 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWide flat minima and optimal generalization in classifying high-dimensional Gaussian mixtures
Paper and Code
Oct 27, 2020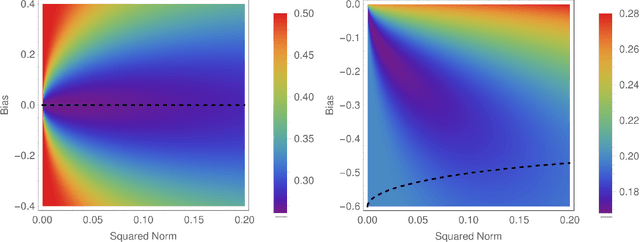

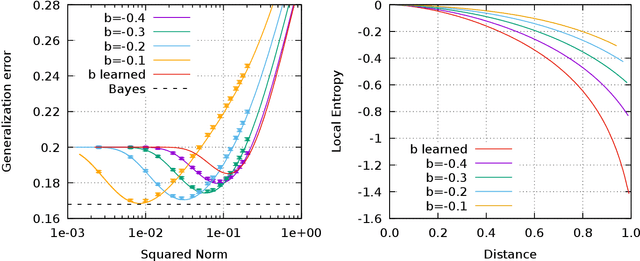
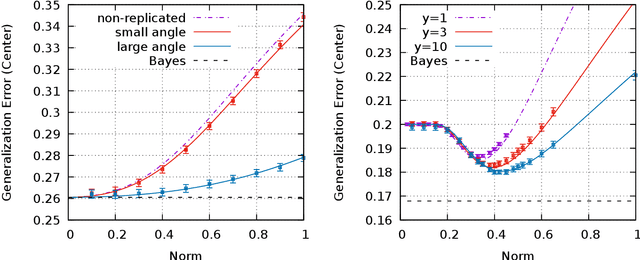
We analyze the connection between minimizers with good generalizing properties and high local entropy regions of a threshold-linear classifier in Gaussian mixtures with the mean squared error loss function. We show that there exist configurations that achieve the Bayes-optimal generalization error, even in the case of unbalanced clusters. We explore analytically the error-counting loss landscape in the vicinity of a Bayes-optimal solution, and show that the closer we get to such configurations, the higher the local entropy, implying that the Bayes-optimal solution lays inside a wide flat region. We also consider the algorithmically relevant case of targeting wide flat minima of the (differentiable) mean squared error loss. Our analytical and numerical results show not only that in the balanced case the dependence on the norm of the weights is mild, but also, in the unbalanced case, that the performances can be improved.