 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSPlan: Corrective Sequential Planning via Scene Graph Incremental Updates
Dec 11, 2025Large-scale Vision-Language Models (VLMs) exhibit impressive complex reasoning capabilities but remain largely unexplored in visual sequential planning, i.e., executing multi-step actions towards a goal. Additionally, practical sequential planning often involves non-optimal (erroneous) steps, challenging VLMs to detect and correct such steps. We propose Corrective Sequential Planning Benchmark (CoSPlan) to evaluate VLMs in error-prone, vision-based sequential planning tasks across 4 domains: maze navigation, block rearrangement, image reconstruction,and object reorganization. CoSPlan assesses two key abilities: Error Detection (identifying non-optimal action) and Step Completion (correcting and completing action sequences to reach the goal). Despite using state-of-the-art reasoning techniques such as Chain-of-Thought and Scene Graphs, VLMs (e.g. Intern-VLM and Qwen2) struggle on CoSPlan, failing to leverage contextual cues to reach goals. Addressing this, we propose a novel training-free method, Scene Graph Incremental updates (SGI), which introduces intermediate reasoning steps between the initial and goal states. SGI helps VLMs reason about sequences, yielding an average performance gain of 5.2%. In addition to enhancing reliability in corrective sequential planning, SGI generalizes to traditional planning tasks such as Plan-Bench and VQA.
Colors See Colors Ignore: Clothes Changing ReID with Color Disentanglement
Jul 09, 2025Clothes-Changing Re-Identification (CC-ReID) aims to recognize individuals across different locations and times, irrespective of clothing. Existing methods often rely on additional models or annotations to learn robust, clothing-invariant features, making them resource-intensive. In contrast, we explore the use of color - specifically foreground and background colors - as a lightweight, annotation-free proxy for mitigating appearance bias in ReID models. We propose Colors See, Colors Ignore (CSCI), an RGB-only method that leverages color information directly from raw images or video frames. CSCI efficiently captures color-related appearance bias ('Color See') while disentangling it from identity-relevant ReID features ('Color Ignore'). To achieve this, we introduce S2A self-attention, a novel self-attention to prevent information leak between color and identity cues within the feature space. Our analysis shows a strong correspondence between learned color embeddings and clothing attributes, validating color as an effective proxy when explicit clothing labels are unavailable. We demonstrate the effectiveness of CSCI on both image and video ReID with extensive experiments on four CC-ReID datasets. We improve the baseline by Top-1 2.9% on LTCC and 5.0% on PRCC for image-based ReID, and 1.0% on CCVID and 2.5% on MeVID for video-based ReID without relying on additional supervision. Our results highlight the potential of color as a cost-effective solution for addressing appearance bias in CC-ReID. Github: https://github.com/ppriyank/ICCV-CSCI-Person-ReID.
Coarse Attribute Prediction with Task Agnostic Distillation for Real World Clothes Changing ReID
May 19, 2025This work focuses on Clothes Changing Re-IDentification (CC-ReID) for the real world. Existing works perform well with high-quality (HQ) images, but struggle with low-quality (LQ) where we can have artifacts like pixelation, out-of-focus blur, and motion blur. These artifacts introduce noise to not only external biometric attributes (e.g. pose, body shape, etc.) but also corrupt the model's internal feature representation. Models usually cluster LQ image features together, making it difficult to distinguish between them, leading to incorrect matches. We propose a novel framework Robustness against Low-Quality (RLQ) to improve CC-ReID model on real-world data. RLQ relies on Coarse Attributes Prediction (CAP) and Task Agnostic Distillation (TAD) operating in alternate steps in a novel training mechanism. CAP enriches the model with external fine-grained attributes via coarse predictions, thereby reducing the effect of noisy inputs. On the other hand, TAD enhances the model's internal feature representation by bridging the gap between HQ and LQ features, via an external dataset through task-agnostic self-supervision and distillation. RLQ outperforms the existing approaches by 1.6%-2.9% Top-1 on real-world datasets like LaST, and DeepChange, while showing consistent improvement of 5.3%-6% Top-1 on PRCC with competitive performance on LTCC. *The code will be made public soon.*
LR0.FM: Low-Resolution Zero-shot Classification Benchmark For Foundation Models
Feb 07, 2025Visual-language foundation Models (FMs) exhibit remarkable zero-shot generalization across diverse tasks, largely attributed to extensive pre-training on largescale datasets. However, their robustness on low-resolution/pixelated (LR) images, a common challenge in real-world scenarios, remains underexplored. We introduce LR0.FM, a comprehensive benchmark evaluating the impact of low resolution on the zero-shot classification performance of 10 FM(s) across 66 backbones and 15 datasets. We propose a novel metric, Weighted Aggregated Robustness, to address the limitations of existing metrics and better evaluate model performance across resolutions and datasets. Our key findings show that: (i) model size positively correlates with robustness to resolution degradation, (ii) pre-training dataset quality is more important than its size, and (iii) fine-tuned and higher resolution models are less robust against LR. Our analysis further reveals that the model makes semantically reasonable predictions at LR, and the lack of fine-grained details in input adversely impacts the model's initial layers more than the deeper layers. We use these insights and introduce a simple strategy, LR-TK0, to enhance the robustness of models without compromising their pre-trained weights. We demonstrate the effectiveness of LR-TK0 for robustness against low-resolution across several datasets and its generalization capability across backbones and other approaches. Code is available at https://github.com/shyammarjit/LR0.FM
Local Learning on Transformers via Feature Reconstruction
Dec 29, 2022Transformers are becoming increasingly popular due to their superior performance over conventional convolutional neural networks(CNNs). However, transformers usually require a much larger amount of memory to train than CNNs, which prevents their application in many low resource settings. Local learning, which divides the network into several distinct modules and trains them individually, is a promising alternative to the end-to-end (E2E) training approach to reduce the amount of memory for training and to increase parallelism. This paper is the first to apply Local Learning on transformers for this purpose. The standard CNN-based local learning method, InfoPro [32], reconstructs the input images for each module in a CNN. However, reconstructing the entire image does not generalize well. In this paper, we propose a new mechanism for each local module, where instead of reconstructing the entire image, we reconstruct its input features, generated from previous modules. We evaluate our approach on 4 commonly used datasets and 3 commonly used decoder structures on Swin-Tiny. The experiments show that our approach outperforms InfoPro-Transformer, the InfoPro with Transfomer backbone we introduced, by at up to 0.58% on CIFAR-10, CIFAR-100, STL-10 and SVHN datasets, while using up to 12% less memory. Compared to the E2E approach, we require 36% less GPU memory when the network is divided into 2 modules and 45% less GPU memory when the network is divided into 4 modules.
Fine-Grained Re-Identification
Nov 26, 2020


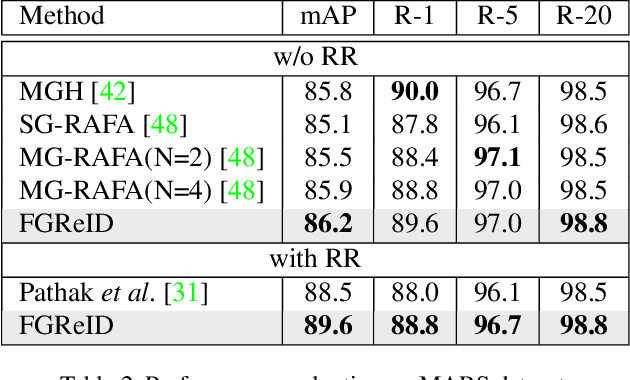
Research into the task of re-identification (ReID) is picking up momentum in computer vision for its many use cases and zero-shot learning nature. This paper proposes a computationally efficient fine-grained ReID model, FGReID, which is among the first models to unify image and video ReID while keeping the number of training parameters minimal. FGReID takes advantage of video-based pre-training and spatial feature attention to improve performance on both video and image ReID tasks. FGReID achieves state-of-the-art (SOTA) on MARS, iLIDS-VID, and PRID-2011 video person ReID benchmarks. Eliminating temporal pooling yields an image ReID model that surpasses SOTA on CUHK01 and Market1501 image person ReID benchmarks. The FGReID achieves near SOTA performance on the vehicle ReID dataset VeRi as well, demonstrating its ability to generalize. Additionally we do an ablation study analyzing the key features influencing model performance on ReID tasks. Finally, we discuss the moral dilemmas related to ReID tasks, including the potential for misuse. Code for this work is publicly available at https: //github.com/ppriyank/Fine-grained-ReIdentification.
Video Person Re-ID: Fantastic Techniques and Where to Find Them
Nov 21, 2019



The ability to identify the same person from multiple camera views without the explicit use of facial recognition is receiving commercial and academic interest. The current status-quo solutions are based on attention neural models. In this paper, we propose Attention and CL loss, which is a hybrid of center and Online Soft Mining (OSM) loss added to the attention loss on top of a temporal attention-based neural network. The proposed loss function applied with bag-of-tricks for training surpasses the state of the art on the common person Re-ID datasets, MARS and PRID 2011. Our source code is publicly available on github.