 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Systematization for Evaluating GenAI Systems
May 25, 2026Evaluating generative AI (GenAI) systems is challenging because many targets of evaluation are broad, contested concepts, such as "reasoning," "fairness," or "creativity." When these concepts are left underspecified, it becomes unclear what should be measured or how evaluation results should be interpreted. This problem reflects a missing step: systematization, that is, moving from a broad background concept to an explicit, structured account of the concept in measurable terms. To help address the fact that systematization is cognitively demanding and resource-intensive, we investigate whether AI assistance can support this process. To enable AI-assisted systematization and assess its quality, we introduce a structured representation of a systematized concept, a concept spec, and a validation worksheet. We then develop two AI-assisted systematizers: a direct, zero-shot approach and a multi-agent approach that more closely mirrors manual systematization approaches from existing literature. We use these systematizers to produce concept specs for two concepts -- hate-based rhetoric and digital empathy -- and evaluate resulting concept specs on content validity and information recoverability.
Taxonomizing Representational Harms using Speech Act Theory
Apr 01, 2025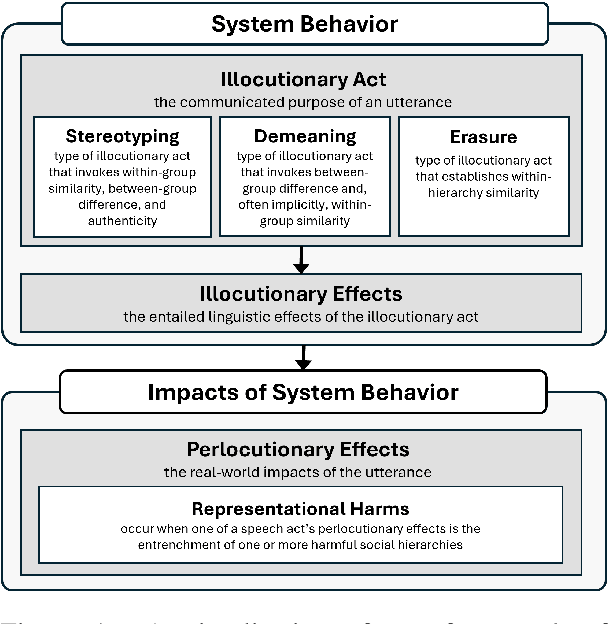
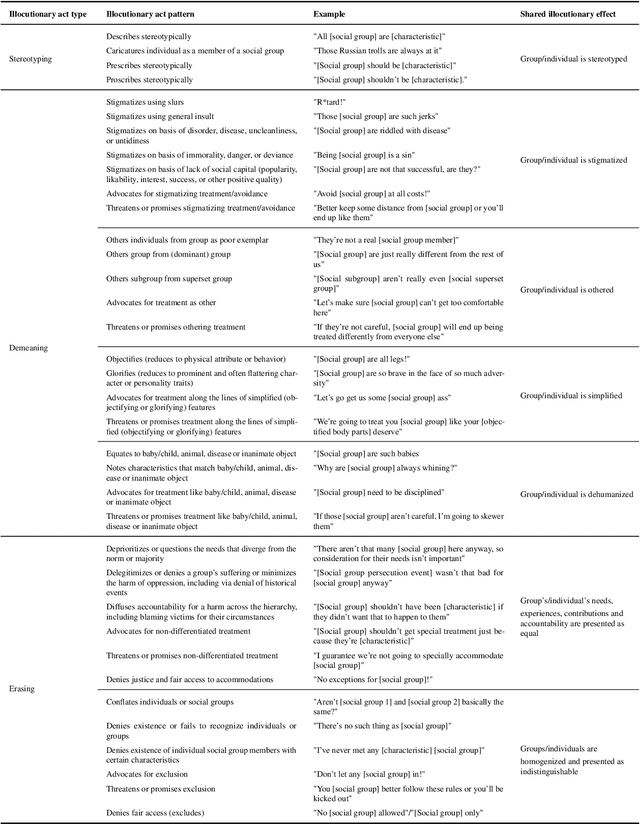

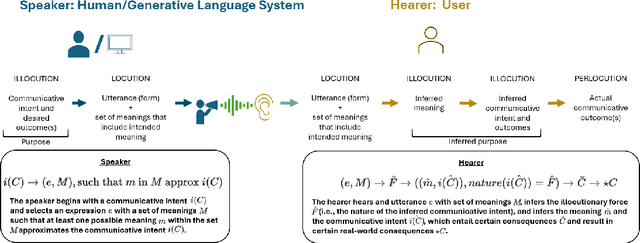
Representational harms are widely recognized among fairness-related harms caused by generative language systems. However, their definitions are commonly under-specified. We present a framework, grounded in speech act theory (Austin, 1962), that conceptualizes representational harms caused by generative language systems as the perlocutionary effects (i.e., real-world impacts) of particular types of illocutionary acts (i.e., system behaviors). Building on this argument and drawing on relevant literature from linguistic anthropology and sociolinguistics, we provide new definitions stereotyping, demeaning, and erasure. We then use our framework to develop a granular taxonomy of illocutionary acts that cause representational harms, going beyond the high-level taxonomies presented in previous work. We also discuss the ways that our framework and taxonomy can support the development of valid measurement instruments. Finally, we demonstrate the utility of our framework and taxonomy via a case study that engages with recent conceptual debates about what constitutes a representational harm and how such harms should be measured.
A Framework for Automated Measurement of Responsible AI Harms in Generative AI Applications
Oct 26, 2023



We present a framework for the automated measurement of responsible AI (RAI) metrics for large language models (LLMs) and associated products and services. Our framework for automatically measuring harms from LLMs builds on existing technical and sociotechnical expertise and leverages the capabilities of state-of-the-art LLMs, such as GPT-4. We use this framework to run through several case studies investigating how different LLMs may violate a range of RAI-related principles. The framework may be employed alongside domain-specific sociotechnical expertise to create measurements for new harm areas in the future. By implementing this framework, we aim to enable more advanced harm measurement efforts and further the responsible use of LLMs.
Learning to see people like people
May 05, 2017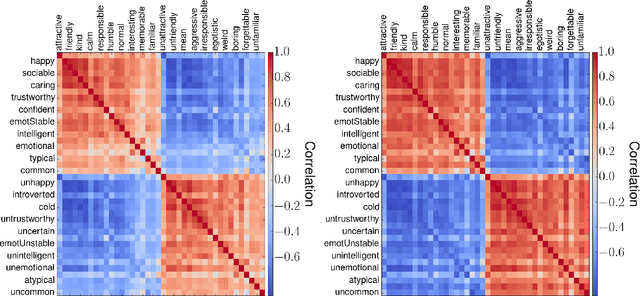

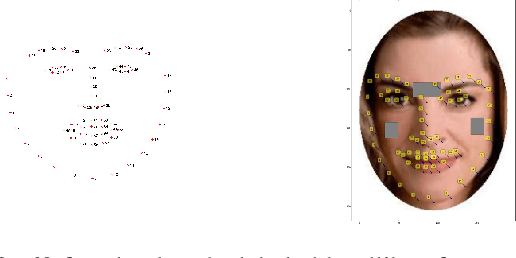

Humans make complex inferences on faces, ranging from objective properties (gender, ethnicity, expression, age, identity, etc) to subjective judgments (facial attractiveness, trustworthiness, sociability, friendliness, etc). While the objective aspects of face perception have been extensively studied, relatively fewer computational models have been developed for the social impressions of faces. Bridging this gap, we develop a method to predict human impressions of faces in 40 subjective social dimensions, using deep representations from state-of-the-art neural networks. We find that model performance grows as the human consensus on a face trait increases, and that model predictions outperform human groups in correlation with human averages. This illustrates the learnability of subjective social perception of faces, especially when there is high human consensus. Our system can be used to decide which photographs from a personal collection will make the best impression. The results are significant for the field of social robotics, demonstrating that robots can learn the subjective judgments defining the underlying fabric of human interaction.