 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomizing Representational Harms using Speech Act Theory
Apr 01, 2025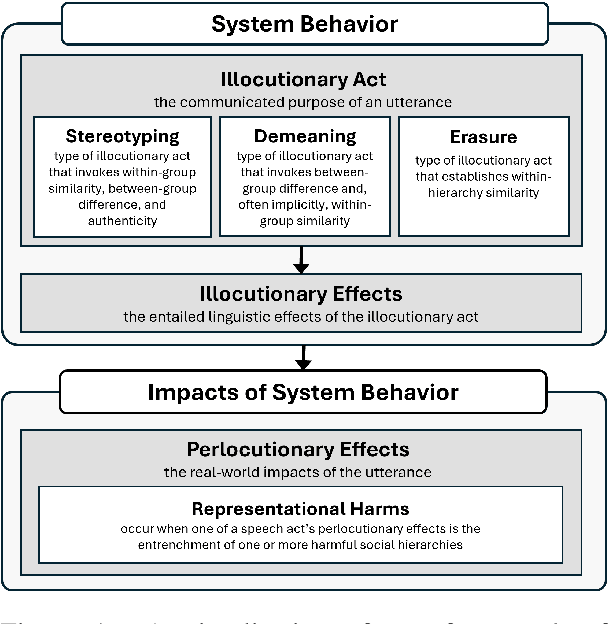
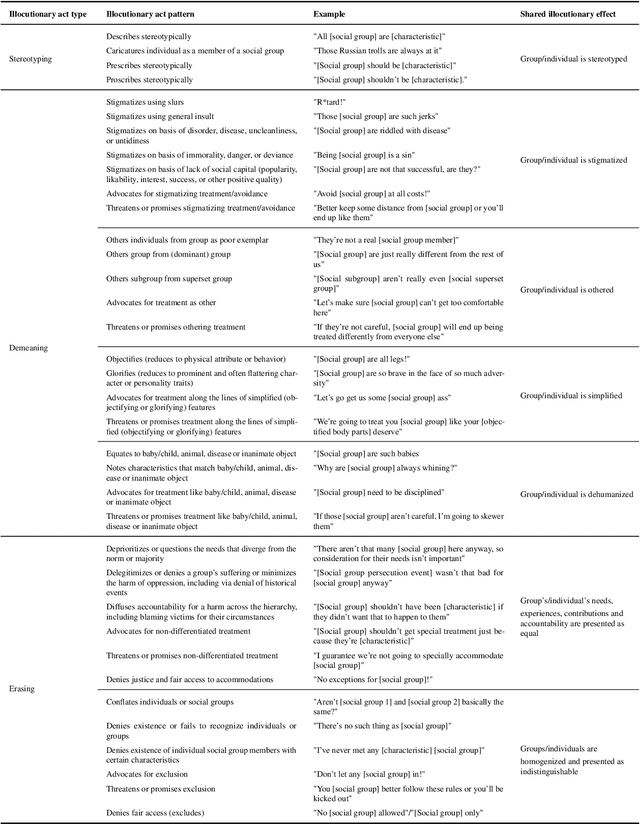

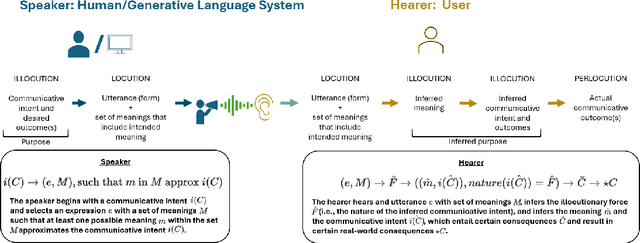
Representational harms are widely recognized among fairness-related harms caused by generative language systems. However, their definitions are commonly under-specified. We present a framework, grounded in speech act theory (Austin, 1962), that conceptualizes representational harms caused by generative language systems as the perlocutionary effects (i.e., real-world impacts) of particular types of illocutionary acts (i.e., system behaviors). Building on this argument and drawing on relevant literature from linguistic anthropology and sociolinguistics, we provide new definitions stereotyping, demeaning, and erasure. We then use our framework to develop a granular taxonomy of illocutionary acts that cause representational harms, going beyond the high-level taxonomies presented in previous work. We also discuss the ways that our framework and taxonomy can support the development of valid measurement instruments. Finally, we demonstrate the utility of our framework and taxonomy via a case study that engages with recent conceptual debates about what constitutes a representational harm and how such harms should be measured.
Keeping Humans in the Loop: Human-Centered Automated Annotation with Generative AI
Sep 14, 2024



Automated text annotation is a compelling use case for generative large language models (LLMs) in social media research. Recent work suggests that LLMs can achieve strong performance on annotation tasks; however, these studies evaluate LLMs on a small number of tasks and likely suffer from contamination due to a reliance on public benchmark datasets. Here, we test a human-centered framework for responsibly evaluating artificial intelligence tools used in automated annotation. We use GPT-4 to replicate 27 annotation tasks across 11 password-protected datasets from recently published computational social science articles in high-impact journals. For each task, we compare GPT-4 annotations against human-annotated ground-truth labels and against annotations from separate supervised classification models fine-tuned on human-generated labels. Although the quality of LLM labels is generally high, we find significant variation in LLM performance across tasks, even within datasets. Our findings underscore the importance of a human-centered workflow and careful evaluation standards: Automated annotations significantly diverge from human judgment in numerous scenarios, despite various optimization strategies such as prompt tuning. Grounding automated annotation in validation labels generated by humans is essential for responsible evaluation.
Knowledge Distillation in Automated Annotation: Supervised Text Classification with LLM-Generated Training Labels
Jun 25, 2024Computational social science (CSS) practitioners often rely on human-labeled data to fine-tune supervised text classifiers. We assess the potential for researchers to augment or replace human-generated training data with surrogate training labels from generative large language models (LLMs). We introduce a recommended workflow and test this LLM application by replicating 14 classification tasks and measuring performance. We employ a novel corpus of English-language text classification data sets from recent CSS articles in high-impact journals. Because these data sets are stored in password-protected archives, our analyses are less prone to issues of contamination. For each task, we compare supervised classifiers fine-tuned using GPT-4 labels against classifiers fine-tuned with human annotations and against labels from GPT-4 and Mistral-7B with few-shot in-context learning. Our findings indicate that supervised classification models fine-tuned on LLM-generated labels perform comparably to models fine-tuned with labels from human annotators. Fine-tuning models using LLM-generated labels can be a fast, efficient and cost-effective method of building supervised text classifiers.
Automated Annotation with Generative AI Requires Validation
May 31, 2023


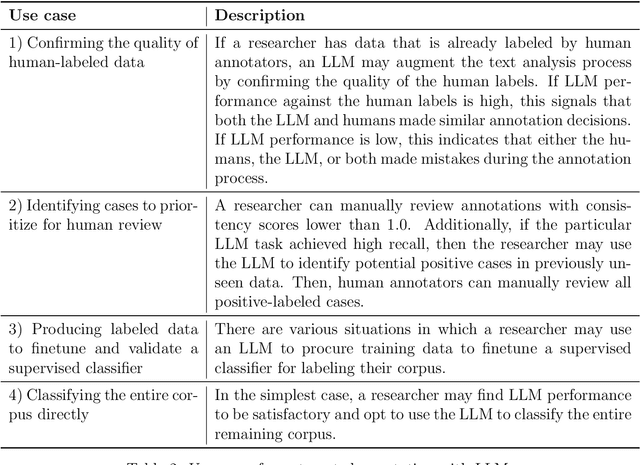
Generative large language models (LLMs) can be a powerful tool for augmenting text annotation procedures, but their performance varies across annotation tasks due to prompt quality, text data idiosyncrasies, and conceptual difficulty. Because these challenges will persist even as LLM technology improves, we argue that any automated annotation process using an LLM must validate the LLM's performance against labels generated by humans. To this end, we outline a workflow to harness the annotation potential of LLMs in a principled, efficient way. Using GPT-4, we validate this approach by replicating 27 annotation tasks across 11 datasets from recent social science articles in high-impact journals. We find that LLM performance for text annotation is promising but highly contingent on both the dataset and the type of annotation task, which reinforces the necessity to validate on a task-by-task basis. We make available easy-to-use software designed to implement our workflow and streamline the deployment of LLMs for automated annotation.