 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience with Single Domain Generalization in Real World Medical Imaging Deployments
Jan 22, 2026A desirable property of any deployed artificial intelligence is generalization across domains, i.e. data generation distribution under a specific acquisition condition. In medical imagining applications the most coveted property for effective deployment is Single Domain Generalization (SDG), which addresses the challenge of training a model on a single domain to ensure it generalizes well to unseen target domains. In multi-center studies, differences in scanners and imaging protocols introduce domain shifts that exacerbate variability in rare class characteristics. This paper presents our experience on SDG in real life deployment for two exemplary medical imaging case studies on seizure onset zone detection using fMRI data, and stress electrocardiogram based coronary artery detection. Utilizing the commonly used application of diabetic retinopathy, we first demonstrate that state-of-the-art SDG techniques fail to achieve generalized performance across data domains. We then develop a generic expert knowledge integrated deep learning technique DL+EKE and instantiate it for the DR application and show that DL+EKE outperforms SOTA SDG methods on DR. We then deploy instances of DL+EKE technique on the two real world examples of stress ECG and resting state (rs)-fMRI and discuss issues faced with SDG techniques.
Personalized Model-Based Design of Human Centric AI enabled CPS for Long term usage
Jan 08, 2026Human centric critical systems are increasingly involving artificial intelligence to enable knowledge extraction from sensor collected data. Examples include medical monitoring and control systems, gesture based human computer interaction systems, and autonomous cars. Such systems are intended to operate for a long term potentially for a lifetime in many scenarios such as closed loop blood glucose control for Type 1 diabetics, self-driving cars, and monitoting systems for stroke diagnosis, and rehabilitation. Long term operation of such AI enabled human centric applications can expose them to corner cases for which their operation is may be uncertain. This can be due to many reasons such as inherent flaws in the design, limited resources for testing, inherent computational limitations of the testing methodology, or unknown use cases resulting from human interaction with the system. Such untested corner cases or cases for which the system performance is uncertain can lead to violations in the safety, sustainability, and security requirements of the system. In this paper, we analyze the existing techniques for safety, sustainability, and security analysis of an AI enabled human centric control system and discuss their limitations for testing the system for long term use in practice. We then propose personalized model based solutions for potentially eliminating such limitations.
Detection of Deployment Operational Deviations for Safety and Security of AI-Enabled Human-Centric Cyber Physical Systems
Jan 08, 2026In recent years, Human-centric cyber-physical systems have increasingly involved artificial intelligence to enable knowledge extraction from sensor-collected data. Examples include medical monitoring and control systems, as well as autonomous cars. Such systems are intended to operate according to the protocols and guidelines for regular system operations. However, in many scenarios, such as closed-loop blood glucose control for Type 1 diabetics, self-driving cars, and monitoring systems for stroke diagnosis. The operations of such AI-enabled human-centric applications can expose them to cases for which their operational mode may be uncertain, for instance, resulting from the interactions with a human with the system. Such cases, in which the system is in uncertain conditions, can violate the system's safety and security requirements. This paper will discuss operational deviations that can lead these systems to operate in unknown conditions. We will then create a framework to evaluate different strategies for ensuring the safety and security of AI-enabled human-centric cyber-physical systems in operation deployment. Then, as an example, we show a personalized image-based novel technique for detecting the non-announcement of meals in closed-loop blood glucose control for Type 1 diabetics.
Accelerated Digital Twin Learning for Edge AI: A Comparison of FPGA and Mobile GPU
Dec 13, 2025Digital twins (DTs) can enable precision healthcare by continually learning a mathematical representation of patient-specific dynamics. However, mission critical healthcare applications require fast, resource-efficient DT learning, which is often infeasible with existing model recovery (MR) techniques due to their reliance on iterative solvers and high compute/memory demands. In this paper, we present a general DT learning framework that is amenable to acceleration on reconfigurable hardware such as FPGAs, enabling substantial speedup and energy efficiency. We compare our FPGA-based implementation with a multi-processing implementation in mobile GPU, which is a popular choice for AI in edge devices. Further, we compare both edge AI implementations with cloud GPU baseline. Specifically, our FPGA implementation achieves an 8.8x improvement in \text{performance-per-watt} for the MR task, a 28.5x reduction in DRAM footprint, and a 1.67x runtime speedup compared to cloud GPU baselines. On the other hand, mobile GPU achieves 2x better performance per watts but has 2x increase in runtime and 10x more DRAM footprint than FPGA. We show the usage of this technique in DT guided synthetic data generation for Type 1 Diabetes and proactive coronary artery disease detection.
STORM: Strategic Orchestration of Modalities for Rare Event Classification
Dec 03, 2024In domains such as biomedical, expert insights are crucial for selecting the most informative modalities for artificial intelligence (AI) methodologies. However, using all available modalities poses challenges, particularly in determining the impact of each modality on performance and optimizing their combinations for accurate classification. Traditional approaches resort to manual trial and error methods, lacking systematic frameworks for discerning the most relevant modalities. Moreover, although multi-modal learning enables the integration of information from diverse sources, utilizing all available modalities is often impractical and unnecessary. To address this, we introduce an entropy-based algorithm STORM to solve the modality selection problem for rare event. This algorithm systematically evaluates the information content of individual modalities and their combinations, identifying the most discriminative features essential for rare class classification tasks. Through seizure onset zone detection case study, we demonstrate the efficacy of our algorithm in enhancing classification performance. By selecting useful subset of modalities, our approach paves the way for more efficient AI-driven biomedical analyses, thereby advancing disease diagnosis in clinical settings.
Recovering implicit physics model under real-world constraints
Dec 03, 2024



Recovering a physics-driven model, i.e. a governing set of equations of the underlying dynamical systems, from the real-world data has been of recent interest. Most existing methods either operate on simulation data with unrealistically high sampling rates or require explicit measurements of all system variables, which is not amenable in real-world deployments. Moreover, they assume the timestamps of external perturbations to the physical system are known a priori, without uncertainty, implicitly discounting any sensor time-synchronization or human reporting errors. In this paper, we propose a novel liquid time constant neural network (LTC-NN) based architecture to recover underlying model of physical dynamics from real-world data. The automatic differentiation property of LTC-NN nodes overcomes problems associated with low sampling rates, the input dependent time constant in the forward pass of the hidden layer of LTC-NN nodes creates a massive search space of implicit physical dynamics, the physics model solver based data reconstruction loss guides the search for the correct set of implicit dynamics, and the use of the dropout regularization in the dense layer ensures extraction of the sparsest model. Further, to account for the perturbation timing error, we utilize dense layer nodes to search through input shifts that results in the lowest reconstruction loss. Experiments on four benchmark dynamical systems, three with simulation data and one with the real-world data show that the LTC-NN architecture is more accurate in recovering implicit physics model coefficients than the state-of-the-art sparse model recovery approaches. We also introduce four additional case studies (total eight) on real-life medical examples in simulation and with real-world clinical data to show effectiveness of our approach in recovering underlying model in practice.
* This paper is published in ECAI 2024, https://ebooks.iospress.nl/volumearticle/69651
CPS-LLM: Large Language Model based Safe Usage Plan Generator for Human-in-the-Loop Human-in-the-Plant Cyber-Physical System
May 19, 2024We explore the usage of large language models (LLM) in human-in-the-loop human-in-the-plant cyber-physical systems (CPS) to translate a high-level prompt into a personalized plan of actions, and subsequently convert that plan into a grounded inference of sequential decision-making automated by a real-world CPS controller to achieve a control goal. We show that it is relatively straightforward to contextualize an LLM so it can generate domain-specific plans. However, these plans may be infeasible for the physical system to execute or the plan may be unsafe for human users. To address this, we propose CPS-LLM, an LLM retrained using an instruction tuning framework, which ensures that generated plans not only align with the physical system dynamics of the CPS but are also safe for human users. The CPS-LLM consists of two innovative components: a) a liquid time constant neural network-based physical dynamics coefficient estimator that can derive coefficients of dynamical models with some unmeasured state variables; b) the model coefficients are then used to train an LLM with prompts embodied with traces from the dynamical system and the corresponding model coefficients. We show that when the CPS-LLM is integrated with a contextualized chatbot such as BARD it can generate feasible and safe plans to manage external events such as meals for automated insulin delivery systems used by Type 1 Diabetes subjects.
The Expert Knowledge combined with AI outperforms AI Alone in Seizure Onset Zone Localization using resting state fMRI
Dec 14, 2023We evaluated whether integration of expert guidance on seizure onset zone (SOZ) identification from resting state functional MRI (rs-fMRI) connectomics combined with deep learning (DL) techniques enhances the SOZ delineation in patients with refractory epilepsy (RE), compared to utilizing DL alone. Rs-fMRI were collected from 52 children with RE who had subsequently undergone ic-EEG and then, if indicated, surgery for seizure control (n = 25). The resting state functional connectomics data were previously independently classified by two expert epileptologists, as indicative of measurement noise, typical resting state network connectivity, or SOZ. An expert knowledge integrated deep network was trained on functional connectomics data to identify SOZ. Expert knowledge integrated with DL showed a SOZ localization accuracy of 84.8& and F1 score, harmonic mean of positive predictive value and sensitivity, of 91.7%. Conversely, a DL only model yielded an accuracy of less than 50% (F1 score 63%). Activations that initiate in gray matter, extend through white matter and end in vascular regions are seen as the most discriminative expert identified SOZ characteristics. Integration of expert knowledge of functional connectomics can not only enhance the performance of DL in localizing SOZ in RE, but also lead toward potentially useful explanations of prevalent co-activation patterns in SOZ. RE with surgical outcomes and pre-operative rs-fMRI studies can yield expert knowledge most salient for SOZ identification.
High Fidelity Fast Simulation of Human in the Loop Human in the Plant Systems
Sep 10, 2023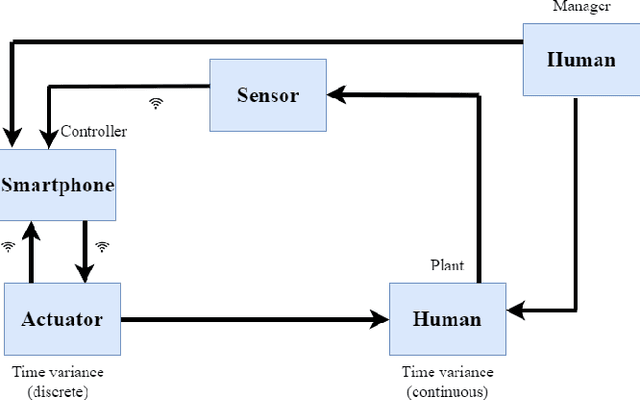

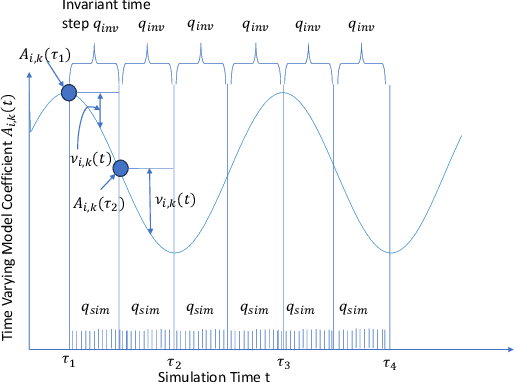
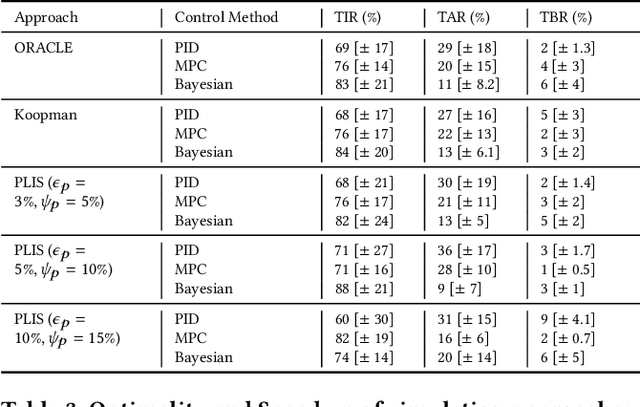
Non-linearities in simulation arise from the time variance in wireless mobile networks when integrated with human in the loop, human in the plant (HIL-HIP) physical systems under dynamic contexts, leading to simulation slowdown. Time variance is handled by deriving a series of piece wise linear time invariant simulations (PLIS) in intervals, which are then concatenated in time domain. In this paper, we conduct a formal analysis of the impact of discretizing time-varying components in wireless network-controlled HIL-HIP systems on simulation accuracy and speedup, and evaluate trade-offs with reliable guarantees. We develop an accurate simulation framework for an artificial pancreas wireless network system that controls blood glucose in Type 1 Diabetes patients with time varying properties such as physiological changes associated with psychological stress and meal patterns. PLIS approach achieves accurate simulation with greater than 2.1 times speedup than a non-linear system simulation for the given dataset.
Transfer: Cross Modality Knowledge Transfer using Adversarial Networks -- A Study on Gesture Recognition
Jun 26, 2023Knowledge transfer across sensing technology is a novel concept that has been recently explored in many application domains, including gesture-based human computer interaction. The main aim is to gather semantic or data driven information from a source technology to classify / recognize instances of unseen classes in the target technology. The primary challenge is the significant difference in dimensionality and distribution of feature sets between the source and the target technologies. In this paper, we propose TRANSFER, a generic framework for knowledge transfer between a source and a target technology. TRANSFER uses a language-based representation of a hand gesture, which captures a temporal combination of concepts such as handshape, location, and movement that are semantically related to the meaning of a word. By utilizing a pre-specified syntactic structure and tokenizer, TRANSFER segments a hand gesture into tokens and identifies individual components using a token recognizer. The tokenizer in this language-based recognition system abstracts the low-level technology-specific characteristics to the machine interface, enabling the design of a discriminator that learns technology-invariant features essential for recognition of gestures in both source and target technologies. We demonstrate the usage of TRANSFER for three different scenarios: a) transferring knowledge across technology by learning gesture models from video and recognizing gestures using WiFi, b) transferring knowledge from video to accelerometer, and d) transferring knowledge from accelerometer to WiFi signals.