 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphKD: Exploring Knowledge Distillation Towards Document Object Detection with Structured Graph Creation
Paper and Code
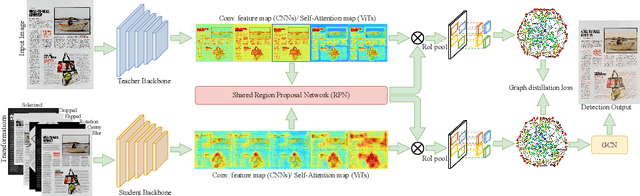



Object detection in documents is a key step to automate the structural elements identification process in a digital or scanned document through understanding the hierarchical structure and relationships between different elements. Large and complex models, while achieving high accuracy, can be computationally expensive and memory-intensive, making them impractical for deployment on resource constrained devices. Knowledge distillation allows us to create small and more efficient models that retain much of the performance of their larger counterparts. Here we present a graph-based knowledge distillation framework to correctly identify and localize the document objects in a document image. Here, we design a structured graph with nodes containing proposal-level features and edges representing the relationship between the different proposal regions. Also, to reduce text bias an adaptive node sampling strategy is designed to prune the weight distribution and put more weightage on non-text nodes. We encode the complete graph as a knowledge representation and transfer it from the teacher to the student through the proposed distillation loss by effectively capturing both local and global information concurrently. Extensive experimentation on competitive benchmarks demonstrates that the proposed framework outperforms the current state-of-the-art approaches. The code will be available at: https://github.com/ayanban011/GraphKD.