 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical Learning in Deep Asymmetric Recurrent Neural Networks
Sep 05, 2025



We show that asymmetric deep recurrent neural networks, enhanced with additional sparse excitatory couplings, give rise to an exponentially large, dense accessible manifold of internal representations which can be found by different algorithms, including simple iterative dynamics. Building on the geometrical properties of the stable configurations, we propose a distributed learning scheme in which input-output associations emerge naturally from the recurrent dynamics, without any need of gradient evaluation. A critical feature enabling the learning process is the stability of the configurations reached at convergence, even after removal of the supervisory output signal. Extensive simulations demonstrate that this approach performs competitively on standard AI benchmarks. The model can be generalized in multiple directions, both computational and biological, potentially contributing to narrowing the gap between AI and computational neuroscience.
Typical and atypical solutions in non-convex neural networks with discrete and continuous weights
Apr 26, 2023



We study the binary and continuous negative-margin perceptrons as simple non-convex neural network models learning random rules and associations. We analyze the geometry of the landscape of solutions in both models and find important similarities and differences. Both models exhibit subdominant minimizers which are extremely flat and wide. These minimizers coexist with a background of dominant solutions which are composed by an exponential number of algorithmically inaccessible small clusters for the binary case (the frozen 1-RSB phase) or a hierarchical structure of clusters of different sizes for the spherical case (the full RSB phase). In both cases, when a certain threshold in constraint density is crossed, the local entropy of the wide flat minima becomes non-monotonic, indicating a break-up of the space of robust solutions into disconnected components. This has a strong impact on the behavior of algorithms in binary models, which cannot access the remaining isolated clusters. For the spherical case the behaviour is different, since even beyond the disappearance of the wide flat minima the remaining solutions are shown to always be surrounded by a large number of other solutions at any distance, up to capacity. Indeed, we exhibit numerical evidence that algorithms seem to find solutions up to the SAT/UNSAT transition, that we compute here using an 1RSB approximation. For both models, the generalization performance as a learning device is shown to be greatly improved by the existence of wide flat minimizers even when trained in the highly underconstrained regime of very negative margins.
Deep Networks on Toroids: Removing Symmetries Reveals the Structure of Flat Regions in the Landscape Geometry
Feb 07, 2022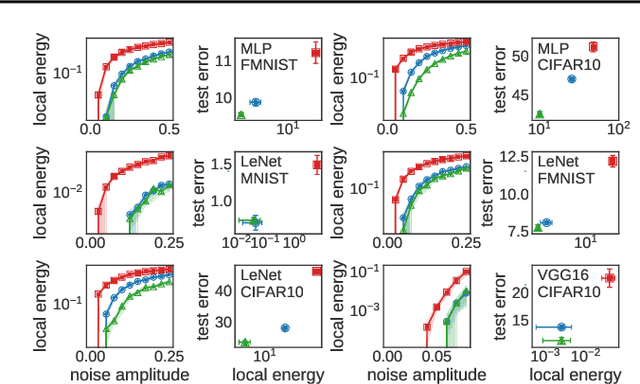
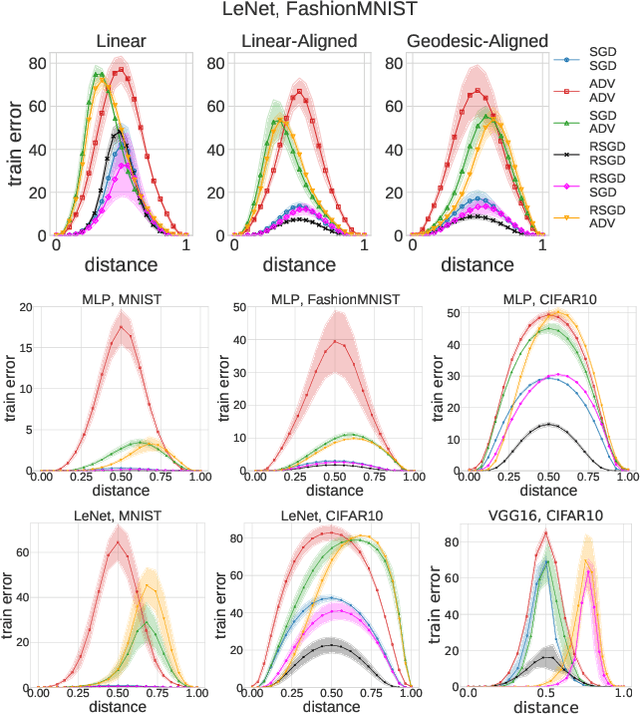
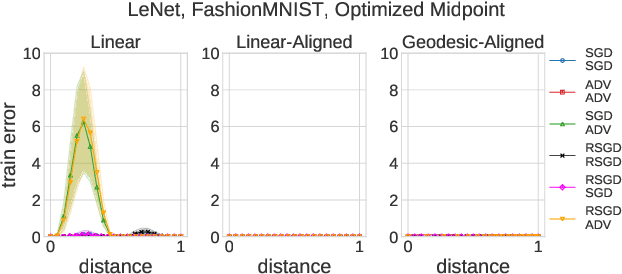
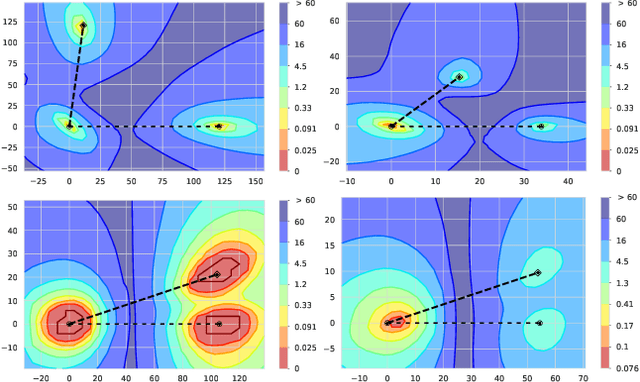
We systematize the approach to the investigation of deep neural network landscapes by basing it on the geometry of the space of implemented functions rather than the space of parameters. Grouping classifiers into equivalence classes, we develop a standardized parameterization in which all symmetries are removed, resulting in a toroidal topology. On this space, we explore the error landscape rather than the loss. This lets us derive a meaningful notion of the flatness of minimizers and of the geodesic paths connecting them. Using different optimization algorithms that sample minimizers with different flatness we study the mode connectivity and other characteristics. Testing a variety of state-of-the-art architectures and benchmark datasets, we confirm the correlation between flatness and generalization performance; we further show that in function space flatter minima are closer to each other and that the barriers along the geodesics connecting them are small. We also find that minimizers found by variants of gradient descent can be connected by zero-error paths with a single bend. We observe similar qualitative results in neural networks with binary weights and activations, providing one of the first results concerning the connectivity in this setting. Our results hinge on symmetry removal, and are in remarkable agreement with the rich phenomenology described by some recent analytical studies performed on simple shallow models.
Quantum Approximate Optimization Algorithm applied to the binary perceptron
Dec 19, 2021
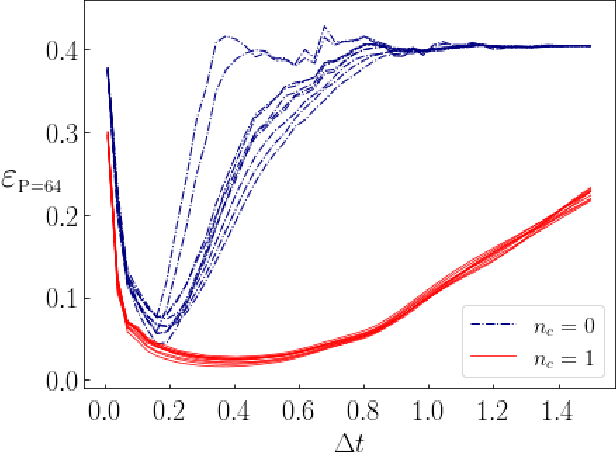
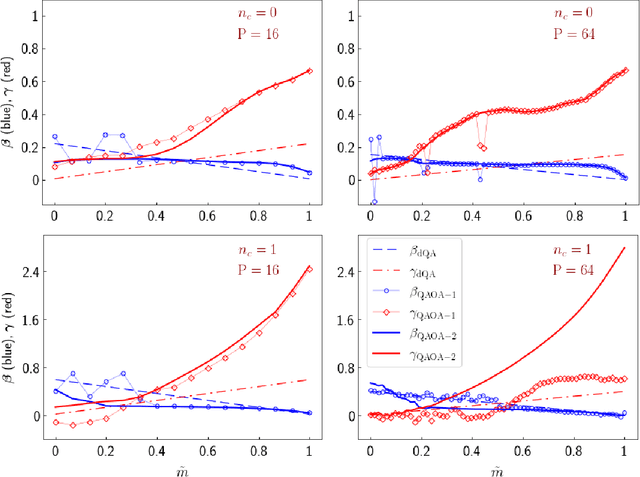
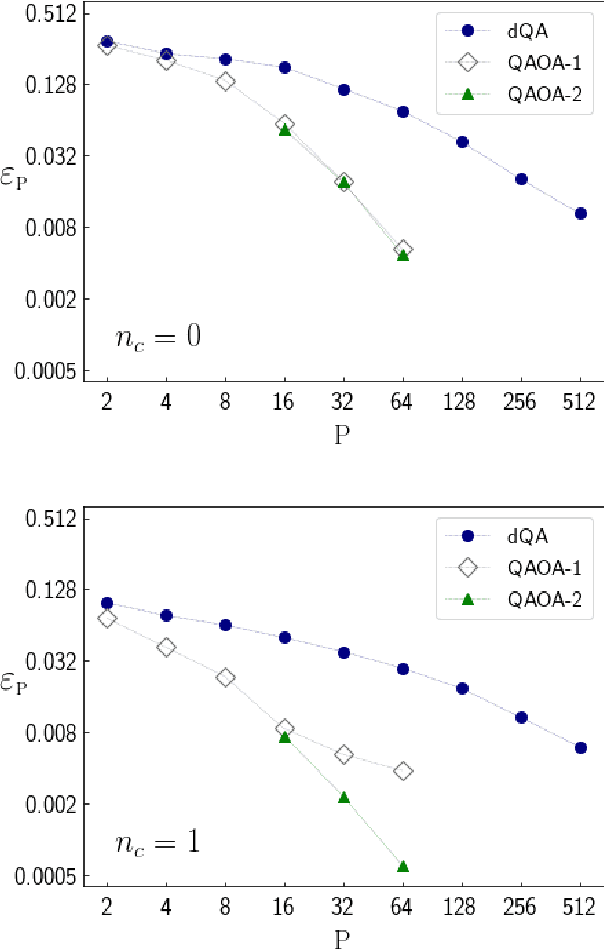
We apply digitized Quantum Annealing (QA) and Quantum Approximate Optimization Algorithm (QAOA) to a paradigmatic task of supervised learning in artificial neural networks: the optimization of synaptic weights for the binary perceptron. At variance with the usual QAOA applications to MaxCut, or to quantum spin-chains ground state preparation, the classical Hamiltonian is characterized by highly non-local multi-spin interactions. Yet, we provide evidence for the existence of optimal smooth solutions for the QAOA parameters, which are transferable among typical instances of the same problem, and we prove numerically an enhanced performance of QAOA over traditional QA. We also investigate on the role of the QAOA optimization landscape geometry in this problem, showing that the detrimental effect of a gap-closing transition encountered in QA is also negatively affecting the performance of our implementation of QAOA.
Deep learning via message passing algorithms based on belief propagation
Oct 27, 2021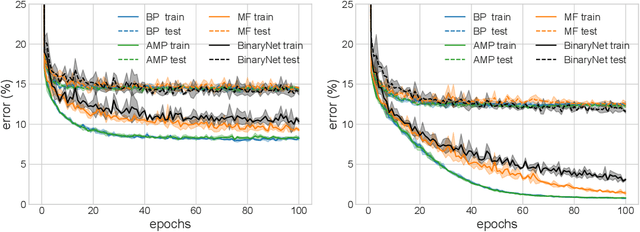
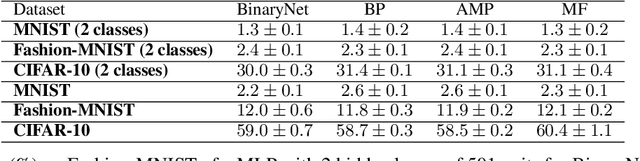
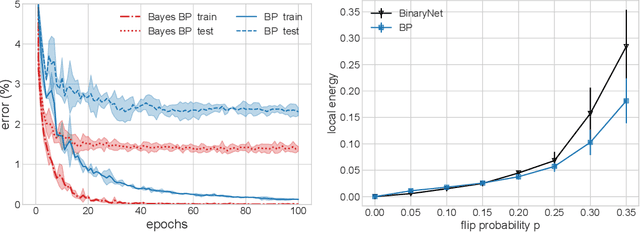

Message-passing algorithms based on the Belief Propagation (BP) equations constitute a well-known distributed computational scheme. It is exact on tree-like graphical models and has also proven to be effective in many problems defined on graphs with loops (from inference to optimization, from signal processing to clustering). The BP-based scheme is fundamentally different from stochastic gradient descent (SGD), on which the current success of deep networks is based. In this paper, we present and adapt to mini-batch training on GPUs a family of BP-based message-passing algorithms with a reinforcement field that biases distributions towards locally entropic solutions. These algorithms are capable of training multi-layer neural networks with discrete weights and activations with performance comparable to SGD-inspired heuristics (BinaryNet) and are naturally well-adapted to continual learning. Furthermore, using these algorithms to estimate the marginals of the weights allows us to make approximate Bayesian predictions that have higher accuracy than point-wise solutions.
Learning through atypical ''phase transitions'' in overparameterized neural networks
Oct 01, 2021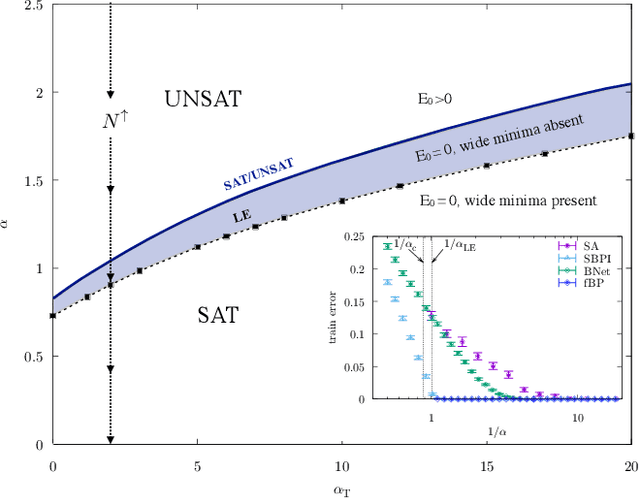
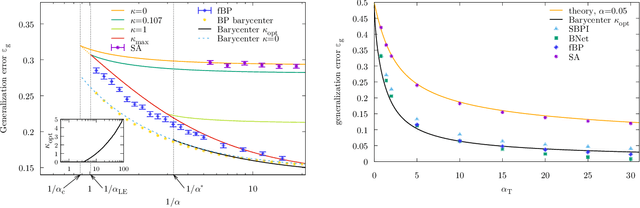

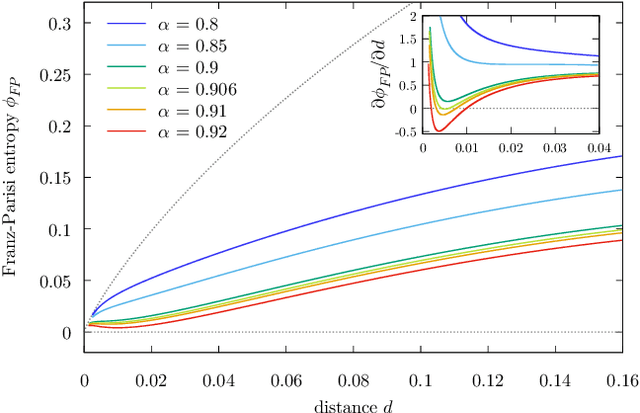
Current deep neural networks are highly overparameterized (up to billions of connection weights) and nonlinear. Yet they can fit data almost perfectly through variants of gradient descent algorithms and achieve unexpected levels of prediction accuracy without overfitting. These are formidable results that escape the bias-variance predictions of statistical learning and pose conceptual challenges for non-convex optimization. In this paper, we use methods from statistical physics of disordered systems to analytically study the computational fallout of overparameterization in nonconvex neural network models. As the number of connection weights increases, we follow the changes of the geometrical structure of different minima of the error loss function and relate them to learning and generalisation performance. We find that there exist a gap between the SAT/UNSAT interpolation transition where solutions begin to exist and the point where algorithms start to find solutions, i.e. where accessible solutions appear. This second phase transition coincides with the discontinuous appearance of atypical solutions that are locally extremely entropic, i.e., flat regions of the weight space that are particularly solution-dense and have good generalization properties. Although exponentially rare compared to typical solutions (which are narrower and extremely difficult to sample), entropic solutions are accessible to the algorithms used in learning. We can characterize the generalization error of different solutions and optimize the Bayesian prediction, for data generated from a structurally different network. Numerical tests on observables suggested by the theory confirm that the scenario extends to realistic deep networks.
Unveiling the structure of wide flat minima in neural networks
Jul 02, 2021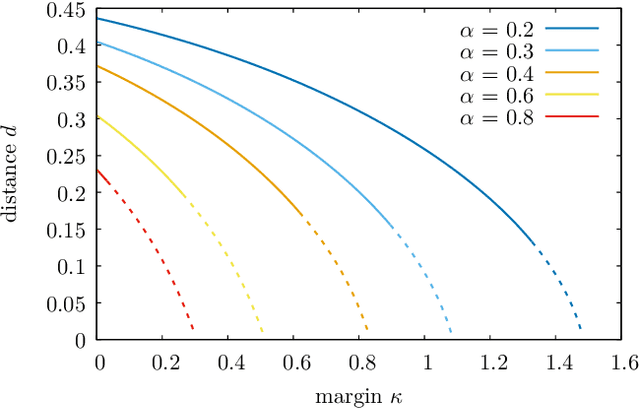
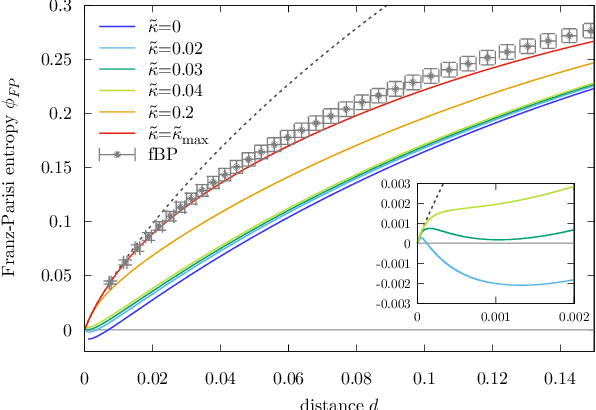
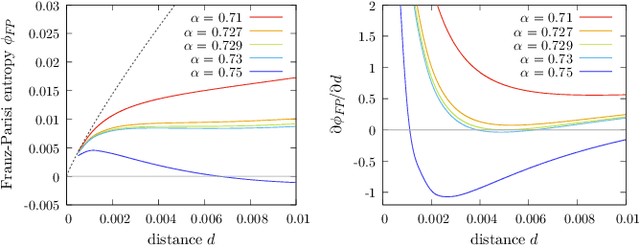
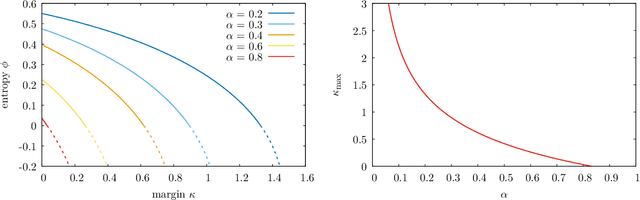
The success of deep learning has revealed the application potential of neural networks across the sciences and opened up fundamental theoretical problems. In particular, the fact that learning algorithms based on simple variants of gradient methods are able to find near-optimal minima of highly nonconvex loss functions is an unexpected feature of neural networks which needs to be understood in depth. Such algorithms are able to fit the data almost perfectly, even in the presence of noise, and yet they have excellent predictive capabilities. Several empirical results have shown a reproducible correlation between the so-called flatness of the minima achieved by the algorithms and the generalization performance. At the same time, statistical physics results have shown that in nonconvex networks a multitude of narrow minima may coexist with a much smaller number of wide flat minima, which generalize well. Here we show that wide flat minima arise from the coalescence of minima that correspond to high-margin classifications. Despite being exponentially rare compared to zero-margin solutions, high-margin minima tend to concentrate in particular regions. These minima are in turn surrounded by other solutions of smaller and smaller margin, leading to dense regions of solutions over long distances. Our analysis also provides an alternative analytical method for estimating when flat minima appear and when algorithms begin to find solutions, as the number of model parameters varies.
Wide flat minima and optimal generalization in classifying high-dimensional Gaussian mixtures
Oct 27, 2020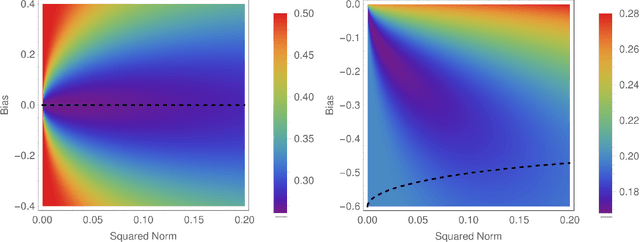

We analyze the connection between minimizers with good generalizing properties and high local entropy regions of a threshold-linear classifier in Gaussian mixtures with the mean squared error loss function. We show that there exist configurations that achieve the Bayes-optimal generalization error, even in the case of unbalanced clusters. We explore analytically the error-counting loss landscape in the vicinity of a Bayes-optimal solution, and show that the closer we get to such configurations, the higher the local entropy, implying that the Bayes-optimal solution lays inside a wide flat region. We also consider the algorithmically relevant case of targeting wide flat minima of the (differentiable) mean squared error loss. Our analytical and numerical results show not only that in the balanced case the dependence on the norm of the weights is mild, but also, in the unbalanced case, that the performances can be improved.
Entropic gradient descent algorithms and wide flat minima
Jun 14, 2020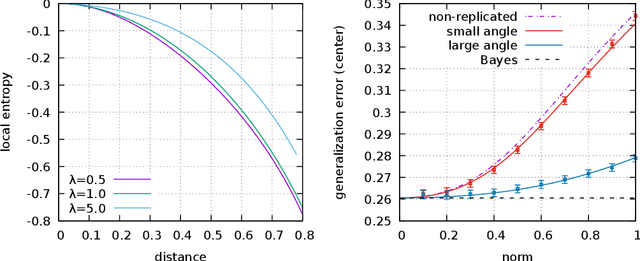
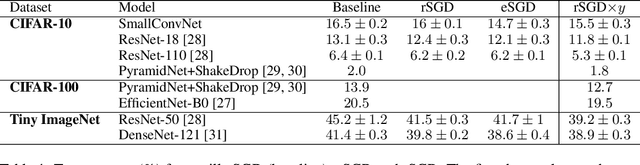

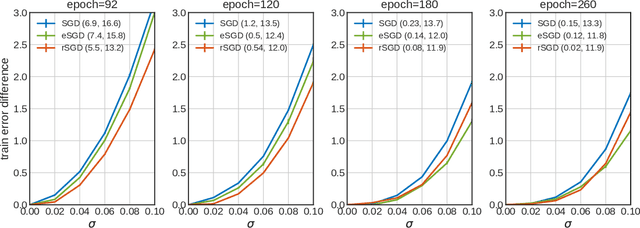
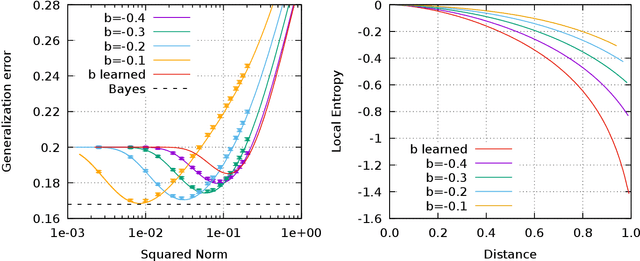
The properties of flat minima in the empirical risk landscape of neural networks have been debated for some time. Increasing evidence suggests they possess better generalization capabilities with respect to sharp ones. First, we discuss Gaussian mixture classification models and show analytically that there exist Bayes optimal pointwise estimators which correspond to minimizers belonging to wide flat regions. These estimators can be found by applying maximum flatness algorithms either directly on the classifier (which is norm independent) or on the differentiable loss function used in learning. Next, we extend the analysis to the deep learning scenario by extensive numerical validations. Using two algorithms, Entropy-SGD and Replicated-SGD, that explicitly include in the optimization objective a non-local flatness measure known as local entropy, we consistently improve the generalization error for common architectures (e.g. ResNet, EfficientNet). An easy to compute flatness measure shows a clear correlation with test accuracy.
Clustering of solutions in the symmetric binary perceptron
Nov 18, 2019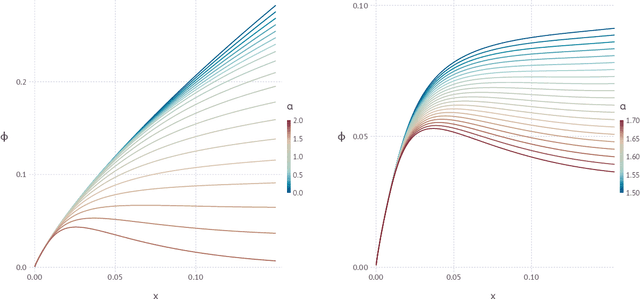
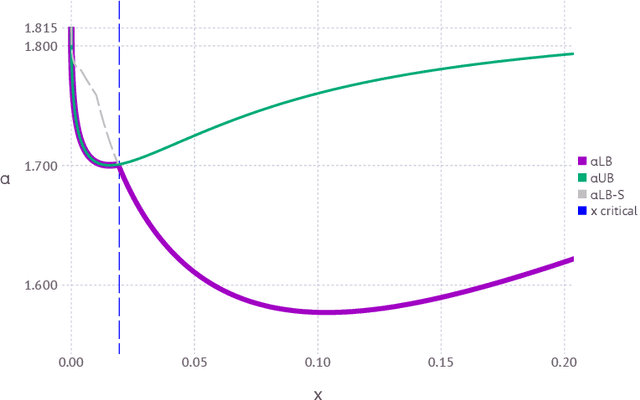
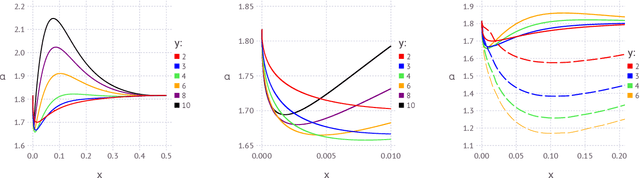
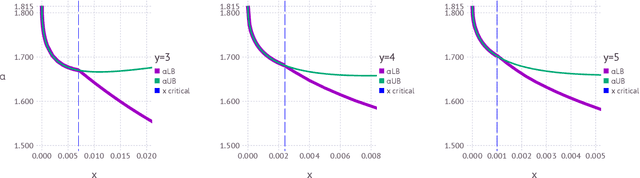
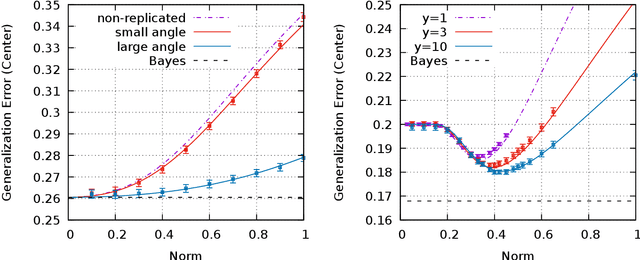
The geometrical features of the (non-convex) loss landscape of neural network models are crucial in ensuring successful optimization and, most importantly, the capability to generalize well. While minimizers' flatness consistently correlates with good generalization, there has been little rigorous work in exploring the condition of existence of such minimizers, even in toy models. Here we consider a simple neural network model, the symmetric perceptron, with binary weights. Phrasing the learning problem as a constraint satisfaction problem, the analogous of a flat minimizer becomes a large and dense cluster of solutions, while the narrowest minimizers are isolated solutions. We perform the first steps toward the rigorous proof of the existence of a dense cluster in certain regimes of the parameters, by computing the first and second moment upper bounds for the existence of pairs of arbitrarily close solutions. Moreover, we present a non rigorous derivation of the same bounds for sets of $y$ solutions at fixed pairwise distances.