 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSebra: Debiasing Through Self-Guided Bias Ranking
Jan 30, 2025



Ranking samples by fine-grained estimates of spuriosity (the degree to which spurious cues are present) has recently been shown to significantly benefit bias mitigation, over the traditional binary biased-\textit{vs}-unbiased partitioning of train sets. However, this spuriosity ranking comes with the requirement of human supervision. In this paper, we propose a debiasing framework based on our novel \ul{Se}lf-Guided \ul{B}ias \ul{Ra}nking (\emph{Sebra}), that mitigates biases (spurious correlations) via an automatic ranking of data points by spuriosity within their respective classes. Sebra leverages a key local symmetry in Empirical Risk Minimization (ERM) training -- the ease of learning a sample via ERM inversely correlates with its spuriousity; the fewer spurious correlations a sample exhibits, the harder it is to learn, and vice versa. However, globally across iterations, ERM tends to deviate from this symmetry. Sebra dynamically steers ERM to correct this deviation, facilitating the sequential learning of attributes in increasing order of difficulty, \ie, decreasing order of spuriosity. As a result, the sequence in which Sebra learns samples naturally provides spuriousity rankings. We use the resulting fine-grained bias characterization in a contrastive learning framework to mitigate biases from multiple sources. Extensive experiments show that Sebra consistently outperforms previous state-of-the-art unsupervised debiasing techniques across multiple standard benchmarks, including UrbanCars, BAR, CelebA, and ImageNet-1K. Code, pre-trained models, and training logs are available at https://kadarsh22.github.io/sebra_iclr25/.
DeNetDM: Debiasing by Network Depth Modulation
Mar 28, 2024When neural networks are trained on biased datasets, they tend to inadvertently learn spurious correlations, leading to challenges in achieving strong generalization and robustness. Current approaches to address such biases typically involve utilizing bias annotations, reweighting based on pseudo-bias labels, or enhancing diversity within bias-conflicting data points through augmentation techniques. We introduce DeNetDM, a novel debiasing method based on the observation that shallow neural networks prioritize learning core attributes, while deeper ones emphasize biases when tasked with acquiring distinct information. Using a training paradigm derived from Product of Experts, we create both biased and debiased branches with deep and shallow architectures and then distill knowledge to produce the target debiased model. Extensive experiments and analyses demonstrate that our approach outperforms current debiasing techniques, achieving a notable improvement of around 5% in three datasets, encompassing both synthetic and real-world data. Remarkably, DeNetDM accomplishes this without requiring annotations pertaining to bias labels or bias types, while still delivering performance on par with supervised counterparts. Furthermore, our approach effectively harnesses the diversity of bias-conflicting points within the data, surpassing previous methods and obviating the need for explicit augmentation-based methods to enhance the diversity of such bias-conflicting points. The source code will be available upon acceptance.
Self-supervised Enhancement of Latent Discovery in GANs
Dec 16, 2021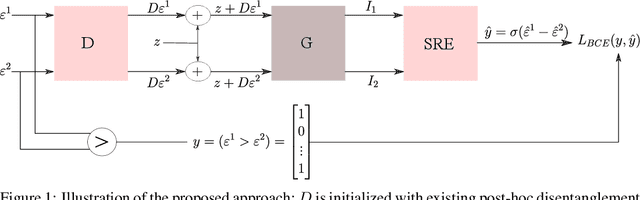


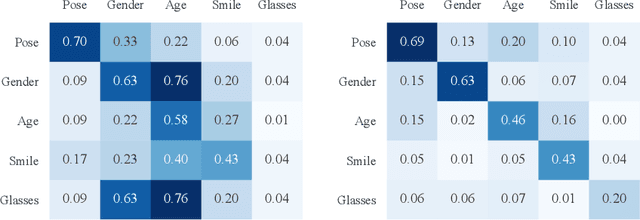
Several methods for discovering interpretable directions in the latent space of pre-trained GANs have been proposed. Latent semantics discovered by unsupervised methods are relatively less disentangled than supervised methods since they do not use pre-trained attribute classifiers. We propose Scale Ranking Estimator (SRE), which is trained using self-supervision. SRE enhances the disentanglement in directions obtained by existing unsupervised disentanglement techniques. These directions are updated to preserve the ordering of variation within each direction in latent space. Qualitative and quantitative evaluation of the discovered directions demonstrates that our proposed method significantly improves disentanglement in various datasets. We also show that the learned SRE can be used to perform Attribute-based image retrieval task without further training.