 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenTrace: Multi-Concept Attribution through Watermarked Token Recovery
Feb 22, 2026Generative AI models pose a significant challenge to intellectual property (IP), as they can replicate unique artistic styles and concepts without attribution. While watermarking offers a potential solution, existing methods often fail in complex scenarios where multiple concepts (e.g., an object and an artistic style) are composed within a single image. These methods struggle to disentangle and attribute each concept individually. In this work, we introduce TokenTrace, a novel proactive watermarking framework for robust, multi-concept attribution. Our method embeds secret signatures into the semantic domain by simultaneously perturbing the text prompt embedding and the initial latent noise that guide the diffusion model's generation process. For retrieval, we propose a query-based TokenTrace module that takes the generated image and a textual query specifying which concepts need to be retrieved (e.g., a specific object or style) as inputs. This query-based mechanism allows the module to disentangle and independently verify the presence of multiple concepts from a single generated image. Extensive experiments show that our method achieves state-of-the-art performance on both single-concept (object and style) and multi-concept attribution tasks, significantly outperforming existing baselines while maintaining high visual quality and robustness to common transformations.
Your Text Encoder Can Be An Object-Level Watermarking Controller
Mar 15, 2025Invisible watermarking of AI-generated images can help with copyright protection, enabling detection and identification of AI-generated media. In this work, we present a novel approach to watermark images of T2I Latent Diffusion Models (LDMs). By only fine-tuning text token embeddings $W_*$, we enable watermarking in selected objects or parts of the image, offering greater flexibility compared to traditional full-image watermarking. Our method leverages the text encoder's compatibility across various LDMs, allowing plug-and-play integration for different LDMs. Moreover, introducing the watermark early in the encoding stage improves robustness to adversarial perturbations in later stages of the pipeline. Our approach achieves $99\%$ bit accuracy ($48$ bits) with a $10^5 \times$ reduction in model parameters, enabling efficient watermarking.
Proactive Schemes: A Survey of Adversarial Attacks for Social Good
Sep 24, 2024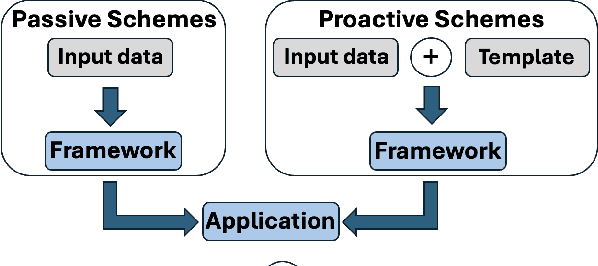

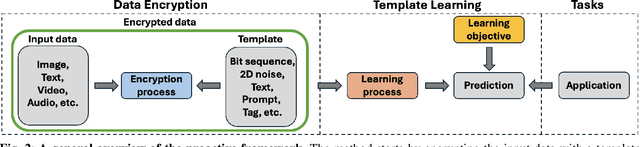
Adversarial attacks in computer vision exploit the vulnerabilities of machine learning models by introducing subtle perturbations to input data, often leading to incorrect predictions or classifications. These attacks have evolved in sophistication with the advent of deep learning, presenting significant challenges in critical applications, which can be harmful for society. However, there is also a rich line of research from a transformative perspective that leverages adversarial techniques for social good. Specifically, we examine the rise of proactive schemes-methods that encrypt input data using additional signals termed templates, to enhance the performance of deep learning models. By embedding these imperceptible templates into digital media, proactive schemes are applied across various applications, from simple image enhancements to complicated deep learning frameworks to aid performance, as compared to the passive schemes, which don't change the input data distribution for their framework. The survey delves into the methodologies behind these proactive schemes, the encryption and learning processes, and their application to modern computer vision and natural language processing applications. Additionally, it discusses the challenges, potential vulnerabilities, and future directions for proactive schemes, ultimately highlighting their potential to foster the responsible and secure advancement of deep learning technologies.
ProMark: Proactive Diffusion Watermarking for Causal Attribution
Mar 14, 2024



Generative AI (GenAI) is transforming creative workflows through the capability to synthesize and manipulate images via high-level prompts. Yet creatives are not well supported to receive recognition or reward for the use of their content in GenAI training. To this end, we propose ProMark, a causal attribution technique to attribute a synthetically generated image to its training data concepts like objects, motifs, templates, artists, or styles. The concept information is proactively embedded into the input training images using imperceptible watermarks, and the diffusion models (unconditional or conditional) are trained to retain the corresponding watermarks in generated images. We show that we can embed as many as $2^{16}$ unique watermarks into the training data, and each training image can contain more than one watermark. ProMark can maintain image quality whilst outperforming correlation-based attribution. Finally, several qualitative examples are presented, providing the confidence that the presence of the watermark conveys a causative relationship between training data and synthetic images.
Tracing Hyperparameter Dependencies for Model Parsing via Learnable Graph Pooling Network
Dec 03, 2023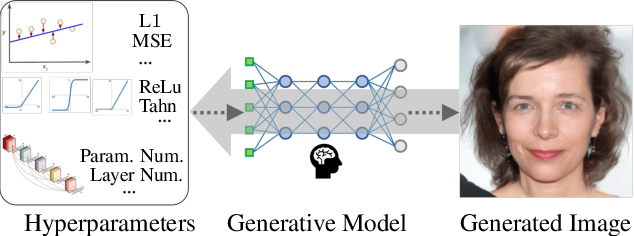



Model Parsing defines the research task of predicting hyperparameters of the generative model (GM), given a generated image as input. Since a diverse set of hyperparameters is jointly employed by the generative model, and dependencies often exist among them, it is crucial to learn these hyperparameter dependencies for the improved model parsing performance. To explore such important dependencies, we propose a novel model parsing method called Learnable Graph Pooling Network (LGPN). Specifically, we transform model parsing into a graph node classification task, using graph nodes and edges to represent hyperparameters and their dependencies, respectively. Furthermore, LGPN incorporates a learnable pooling-unpooling mechanism tailored to model parsing, which adaptively learns hyperparameter dependencies of GMs used to generate the input image. We also extend our proposed method to CNN-generated image detection and coordinate attacks detection. Empirically, we achieve state-of-the-art results in model parsing and its extended applications, showing the effectiveness of our method. Our source code are available.
PrObeD: Proactive Object Detection Wrapper
Oct 28, 2023



Previous research in $2D$ object detection focuses on various tasks, including detecting objects in generic and camouflaged images. These works are regarded as passive works for object detection as they take the input image as is. However, convergence to global minima is not guaranteed to be optimal in neural networks; therefore, we argue that the trained weights in the object detector are not optimal. To rectify this problem, we propose a wrapper based on proactive schemes, PrObeD, which enhances the performance of these object detectors by learning a signal. PrObeD consists of an encoder-decoder architecture, where the encoder network generates an image-dependent signal termed templates to encrypt the input images, and the decoder recovers this template from the encrypted images. We propose that learning the optimum template results in an object detector with an improved detection performance. The template acts as a mask to the input images to highlight semantics useful for the object detector. Finetuning the object detector with these encrypted images enhances the detection performance for both generic and camouflaged. Our experiments on MS-COCO, CAMO, COD$10$K, and NC$4$K datasets show improvement over different detectors after applying PrObeD. Our models/codes are available at https://github.com/vishal3477/Proactive-Object-Detection.
MaLP: Manipulation Localization Using a Proactive Scheme
Apr 04, 2023



Advancements in the generation quality of various Generative Models (GMs) has made it necessary to not only perform binary manipulation detection but also localize the modified pixels in an image. However, prior works termed as passive for manipulation localization exhibit poor generalization performance over unseen GMs and attribute modifications. To combat this issue, we propose a proactive scheme for manipulation localization, termed MaLP. We encrypt the real images by adding a learned template. If the image is manipulated by any GM, this added protection from the template not only aids binary detection but also helps in identifying the pixels modified by the GM. The template is learned by leveraging local and global-level features estimated by a two-branch architecture. We show that MaLP performs better than prior passive works. We also show the generalizability of MaLP by testing on 22 different GMs, providing a benchmark for future research on manipulation localization. Finally, we show that MaLP can be used as a discriminator for improving the generation quality of GMs. Our models/codes are available at www.github.com/vishal3477/pro_loc.
Proactive Image Manipulation Detection
Mar 31, 2022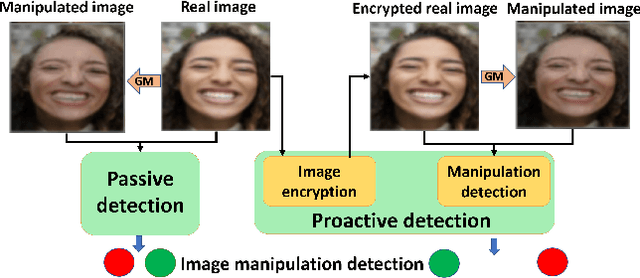
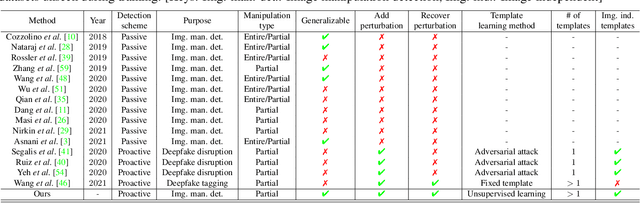
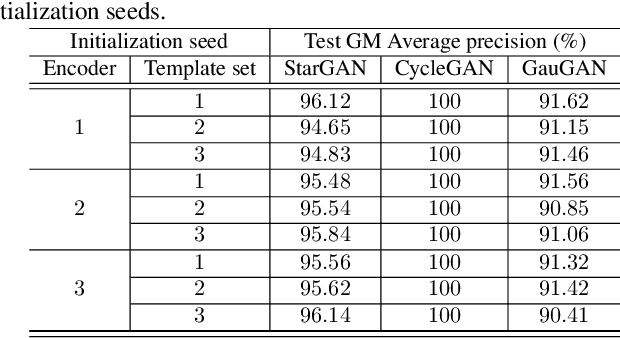

Image manipulation detection algorithms are often trained to discriminate between images manipulated with particular Generative Models (GMs) and genuine/real images, yet generalize poorly to images manipulated with GMs unseen in the training. Conventional detection algorithms receive an input image passively. By contrast, we propose a proactive scheme to image manipulation detection. Our key enabling technique is to estimate a set of templates which when added onto the real image would lead to more accurate manipulation detection. That is, a template protected real image, and its manipulated version, is better discriminated compared to the original real image vs. its manipulated one. These templates are estimated using certain constraints based on the desired properties of templates. For image manipulation detection, our proposed approach outperforms the prior work by an average precision of 16% for CycleGAN and 32% for GauGAN. Our approach is generalizable to a variety of GMs showing an improvement over prior work by an average precision of 10% averaged across 12 GMs. Our code is available at https://www.github.com/vishal3477/proactive_IMD.
Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images
Jun 15, 2021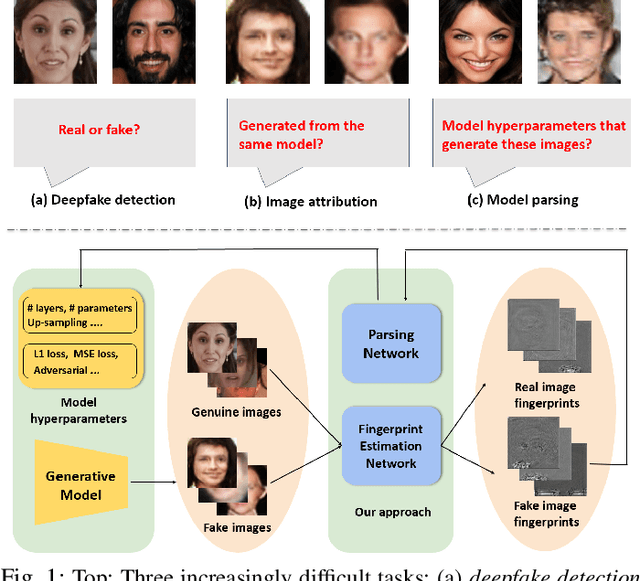


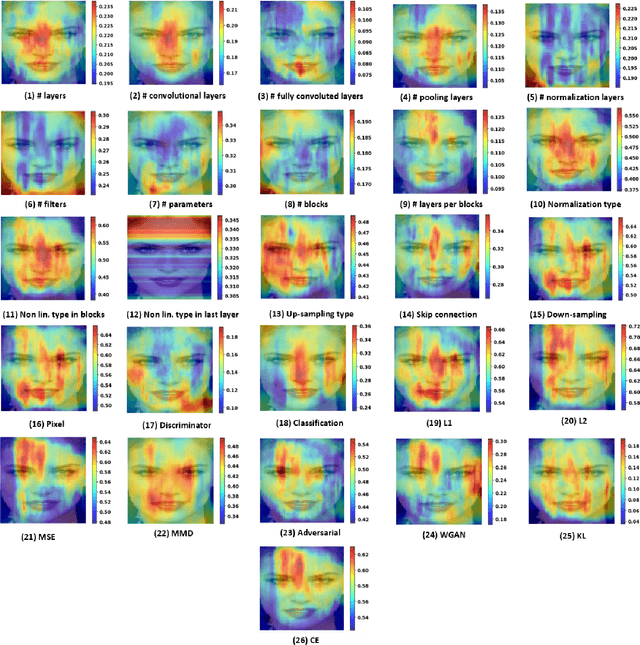
State-of-the-art (SOTA) Generative Models (GMs) can synthesize photo-realistic images that are hard for humans to distinguish from genuine photos. We propose to perform reverse engineering of GMs to infer the model hyperparameters from the images generated by these models. We define a novel problem, "model parsing", as estimating GM network architectures and training loss functions by examining their generated images -- a task seemingly impossible for human beings. To tackle this problem, we propose a framework with two components: a Fingerprint Estimation Network (FEN), which estimates a GM fingerprint from a generated image by training with four constraints to encourage the fingerprint to have desired properties, and a Parsing Network (PN), which predicts network architecture and loss functions from the estimated fingerprints. To evaluate our approach, we collect a fake image dataset with $100$K images generated by $100$ GMs. Extensive experiments show encouraging results in parsing the hyperparameters of the unseen models. Finally, our fingerprint estimation can be leveraged for deepfake detection and image attribution, as we show by reporting SOTA results on both the recent Celeb-DF and image attribution benchmarks.