 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Precision Training in Logarithmic Number System using Multiplicative Weight Update
Paper and Code
Jun 26, 2021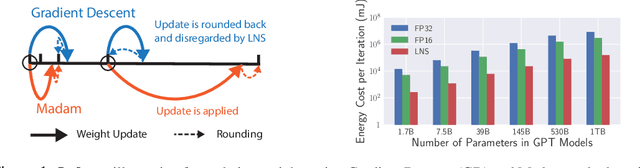
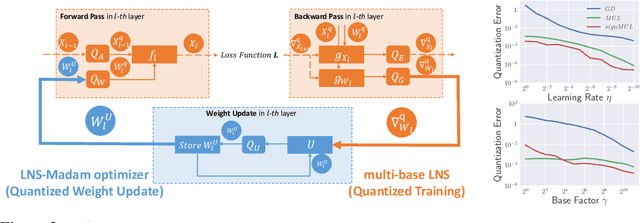
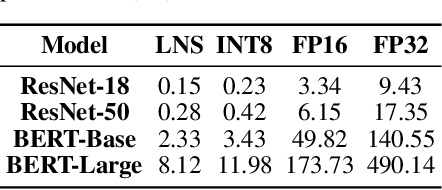
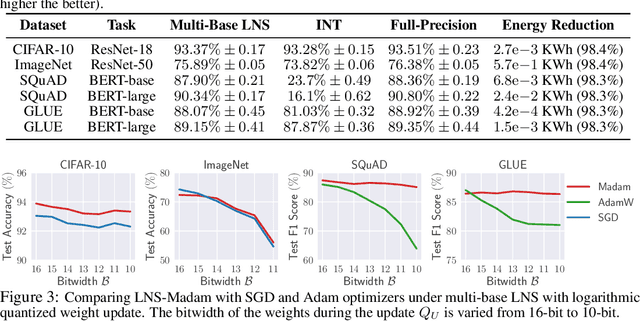
Training large-scale deep neural networks (DNNs) currently requires a significant amount of energy, leading to serious environmental impacts. One promising approach to reduce the energy costs is representing DNNs with low-precision numbers. While it is common to train DNNs with forward and backward propagation in low-precision, training directly over low-precision weights, without keeping a copy of weights in high-precision, still remains to be an unsolved problem. This is due to complex interactions between learning algorithms and low-precision number systems. To address this, we jointly design a low-precision training framework involving a logarithmic number system (LNS) and a multiplicative weight update training method, termed LNS-Madam. LNS has a high dynamic range even in a low-bitwidth setting, leading to high energy efficiency and making it relevant for on-board training in energy-constrained edge devices. We design LNS to have the flexibility of choosing different bases for weights and gradients, as they usually require different quantization gaps and dynamic ranges during training. By drawing the connection between LNS and multiplicative update, LNS-Madam ensures low quantization error during weight update, leading to a stable convergence even if the bitwidth is limited. Compared to using a fixed-point or floating-point number system and training with popular learning algorithms such as SGD and Adam, our joint design with LNS and LNS-Madam optimizer achieves better accuracy while requiring smaller bitwidth. Notably, with only 5-bit for gradients, the proposed training framework achieves accuracy comparable to full-precision state-of-the-art models such as ResNet-50 and BERT. After conducting energy estimations by analyzing the math datapath units during training, the results show that our design achieves over 60x energy reduction compared to FP32 on BERT models.