 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO3SLM: Open Weight, Open Data, and Open Vocabulary Sketch-Language Model
Nov 18, 2025While Large Vision Language Models (LVLMs) are increasingly deployed in real-world applications, their ability to interpret abstract visual inputs remains limited. Specifically, they struggle to comprehend hand-drawn sketches, a modality that offers an intuitive means of expressing concepts that are difficult to describe textually. We identify the primary bottleneck as the absence of a large-scale dataset that jointly models sketches, photorealistic images, and corresponding natural language instructions. To address this, we present two key contributions: (1) a new, large-scale dataset of image-sketch-instruction triplets designed to facilitate both pretraining and instruction tuning, and (2) O3SLM, an LVLM trained on this dataset. Comprehensive evaluations on multiple sketch-based tasks: (a) object localization, (b) counting, (c) image retrieval i.e., (SBIR and fine-grained SBIR), and (d) visual question answering (VQA); while incorporating the three existing sketch datasets, namely QuickDraw!, Sketchy, and Tu Berlin, along with our generated SketchVCL dataset, show that O3SLM achieves state-of-the-art performance, substantially outperforming existing LVLMs in sketch comprehension and reasoning.
LR0.FM: Low-Resolution Zero-shot Classification Benchmark For Foundation Models
Feb 07, 2025Visual-language foundation Models (FMs) exhibit remarkable zero-shot generalization across diverse tasks, largely attributed to extensive pre-training on largescale datasets. However, their robustness on low-resolution/pixelated (LR) images, a common challenge in real-world scenarios, remains underexplored. We introduce LR0.FM, a comprehensive benchmark evaluating the impact of low resolution on the zero-shot classification performance of 10 FM(s) across 66 backbones and 15 datasets. We propose a novel metric, Weighted Aggregated Robustness, to address the limitations of existing metrics and better evaluate model performance across resolutions and datasets. Our key findings show that: (i) model size positively correlates with robustness to resolution degradation, (ii) pre-training dataset quality is more important than its size, and (iii) fine-tuned and higher resolution models are less robust against LR. Our analysis further reveals that the model makes semantically reasonable predictions at LR, and the lack of fine-grained details in input adversely impacts the model's initial layers more than the deeper layers. We use these insights and introduce a simple strategy, LR-TK0, to enhance the robustness of models without compromising their pre-trained weights. We demonstrate the effectiveness of LR-TK0 for robustness against low-resolution across several datasets and its generalization capability across backbones and other approaches. Code is available at https://github.com/shyammarjit/LR0.FM
DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Models
Feb 28, 2024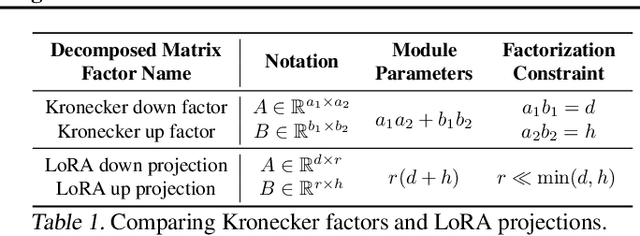



In the realm of subject-driven text-to-image (T2I) generative models, recent developments like DreamBooth and BLIP-Diffusion have led to impressive results yet encounter limitations due to their intensive fine-tuning demands and substantial parameter requirements. While the low-rank adaptation (LoRA) module within DreamBooth offers a reduction in trainable parameters, it introduces a pronounced sensitivity to hyperparameters, leading to a compromise between parameter efficiency and the quality of T2I personalized image synthesis. Addressing these constraints, we introduce \textbf{\textit{DiffuseKronA}}, a novel Kronecker product-based adaptation module that not only significantly reduces the parameter count by 35\% and 99.947\% compared to LoRA-DreamBooth and the original DreamBooth, respectively, but also enhances the quality of image synthesis. Crucially, \textit{DiffuseKronA} mitigates the issue of hyperparameter sensitivity, delivering consistent high-quality generations across a wide range of hyperparameters, thereby diminishing the necessity for extensive fine-tuning. Furthermore, a more controllable decomposition makes \textit{DiffuseKronA} more interpretable and even can achieve up to a 50\% reduction with results comparable to LoRA-Dreambooth. Evaluated against diverse and complex input images and text prompts, \textit{DiffuseKronA} consistently outperforms existing models, producing diverse images of higher quality with improved fidelity and a more accurate color distribution of objects, all the while upholding exceptional parameter efficiency, thus presenting a substantial advancement in the field of T2I generative modeling. Our project page, consisting of links to the code, and pre-trained checkpoints, is available at https://diffusekrona.github.io/.
CLIPDrawX: Primitive-based Explanations for Text Guided Sketch Synthesis
Dec 04, 2023



With the goal of understanding the visual concepts that CLIP associates with text prompts, we show that the latent space of CLIP can be visualized solely in terms of linear transformations on simple geometric primitives like circles and straight lines. Although existing approaches achieve this by sketch-synthesis-through-optimization, they do so on the space of B\'ezier curves, which exhibit a wastefully large set of structures that they can evolve into, as most of them are non-essential for generating meaningful sketches. We present CLIPDrawX, an algorithm that provides significantly better visualizations for CLIP text embeddings, using only simple primitive shapes like straight lines and circles. This constrains the set of possible outputs to linear transformations on these primitives, thereby exhibiting an inherently simpler mathematical form. The synthesis process of CLIPDrawX can be tracked end-to-end, with each visual concept being explained exclusively in terms of primitives. Implementation will be released upon acceptance. Project Page: $\href{https://clipdrawx.github.io/}{\text{https://clipdrawx.github.io/}}$.
Limited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders
Oct 31, 2023



Vision Transformers (ViTs) have become ubiquitous in computer vision. Despite their success, ViTs lack inductive biases, which can make it difficult to train them with limited data. To address this challenge, prior studies suggest training ViTs with self-supervised learning (SSL) and fine-tuning sequentially. However, we observe that jointly optimizing ViTs for the primary task and a Self-Supervised Auxiliary Task (SSAT) is surprisingly beneficial when the amount of training data is limited. We explore the appropriate SSL tasks that can be optimized alongside the primary task, the training schemes for these tasks, and the data scale at which they can be most effective. Our findings reveal that SSAT is a powerful technique that enables ViTs to leverage the unique characteristics of both the self-supervised and primary tasks, achieving better performance than typical ViTs pre-training with SSL and fine-tuning sequentially. Our experiments, conducted on 10 datasets, demonstrate that SSAT significantly improves ViT performance while reducing carbon footprint. We also confirm the effectiveness of SSAT in the video domain for deepfake detection, showcasing its generalizability. Our code is available at https://github.com/dominickrei/Limited-data-vits.