 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive kernel predictors from feature-learning infinite limits of neural networks
Feb 11, 2025Previous influential work showed that infinite width limits of neural networks in the lazy training regime are described by kernel machines. Here, we show that neural networks trained in the rich, feature learning infinite-width regime in two different settings are also described by kernel machines, but with data-dependent kernels. For both cases, we provide explicit expressions for the kernel predictors and prescriptions to numerically calculate them. To derive the first predictor, we study the large-width limit of feature-learning Bayesian networks, showing how feature learning leads to task-relevant adaptation of layer kernels and preactivation densities. The saddle point equations governing this limit result in a min-max optimization problem that defines the kernel predictor. To derive the second predictor, we study gradient flow training of randomly initialized networks trained with weight decay in the infinite-width limit using dynamical mean field theory (DMFT). The fixed point equations of the arising DMFT defines the task-adapted internal representations and the kernel predictor. We compare our kernel predictors to kernels derived from lazy regime and demonstrate that our adaptive kernels achieve lower test loss on benchmark datasets.
Random Features Hopfield Networks generalize retrieval to previously unseen examples
Jul 08, 2024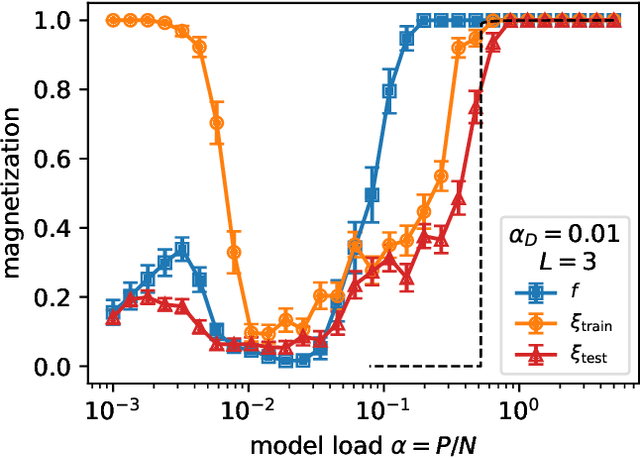
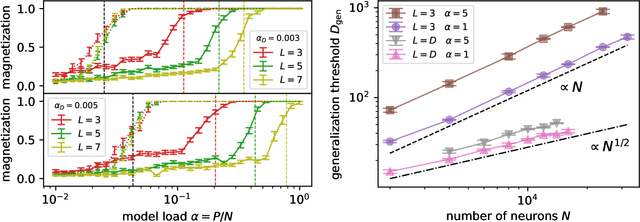
It has been recently shown that a learning transition happens when a Hopfield Network stores examples generated as superpositions of random features, where new attractors corresponding to such features appear in the model. In this work we reveal that the network also develops attractors corresponding to previously unseen examples generated with the same set of features. We explain this surprising behaviour in terms of spurious states of the learned features: we argue that, increasing the number of stored examples beyond the learning transition, the model also learns to mix the features to represent both stored and previously unseen examples. We support this claim with the computation of the phase diagram of the model.
Sparse Representations, Inference and Learning
Jun 28, 2023In recent years statistical physics has proven to be a valuable tool to probe into large dimensional inference problems such as the ones occurring in machine learning. Statistical physics provides analytical tools to study fundamental limitations in their solutions and proposes algorithms to solve individual instances. In these notes, based on the lectures by Marc M\'ezard in 2022 at the summer school in Les Houches, we will present a general framework that can be used in a large variety of problems with weak long-range interactions, including the compressed sensing problem, or the problem of learning in a perceptron. We shall see how these problems can be studied at the replica symmetric level, using developments of the cavity methods, both as a theoretical tool and as an algorithm.
The star-shaped space of solutions of the spherical negative perceptron
May 18, 2023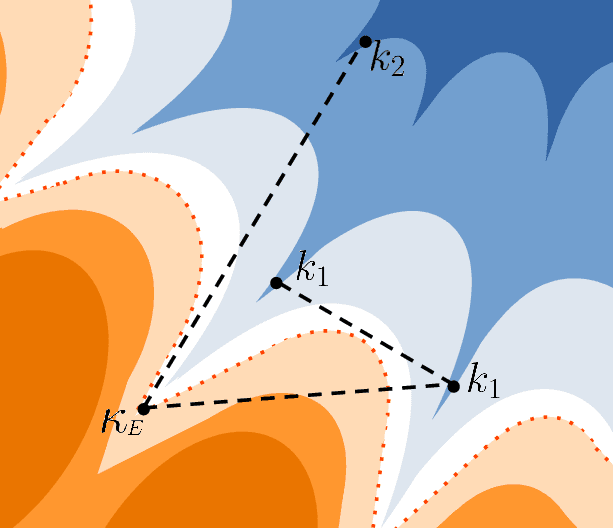
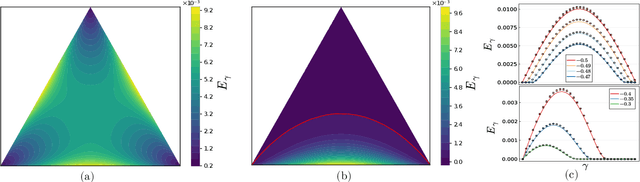
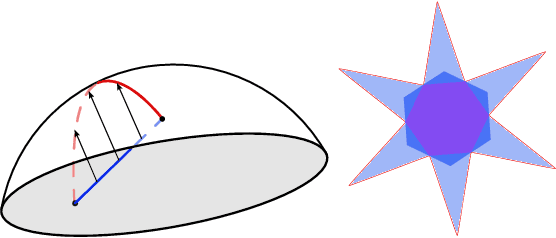
Empirical studies on the landscape of neural networks have shown that low-energy configurations are often found in complex connected structures, where zero-energy paths between pairs of distant solutions can be constructed. Here we consider the spherical negative perceptron, a prototypical non-convex neural network model framed as a continuous constraint satisfaction problem. We introduce a general analytical method for computing energy barriers in the simplex with vertex configurations sampled from the equilibrium. We find that in the over-parameterized regime the solution manifold displays simple connectivity properties. There exists a large geodesically convex component that is attractive for a wide range of optimization dynamics. Inside this region we identify a subset of atypically robust solutions that are geodesically connected with most other solutions, giving rise to a star-shaped geometry. We analytically characterize the organization of the connected space of solutions and show numerical evidence of a transition, at larger constraint densities, where the aforementioned simple geodesic connectivity breaks down.
The Hidden-Manifold Hopfield Model and a learning phase transition
Mar 29, 2023



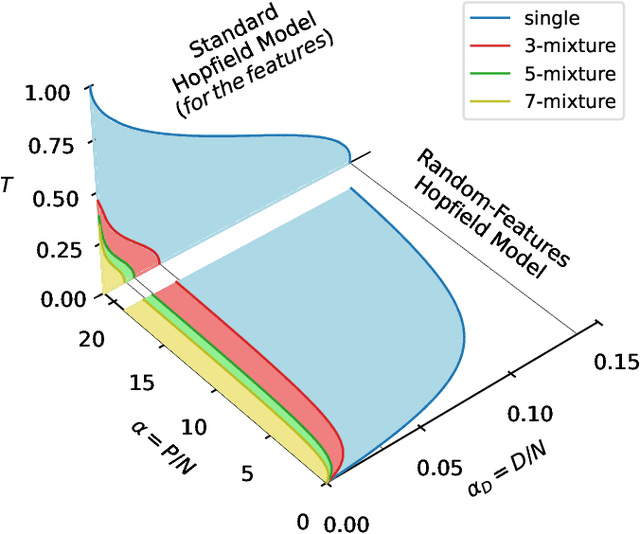
The Hopfield model has a long-standing tradition in statistical physics, being one of the few neural networks for which a theory is available. Extending the theory of Hopfield models for correlated data could help understand the success of deep neural networks, for instance describing how they extract features from data. Motivated by this, we propose and investigate a generalized Hopfield model that we name Hidden-Manifold Hopfield Model: we generate the couplings from $P=\alpha N$ examples with the Hebb rule using a non-linear transformation of $D=\alpha_D N$ random vectors that we call factors, with $N$ the number of neurons. Using the replica method, we obtain a phase diagram for the model that shows a phase transition where the factors hidden in the examples become attractors of the dynamics; this phase exists above a critical value of $\alpha$ and below a critical value of $\alpha_D$. We call this behaviour learning transition.
Learning through atypical ''phase transitions'' in overparameterized neural networks
Oct 01, 2021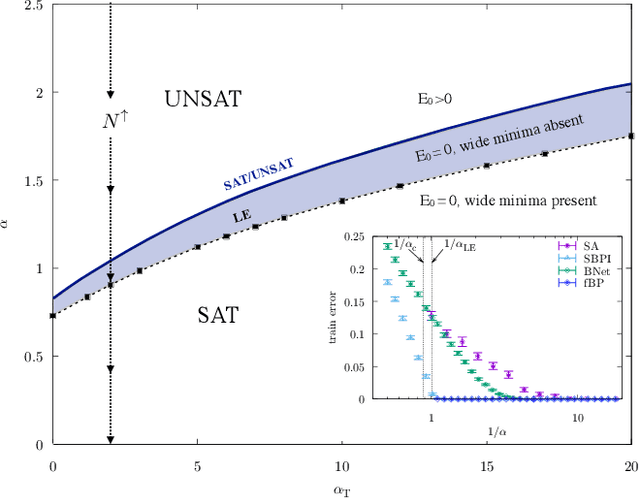
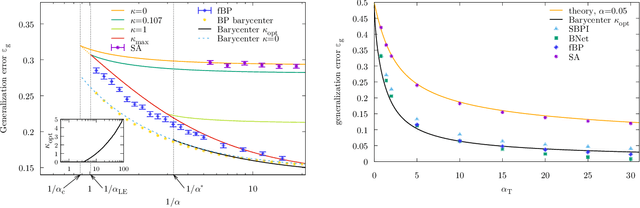

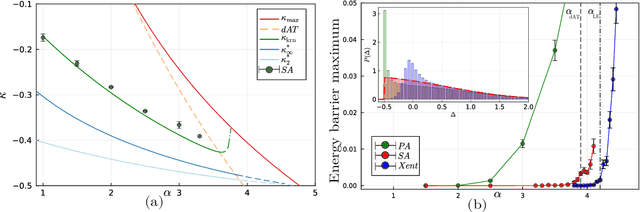
Current deep neural networks are highly overparameterized (up to billions of connection weights) and nonlinear. Yet they can fit data almost perfectly through variants of gradient descent algorithms and achieve unexpected levels of prediction accuracy without overfitting. These are formidable results that escape the bias-variance predictions of statistical learning and pose conceptual challenges for non-convex optimization. In this paper, we use methods from statistical physics of disordered systems to analytically study the computational fallout of overparameterization in nonconvex neural network models. As the number of connection weights increases, we follow the changes of the geometrical structure of different minima of the error loss function and relate them to learning and generalisation performance. We find that there exist a gap between the SAT/UNSAT interpolation transition where solutions begin to exist and the point where algorithms start to find solutions, i.e. where accessible solutions appear. This second phase transition coincides with the discontinuous appearance of atypical solutions that are locally extremely entropic, i.e., flat regions of the weight space that are particularly solution-dense and have good generalization properties. Although exponentially rare compared to typical solutions (which are narrower and extremely difficult to sample), entropic solutions are accessible to the algorithms used in learning. We can characterize the generalization error of different solutions and optimize the Bayesian prediction, for data generated from a structurally different network. Numerical tests on observables suggested by the theory confirm that the scenario extends to realistic deep networks.
Unveiling the structure of wide flat minima in neural networks
Jul 02, 2021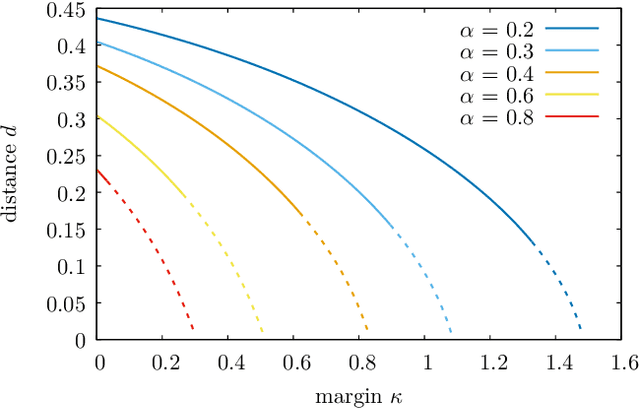
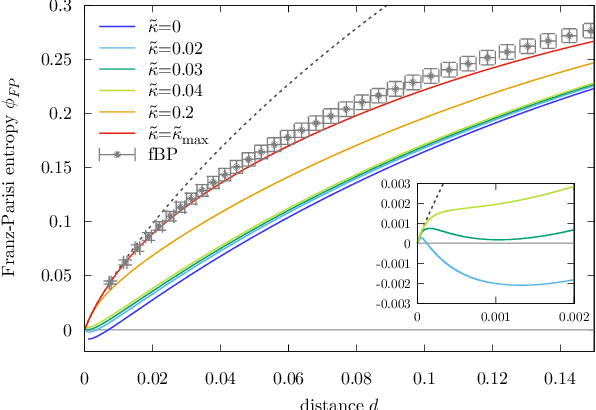
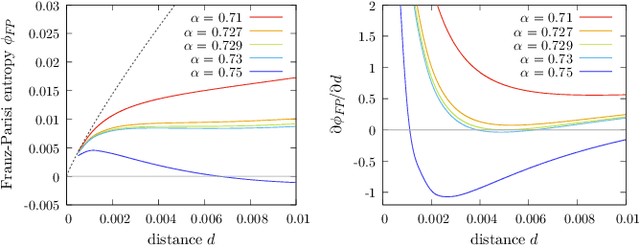
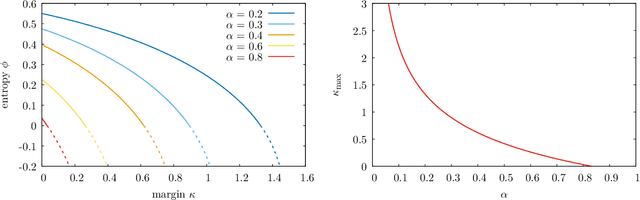
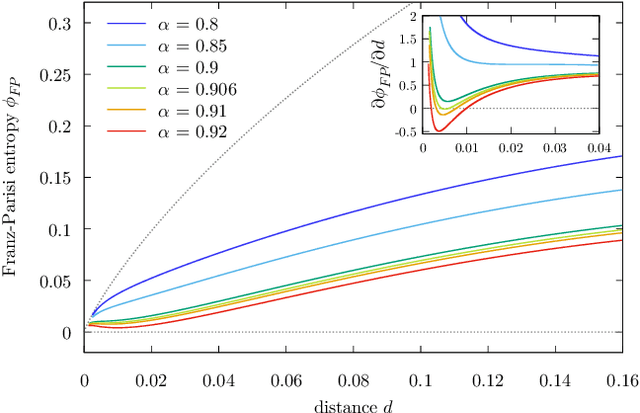
The success of deep learning has revealed the application potential of neural networks across the sciences and opened up fundamental theoretical problems. In particular, the fact that learning algorithms based on simple variants of gradient methods are able to find near-optimal minima of highly nonconvex loss functions is an unexpected feature of neural networks which needs to be understood in depth. Such algorithms are able to fit the data almost perfectly, even in the presence of noise, and yet they have excellent predictive capabilities. Several empirical results have shown a reproducible correlation between the so-called flatness of the minima achieved by the algorithms and the generalization performance. At the same time, statistical physics results have shown that in nonconvex networks a multitude of narrow minima may coexist with a much smaller number of wide flat minima, which generalize well. Here we show that wide flat minima arise from the coalescence of minima that correspond to high-margin classifications. Despite being exponentially rare compared to zero-margin solutions, high-margin minima tend to concentrate in particular regions. These minima are in turn surrounded by other solutions of smaller and smaller margin, leading to dense regions of solutions over long distances. Our analysis also provides an alternative analytical method for estimating when flat minima appear and when algorithms begin to find solutions, as the number of model parameters varies.