 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Data, Unlimited Potential: A Study on ViTs Augmented by Masked Autoencoders
Oct 31, 2023



Vision Transformers (ViTs) have become ubiquitous in computer vision. Despite their success, ViTs lack inductive biases, which can make it difficult to train them with limited data. To address this challenge, prior studies suggest training ViTs with self-supervised learning (SSL) and fine-tuning sequentially. However, we observe that jointly optimizing ViTs for the primary task and a Self-Supervised Auxiliary Task (SSAT) is surprisingly beneficial when the amount of training data is limited. We explore the appropriate SSL tasks that can be optimized alongside the primary task, the training schemes for these tasks, and the data scale at which they can be most effective. Our findings reveal that SSAT is a powerful technique that enables ViTs to leverage the unique characteristics of both the self-supervised and primary tasks, achieving better performance than typical ViTs pre-training with SSL and fine-tuning sequentially. Our experiments, conducted on 10 datasets, demonstrate that SSAT significantly improves ViT performance while reducing carbon footprint. We also confirm the effectiveness of SSAT in the video domain for deepfake detection, showcasing its generalizability. Our code is available at https://github.com/dominickrei/Limited-data-vits.
Convolutional Ensembling based Few-Shot Defect Detection Technique
Aug 05, 2022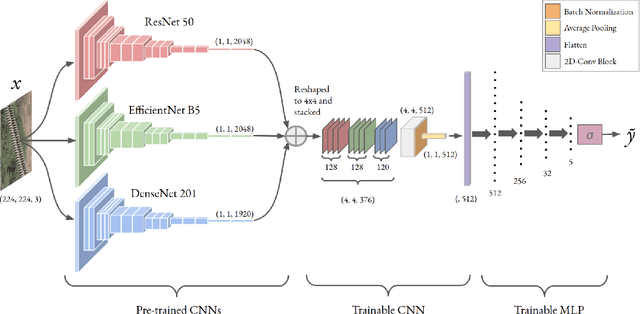

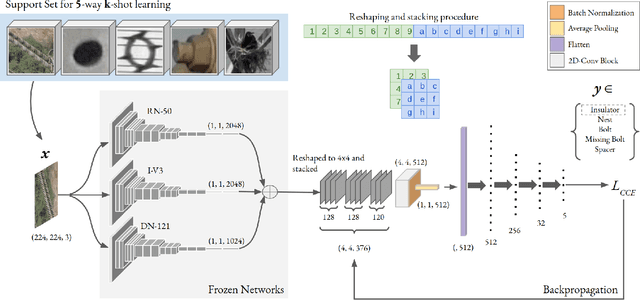
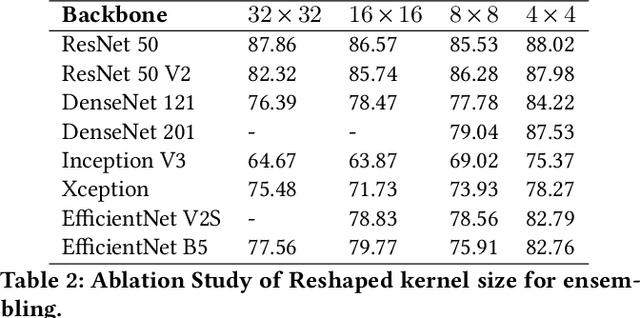
Over the past few years, there has been a significant improvement in the domain of few-shot learning. This learning paradigm has shown promising results for the challenging problem of anomaly detection, where the general task is to deal with heavy class imbalance. Our paper presents a new approach to few-shot classification, where we employ the knowledge-base of multiple pre-trained convolutional models that act as the backbone for our proposed few-shot framework. Our framework uses a novel ensembling technique for boosting the accuracy while drastically decreasing the total parameter count, thus paving the way for real-time implementation. We perform an extensive hyperparameter search using a power-line defect detection dataset and obtain an accuracy of 92.30% for the 5-way 5-shot task. Without further tuning, we evaluate our model on competing standards with the existing state-of-the-art methods and outperform them.