 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISIR: Visual and Semantic Image Label Refinement
Sep 02, 2019

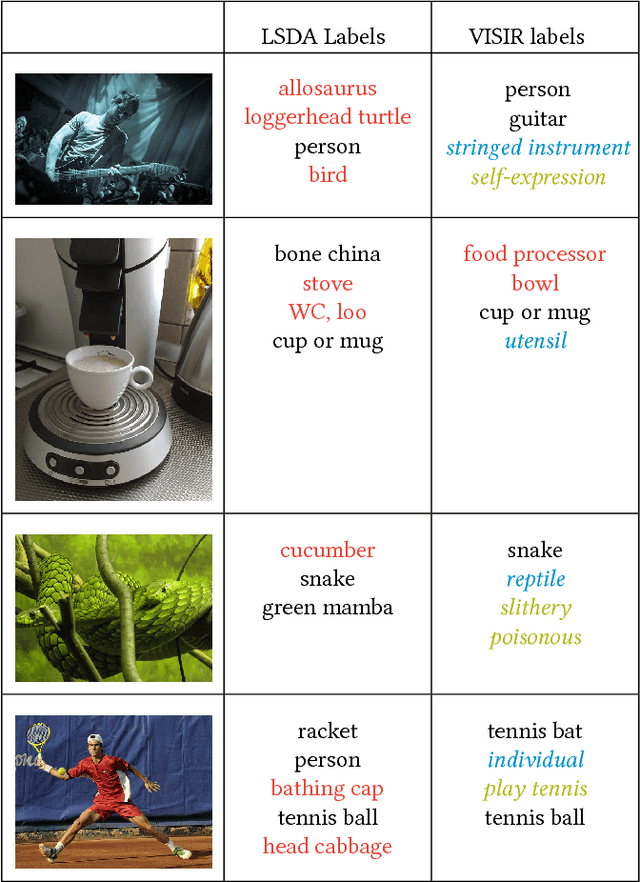
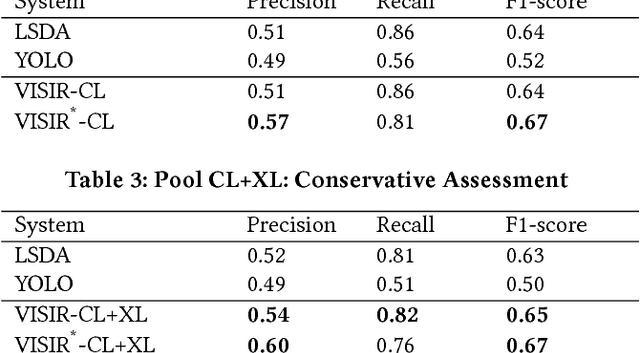
The social media explosion has populated the Internet with a wealth of images. There are two existing paradigms for image retrieval: 1) content-based image retrieval (CBIR), which has traditionally used visual features for similarity search (e.g., SIFT features), and 2) tag-based image retrieval (TBIR), which has relied on user tagging (e.g., Flickr tags). CBIR now gains semantic expressiveness by advances in deep-learning-based detection of visual labels. TBIR benefits from query-and-click logs to automatically infer more informative labels. However, learning-based tagging still yields noisy labels and is restricted to concrete objects, missing out on generalizations and abstractions. Click-based tagging is limited to terms that appear in the textual context of an image or in queries that lead to a click. This paper addresses the above limitations by semantically refining and expanding the labels suggested by learning-based object detection. We consider the semantic coherence between the labels for different objects, leverage lexical and commonsense knowledge, and cast the label assignment into a constrained optimization problem solved by an integer linear program. Experiments show that our method, called VISIR, improves the quality of the state-of-the-art visual labeling tools like LSDA and YOLO.
* Published in WSDM 2018
Story-oriented Image Selection and Placement
Sep 02, 2019


Multimodal contents have become commonplace on the Internet today, manifested as news articles, social media posts, and personal or business blog posts. Among the various kinds of media (images, videos, graphics, icons, audio) used in such multimodal stories, images are the most popular. The selection of images from a collection - either author's personal photo album, or web repositories - and their meticulous placement within a text, builds a succinct multimodal commentary for digital consumption. In this paper we present a system that automates the process of selecting relevant images for a story and placing them at contextual paragraphs within the story for a multimodal narration. We leverage automatic object recognition, user-provided tags, and commonsense knowledge, and use an unsupervised combinatorial optimization to solve the selection and placement problems seamlessly as a single unit.
CITE: A Corpus of Image-Text Discourse Relations
Apr 16, 2019


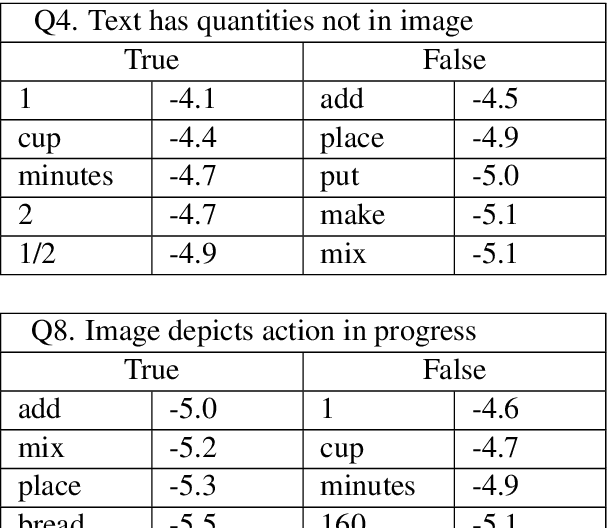
This paper presents a novel crowd-sourced resource for multimodal discourse: our resource characterizes inferences in image-text contexts in the domain of cooking recipes in the form of coherence relations. Like previous corpora annotating discourse structure between text arguments, such as the Penn Discourse Treebank, our new corpus aids in establishing a better understanding of natural communication and common-sense reasoning, while our findings have implications for a wide range of applications, such as understanding and generation of multimodal documents.
* 7 pages
Contextual Media Retrieval Using Natural Language Queries
Feb 16, 2016

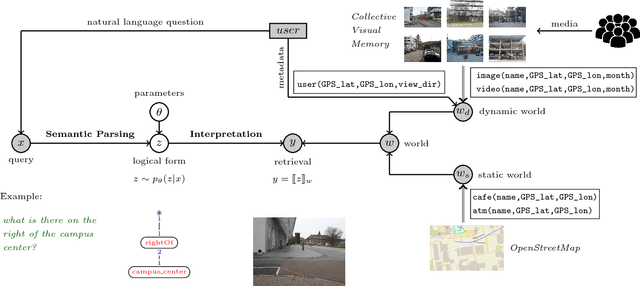
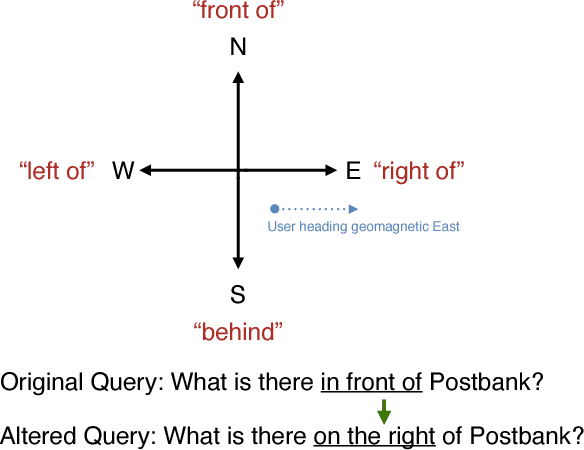
The widespread integration of cameras in hand-held and head-worn devices as well as the ability to share content online enables a large and diverse visual capture of the world that millions of users build up collectively every day. We envision these images as well as associated meta information, such as GPS coordinates and timestamps, to form a collective visual memory that can be queried while automatically taking the ever-changing context of mobile users into account. As a first step towards this vision, in this work we present Xplore-M-Ego: a novel media retrieval system that allows users to query a dynamic database of images and videos using spatio-temporal natural language queries. We evaluate our system using a new dataset of real user queries as well as through a usability study. One key finding is that there is a considerable amount of inter-user variability, for example in the resolution of spatial relations in natural language utterances. We show that our retrieval system can cope with this variability using personalisation through an online learning-based retrieval formulation.