 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIO : Mutual Information Optimization using Self-Supervised Binary Contrastive Learning
Paper and Code
Nov 24, 2021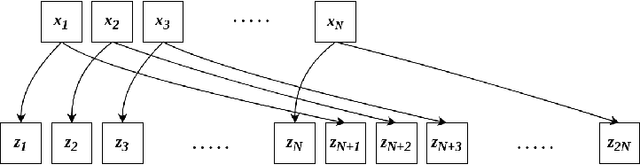
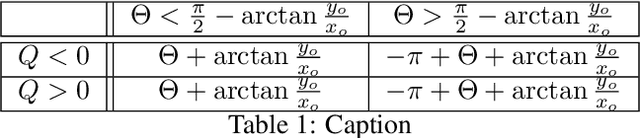
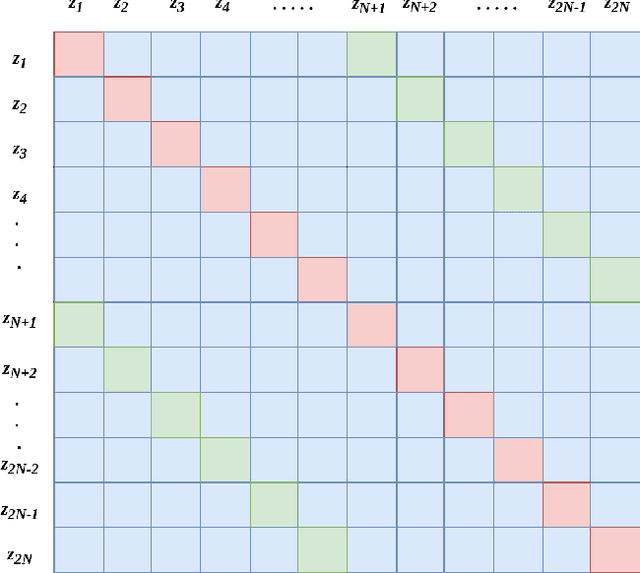
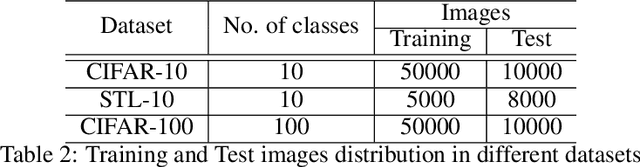
Self-supervised contrastive learning is one of the domains which has progressed rapidly over the last few years. Most of the state-of-the-art self-supervised algorithms use a large number of negative samples, momentum updates, specific architectural modifications, or extensive training to learn good representations. Such arrangements make the overall training process complex and challenging to realize analytically. In this paper, we propose a mutual information optimization based loss function for contrastive learning where we model contrastive learning into a binary classification problem to predict if a pair is positive or not. This formulation not only helps us to track the problem mathematically but also helps us to outperform existing algorithms. Unlike the existing methods that only maximize the mutual information in a positive pair, the proposed loss function optimizes the mutual information in both positive and negative pairs. We also present a mathematical expression for the parameter gradients flowing into the projector and the displacement of the feature vectors in the feature space. This helps us to get a mathematical insight into the working principle of contrastive learning. An additive $L_2$ regularizer is also used to prevent diverging of the feature vectors and to improve performance. The proposed method outperforms the state-of-the-art algorithms on benchmark datasets like STL-10, CIFAR-10, CIFAR-100. After only 250 epochs of pre-training, the proposed model achieves the best accuracy of 85.44\%, 60.75\%, 56.81\% on CIFAR-10, STL-10, CIFAR-100 datasets, respectively.