 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe twin peaks of learning neural networks
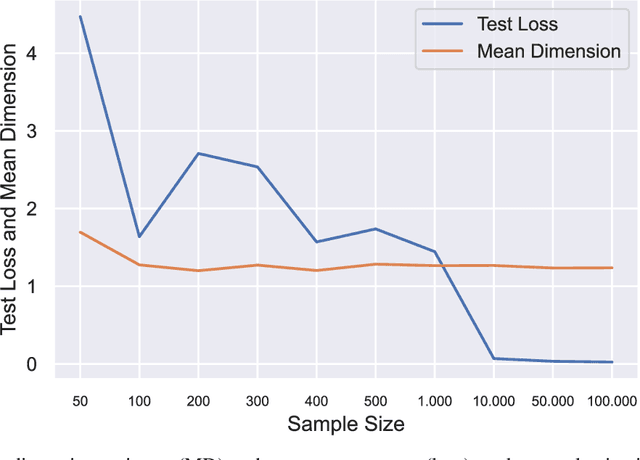
Jan 23, 2024Recent works demonstrated the existence of a double-descent phenomenon for the generalization error of neural networks, where highly overparameterized models escape overfitting and achieve good test performance, at odds with the standard bias-variance trade-off described by statistical learning theory. In the present work, we explore a link between this phenomenon and the increase of complexity and sensitivity of the function represented by neural networks. In particular, we study the Boolean mean dimension (BMD), a metric developed in the context of Boolean function analysis. Focusing on a simple teacher-student setting for the random feature model, we derive a theoretical analysis based on the replica method that yields an interpretable expression for the BMD, in the high dimensional regime where the number of data points, the number of features, and the input size grow to infinity. We find that, as the degree of overparameterization of the network is increased, the BMD reaches an evident peak at the interpolation threshold, in correspondence with the generalization error peak, and then slowly approaches a low asymptotic value. The same phenomenology is then traced in numerical experiments with different model classes and training setups. Moreover, we find empirically that adversarially initialized models tend to show higher BMD values, and that models that are more robust to adversarial attacks exhibit a lower BMD.
The Mean Dimension of Neural Networks -- What causes the interaction effects?
Jul 11, 2022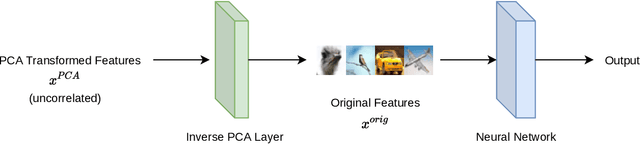

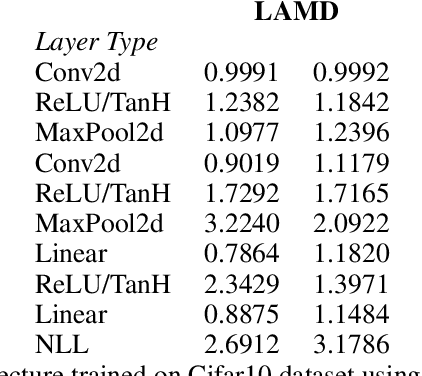
Owen and Hoyt recently showed that the effective dimension offers key structural information about the input-output mapping underlying an artificial neural network. Along this line of research, this work proposes an estimation procedure that allows the calculation of the mean dimension from a given dataset, without resampling from external distributions. The design yields total indices when features are independent and a variant of total indices when features are correlated. We show that this variant possesses the zero independence property. With synthetic datasets, we analyse how the mean dimension evolves layer by layer and how the activation function impacts the magnitude of interactions. We then use the mean dimension to study some of the most widely employed convolutional architectures for image recognition (LeNet, ResNet, DenseNet). To account for pixel correlations, we propose calculating the mean dimension after the addition of an inverse PCA layer that allows one to work on uncorrelated PCA-transformed features, without the need to retrain the neural network. We use the generalized total indices to produce heatmaps for post-hoc explanations, and we employ the mean dimension on the PCA-transformed features for cross comparisons of the artificial neural networks structures. Results provide several insights on the difference in magnitude of interactions across the architectures, as well as indications on how the mean dimension evolves during training.
Deep Networks on Toroids: Removing Symmetries Reveals the Structure of Flat Regions in the Landscape Geometry
Feb 07, 2022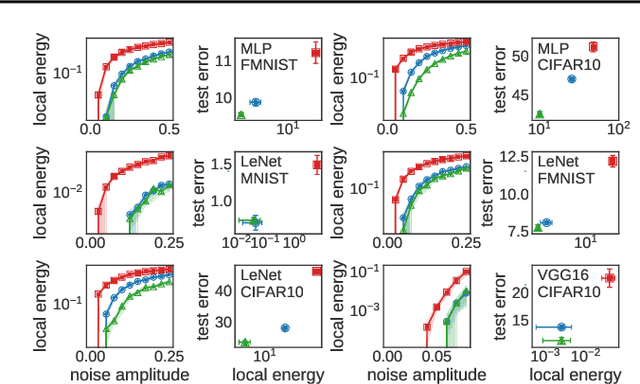
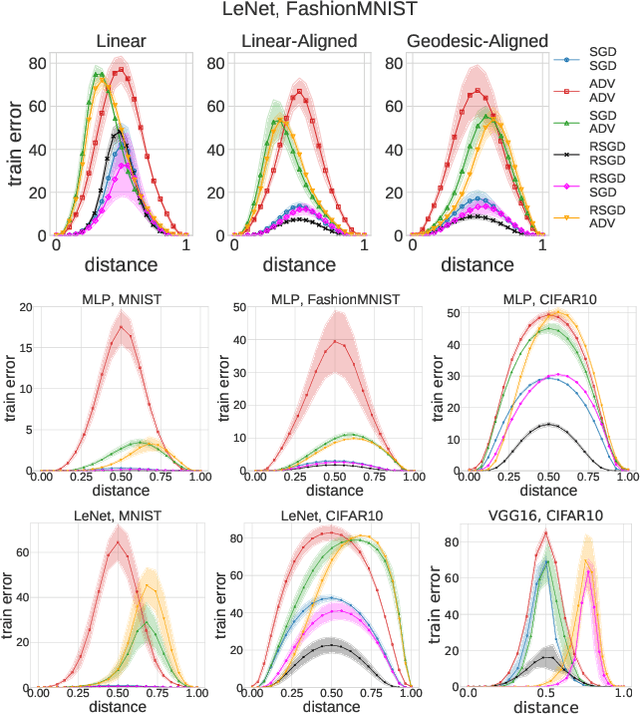
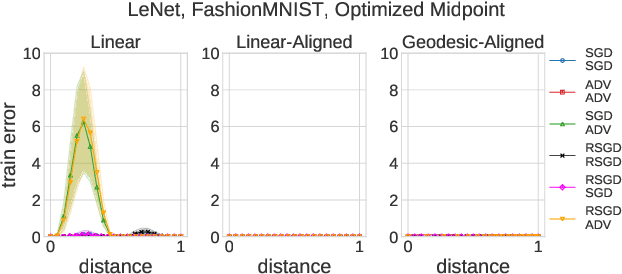
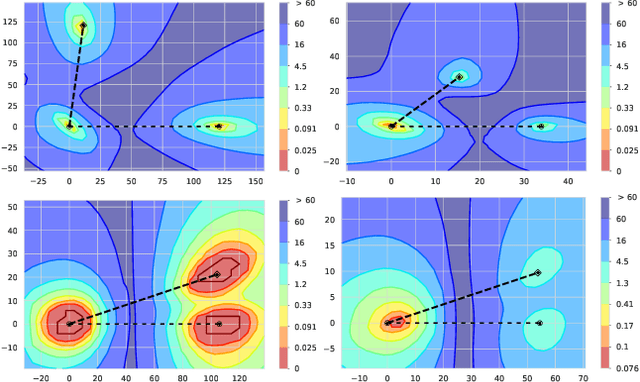
We systematize the approach to the investigation of deep neural network landscapes by basing it on the geometry of the space of implemented functions rather than the space of parameters. Grouping classifiers into equivalence classes, we develop a standardized parameterization in which all symmetries are removed, resulting in a toroidal topology. On this space, we explore the error landscape rather than the loss. This lets us derive a meaningful notion of the flatness of minimizers and of the geodesic paths connecting them. Using different optimization algorithms that sample minimizers with different flatness we study the mode connectivity and other characteristics. Testing a variety of state-of-the-art architectures and benchmark datasets, we confirm the correlation between flatness and generalization performance; we further show that in function space flatter minima are closer to each other and that the barriers along the geodesics connecting them are small. We also find that minimizers found by variants of gradient descent can be connected by zero-error paths with a single bend. We observe similar qualitative results in neural networks with binary weights and activations, providing one of the first results concerning the connectivity in this setting. Our results hinge on symmetry removal, and are in remarkable agreement with the rich phenomenology described by some recent analytical studies performed on simple shallow models.
Reconstruction of Pairwise Interactions using Energy-Based Models
Dec 11, 2020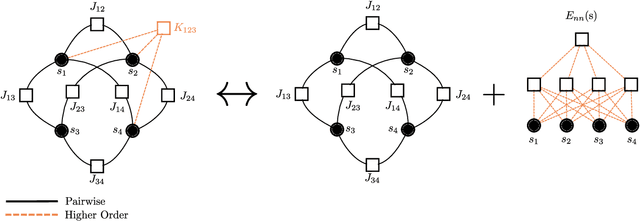
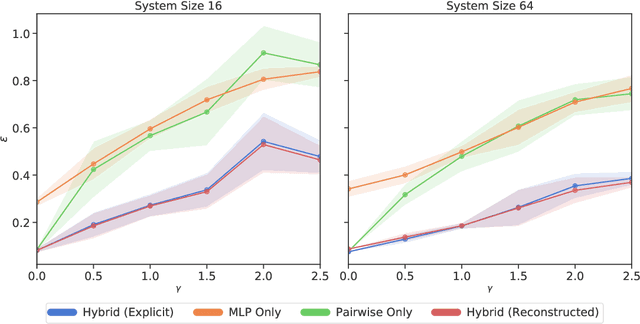
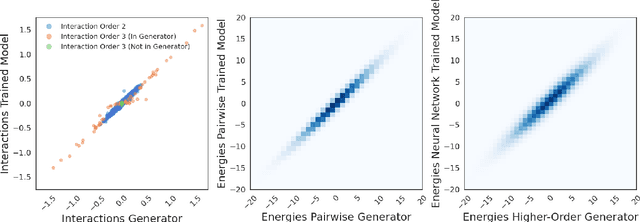
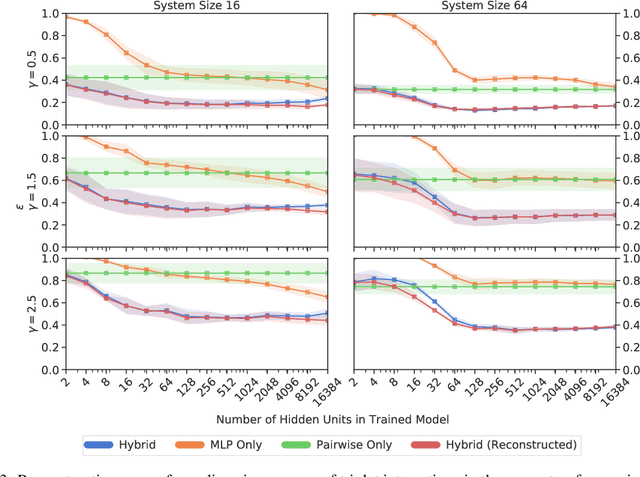
Pairwise models like the Ising model or the generalized Potts model have found many successful applications in fields like physics, biology, and economics. Closely connected is the problem of inverse statistical mechanics, where the goal is to infer the parameters of such models given observed data. An open problem in this field is the question of how to train these models in the case where the data contain additional higher-order interactions that are not present in the pairwise model. In this work, we propose an approach based on Energy-Based Models and pseudolikelihood maximization to address these complications: we show that hybrid models, which combine a pairwise model and a neural network, can lead to significant improvements in the reconstruction of pairwise interactions. We show these improvements to hold consistently when compared to a standard approach using only the pairwise model and to an approach using only a neural network. This is in line with the general idea that simple interpretable models and complex black-box models are not necessarily a dichotomy: interpolating these two classes of models can allow to keep some advantages of both.
Entropic gradient descent algorithms and wide flat minima
Jun 14, 2020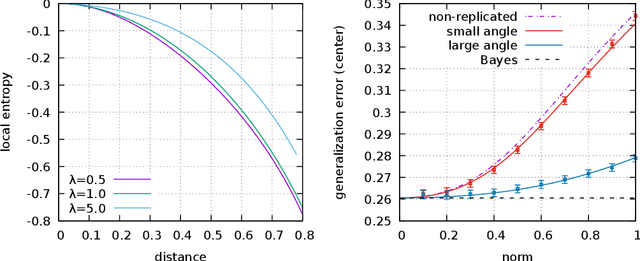
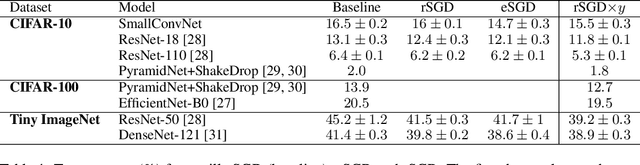

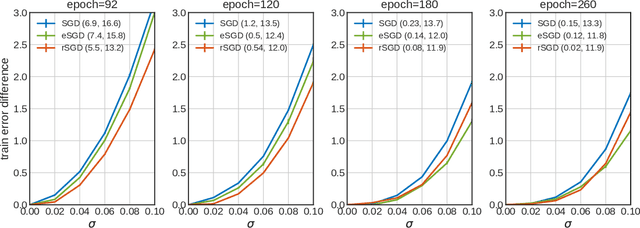
The properties of flat minima in the empirical risk landscape of neural networks have been debated for some time. Increasing evidence suggests they possess better generalization capabilities with respect to sharp ones. First, we discuss Gaussian mixture classification models and show analytically that there exist Bayes optimal pointwise estimators which correspond to minimizers belonging to wide flat regions. These estimators can be found by applying maximum flatness algorithms either directly on the classifier (which is norm independent) or on the differentiable loss function used in learning. Next, we extend the analysis to the deep learning scenario by extensive numerical validations. Using two algorithms, Entropy-SGD and Replicated-SGD, that explicitly include in the optimization objective a non-local flatness measure known as local entropy, we consistently improve the generalization error for common architectures (e.g. ResNet, EfficientNet). An easy to compute flatness measure shows a clear correlation with test accuracy.
Natural representation of composite data with replicated autoencoders
Sep 29, 2019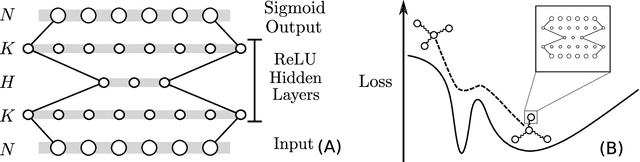
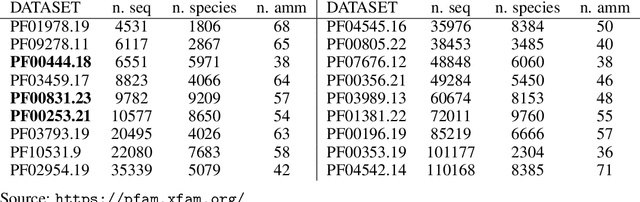
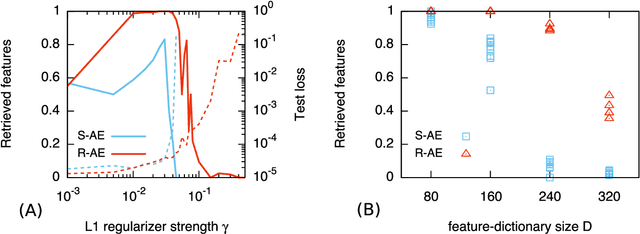
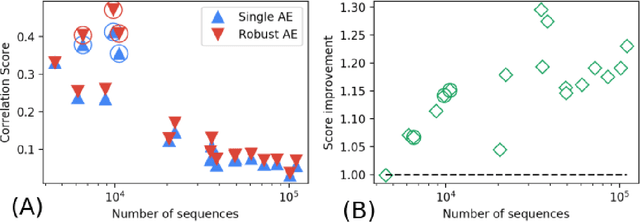
Generative processes in biology and other fields often produce data that can be regarded as resulting from a composition of basic features. Here we present an unsupervised method based on autoencoders for inferring these basic features of data. The main novelty in our approach is that the training is based on the optimization of the `local entropy' rather than the standard loss, resulting in a more robust inference, and enhancing the performance on this type of data considerably. Algorithmically, this is realized by training an interacting system of replicated autoencoders. We apply this method to synthetic and protein sequence data, and show that it is able to infer a hidden representation that correlates well with the underlying generative process, without requiring any prior knowledge.