Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCITE: A Corpus of Image-Text Discourse Relations
Paper and Code



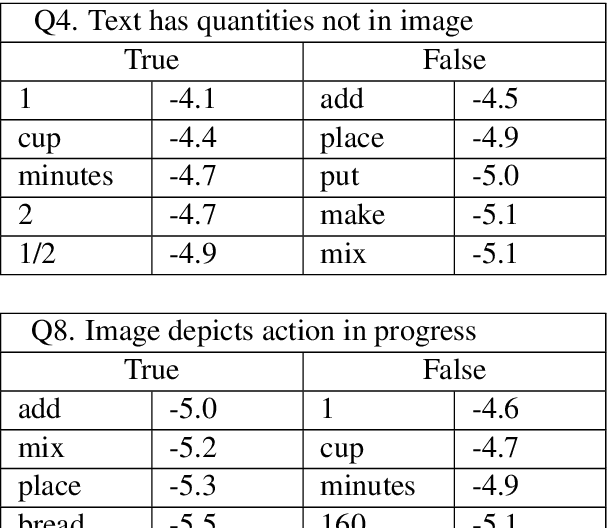
This paper presents a novel crowd-sourced resource for multimodal discourse: our resource characterizes inferences in image-text contexts in the domain of cooking recipes in the form of coherence relations. Like previous corpora annotating discourse structure between text arguments, such as the Penn Discourse Treebank, our new corpus aids in establishing a better understanding of natural communication and common-sense reasoning, while our findings have implications for a wide range of applications, such as understanding and generation of multimodal documents.
* 2019 Annual Conference of the North American Chapter of the
Association for Computational Linguistics * 7 pages
View paper on