory accuracy levels. Finally, the inference with INT2 and INT4 representations exhibits a speedup of 5.11 $\times$ and 4.70 $\times$ compared to full precision counterparts, respectively.
* To appear in CIKM2023
Scalable Graph Convolutional Network Training on Distributed-Memory Systems
Dec 13, 2022
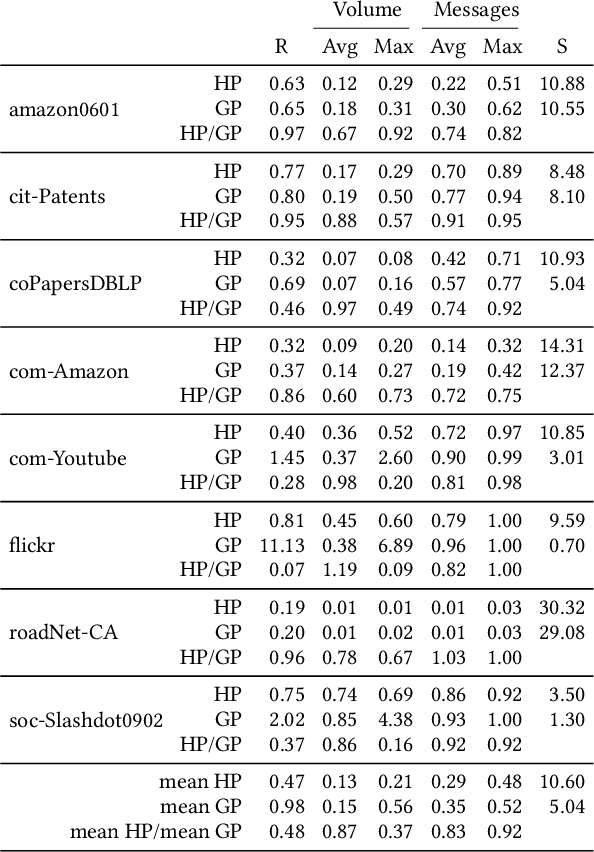
Graph Convolutional Networks (GCNs) are extensively utilized for deep learning on graphs. The large data sizes of graphs and their vertex features make scalable training algorithms and distributed memory systems necessary. Since the convolution operation on graphs induces irregular memory access patterns, designing a memory- and communication-efficient parallel algorithm for GCN training poses unique challenges. We propose a highly parallel training algorithm that scales to large processor counts. In our solution, the large adjacency and vertex-feature matrices are partitioned among processors. We exploit the vertex-partitioning of the graph to use non-blocking point-to-point communication operations between processors for better scalability. To further minimize the parallelization overheads, we introduce a sparse matrix partitioning scheme based on a hypergraph partitioning model for full-batch training. We also propose a novel stochastic hypergraph model to encode the expected communication volume in mini-batch training. We show the merits of the hypergraph model, previously unexplored for GCN training, over the standard graph partitioning model which does not accurately encode the communication costs. Experiments performed on real-world graph datasets demonstrate that the proposed algorithms achieve considerable speedups over alternative solutions. The optimizations achieved on communication costs become even more pronounced at high scalability with many processors. The performance benefits are preserved in deeper GCNs having more layers as well as on billion-scale graphs.
RAGUEL: Recourse-Aware Group Unfairness Elimination
Aug 30, 2022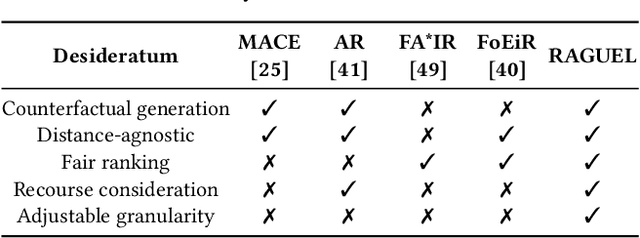
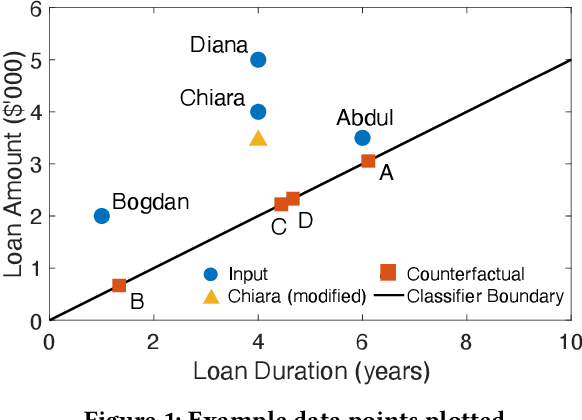
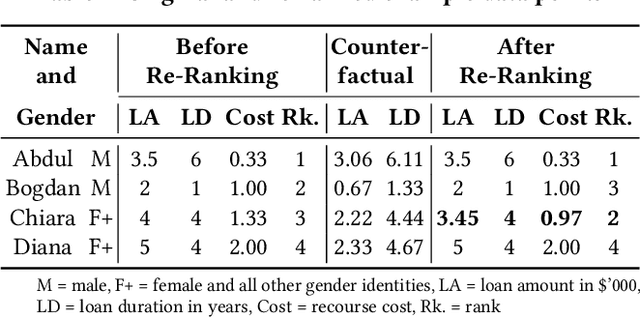
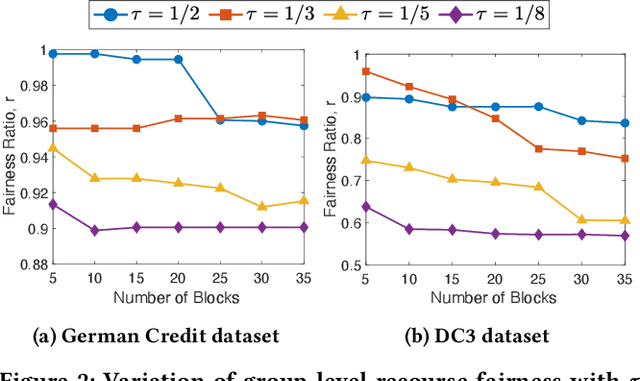
While machine learning and ranking-based systems are in widespread use for sensitive decision-making processes (e.g., determining job candidates, assigning credit scores), they are rife with concerns over unintended biases in their outcomes, which makes algorithmic fairness (e.g., demographic parity, equal opportunity) an objective of interest. 'Algorithmic recourse' offers feasible recovery actions to change unwanted outcomes through the modification of attributes. We introduce the notion of ranked group-level recourse fairness, and develop a 'recourse-aware ranking' solution that satisfies ranked recourse fairness constraints while minimizing the cost of suggested modifications. Our solution suggests interventions that can reorder the ranked list of database records and mitigate group-level unfairness; specifically, disproportionate representation of sub-groups and recourse cost imbalance. This re-ranking identifies the minimum modifications to data points, with these attribute modifications weighted according to their ease of recourse. We then present an efficient block-based extension that enables re-ranking at any granularity (e.g., multiple brackets of bank loan interest rates, multiple pages of search engine results). Evaluation on real datasets shows that, while existing methods may even exacerbate recourse unfairness, our solution -- RAGUEL -- significantly improves recourse-aware fairness. RAGUEL outperforms alternatives at improving recourse fairness, through a combined process of counterfactual generation and re-ranking, whilst remaining efficient for large-scale datasets.
GeoPointGAN: Synthetic Spatial Data with Local Label Differential Privacy
May 18, 2022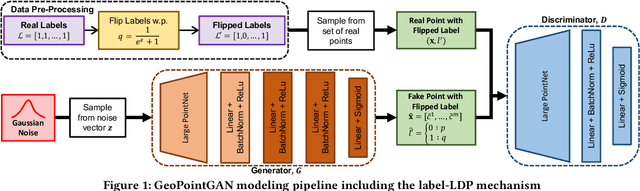
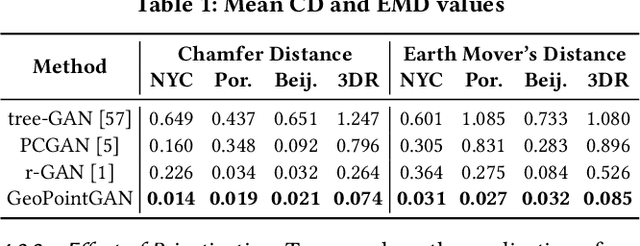
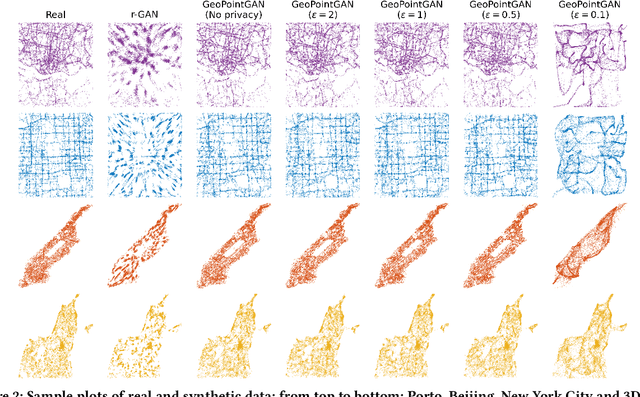
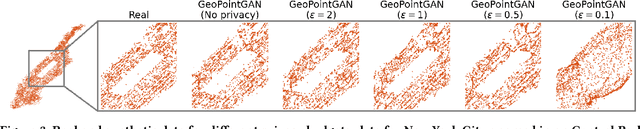
Synthetic data generation is a fundamental task for many data management and data science applications. Spatial data is of particular interest, and its sensitive nature often leads to privacy concerns. We introduce GeoPointGAN, a novel GAN-based solution for generating synthetic spatial point datasets with high utility and strong individual level privacy guarantees. GeoPointGAN's architecture includes a novel point transformation generator that learns to project randomly generated point co-ordinates into meaningful synthetic co-ordinates that capture both microscopic (e.g., junctions, squares) and macroscopic (e.g., parks, lakes) geographic features. We provide our privacy guarantees through label local differential privacy, which is more practical than traditional local differential privacy. We seamlessly integrate this level of privacy into GeoPointGAN by augmenting the discriminator to the point level and implementing a randomized response-based mechanism that flips the labels associated with the 'real' and 'fake' points used in training. Extensive experiments show that GeoPointGAN significantly outperforms recent solutions, improving by up to 10 times compared to the most competitive baseline. We also evaluate GeoPointGAN using range, hotspot, and facility location queries, which confirm the practical effectiveness of GeoPointGAN for privacy-preserving querying. The results illustrate that a strong level of privacy is achieved with little-to-no adverse utility cost, which we explain through the generalization and regularization effects that are realized by flipping the labels of the data during training.
Partitioning sparse deep neural networks for scalable training and inference
Apr 23, 2021

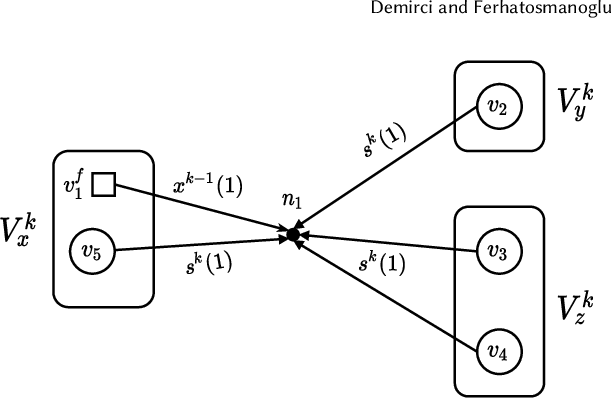
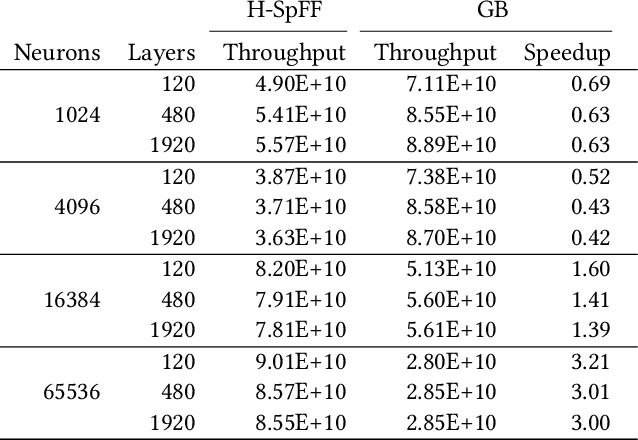
The state-of-the-art deep neural networks (DNNs) have significant computational and data management requirements. The size of both training data and models continue to increase. Sparsification and pruning methods are shown to be effective in removing a large fraction of connections in DNNs. The resulting sparse networks present unique challenges to further improve the computational efficiency of training and inference in deep learning. Both the feedforward (inference) and backpropagation steps in stochastic gradient descent (SGD) algorithm for training sparse DNNs involve consecutive sparse matrix-vector multiplications (SpMVs). We first introduce a distributed-memory parallel SpMV-based solution for the SGD algorithm to improve its scalability. The parallelization approach is based on row-wise partitioning of weight matrices that represent neuron connections between consecutive layers. We then propose a novel hypergraph model for partitioning weight matrices to reduce the total communication volume and ensure computational load-balance among processors. Experiments performed on sparse DNNs demonstrate that the proposed solution is highly efficient and scalable. By utilizing the proposed matrix partitioning scheme, the performance of our solution is further improved significantly.
VISIR: Visual and Semantic Image Label Refinement
Sep 02, 2019

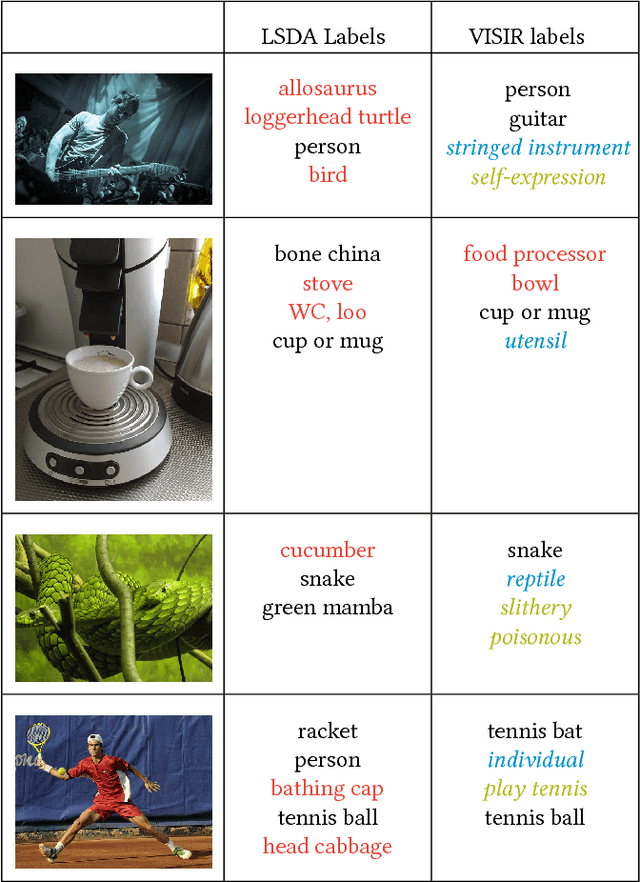
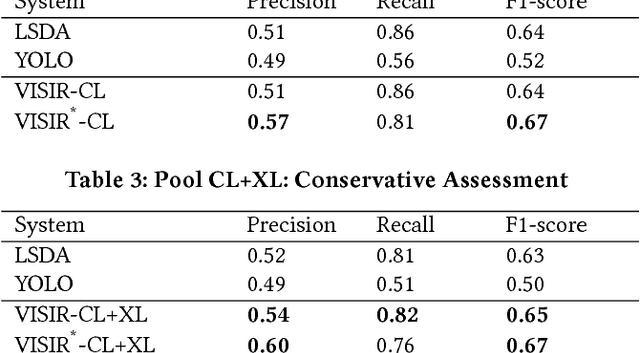
The social media explosion has populated the Internet with a wealth of images. There are two existing paradigms for image retrieval: 1) content-based image retrieval (CBIR), which has traditionally used visual features for similarity search (e.g., SIFT features), and 2) tag-based image retrieval (TBIR), which has relied on user tagging (e.g., Flickr tags). CBIR now gains semantic expressiveness by advances in deep-learning-based detection of visual labels. TBIR benefits from query-and-click logs to automatically infer more informative labels. However, learning-based tagging still yields noisy labels and is restricted to concrete objects, missing out on generalizations and abstractions. Click-based tagging is limited to terms that appear in the textual context of an image or in queries that lead to a click. This paper addresses the above limitations by semantically refining and expanding the labels suggested by learning-based object detection. We consider the semantic coherence between the labels for different objects, leverage lexical and commonsense knowledge, and cast the label assignment into a constrained optimization problem solved by an integer linear program. Experiments show that our method, called VISIR, improves the quality of the state-of-the-art visual labeling tools like LSDA and YOLO.
* Published in WSDM 2018
Characterizing the impact of geometric properties of word embeddings on task performance
Apr 09, 2019
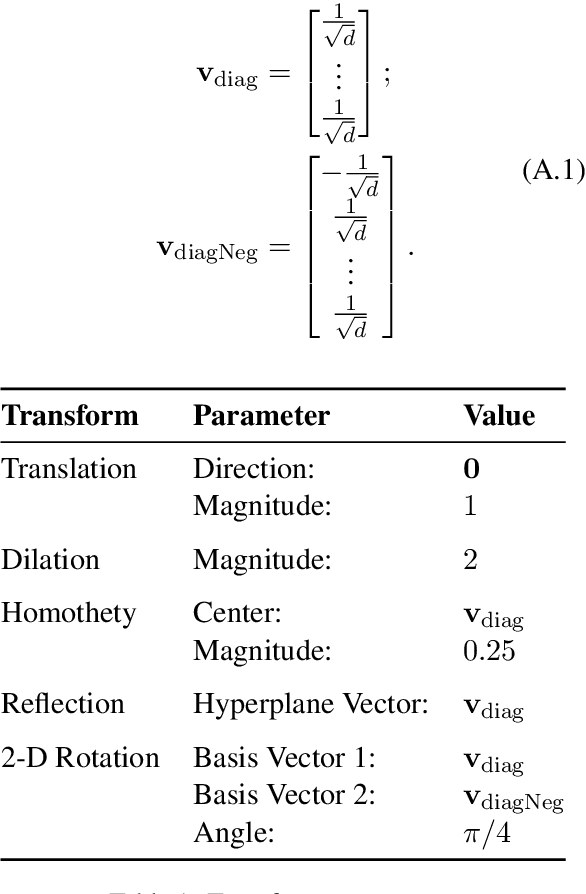

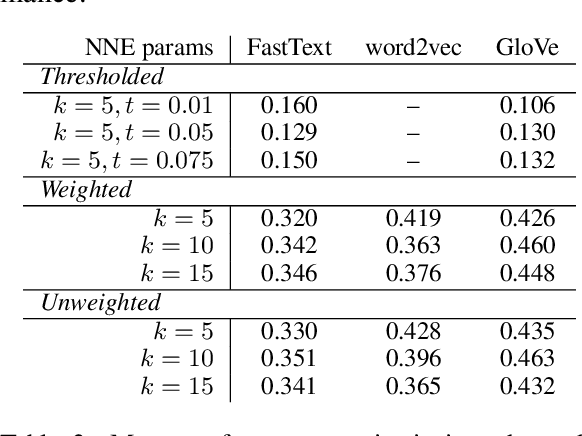
Analysis of word embedding properties to inform their use in downstream NLP tasks has largely been studied by assessing nearest neighbors. However, geometric properties of the continuous feature space contribute directly to the use of embedding features in downstream models, and are largely unexplored. We consider four properties of word embedding geometry, namely: position relative to the origin, distribution of features in the vector space, global pairwise distances, and local pairwise distances. We define a sequence of transformations to generate new embeddings that expose subsets of these properties to downstream models and evaluate change in task performance to understand the contribution of each property to NLP models. We transform publicly available pretrained embeddings from three popular toolkits (word2vec, GloVe, and FastText) and evaluate on a variety of intrinsic tasks, which model linguistic information in the vector space, and extrinsic tasks, which use vectors as input to machine learning models. We find that intrinsic evaluations are highly sensitive to absolute position, while extrinsic tasks rely primarily on local similarity. Our findings suggest that future embedding models and post-processing techniques should focus primarily on similarity to nearby points in vector space.