 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePara-active learning
Paper and Code
Oct 30, 2013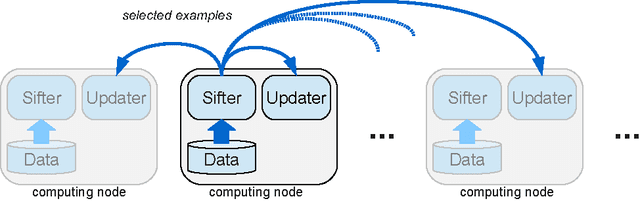

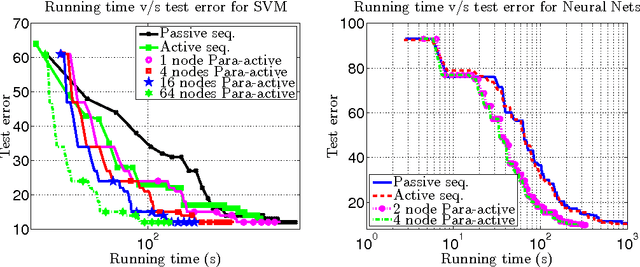
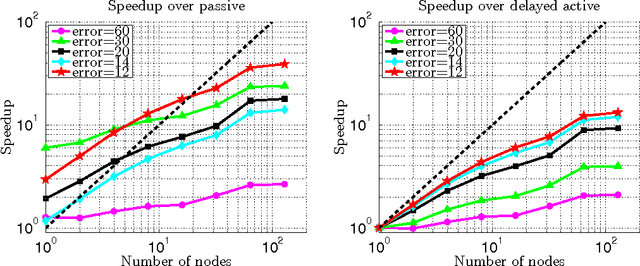
Training examples are not all equally informative. Active learning strategies leverage this observation in order to massively reduce the number of examples that need to be labeled. We leverage the same observation to build a generic strategy for parallelizing learning algorithms. This strategy is effective because the search for informative examples is highly parallelizable and because we show that its performance does not deteriorate when the sifting process relies on a slightly outdated model. Parallel active learning is particularly attractive to train nonlinear models with non-linear representations because there are few practical parallel learning algorithms for such models. We report preliminary experiments using both kernel SVMs and SGD-trained neural networks.