 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionArena: 230K Real World User-VLM Conversations with Preference Labels
Dec 11, 2024



With the growing adoption and capabilities of vision-language models (VLMs) comes the need for benchmarks that capture authentic user-VLM interactions. In response, we create VisionArena, a dataset of 230K real-world conversations between users and VLMs. Collected from Chatbot Arena - an open-source platform where users interact with VLMs and submit preference votes - VisionArena spans 73K unique users, 45 VLMs, and 138 languages. Our dataset contains three subsets: VisionArena-Chat, 200k single and multi-turn conversations between a user and a VLM; VisionArena-Battle, 30K conversations comparing two anonymous VLMs with user preference votes; and VisionArena-Bench, an automatic benchmark of 500 diverse user prompts that efficiently approximate the live Chatbot Arena model rankings. Additionally, we highlight the types of question asked by users, the influence of response style on preference, and areas where models often fail. We find open-ended tasks like captioning and humor are highly style-dependent, and current VLMs struggle with spatial reasoning and planning tasks. Lastly, we show finetuning the same base model on VisionArena-Chat outperforms Llava-Instruct-158K, with a 17-point gain on MMMU and a 46-point gain on the WildVision benchmark. Dataset at https://huggingface.co/lmarena-ai
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
Nov 07, 2023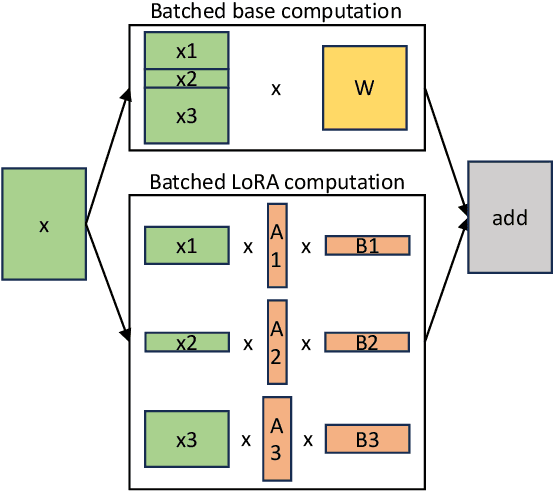

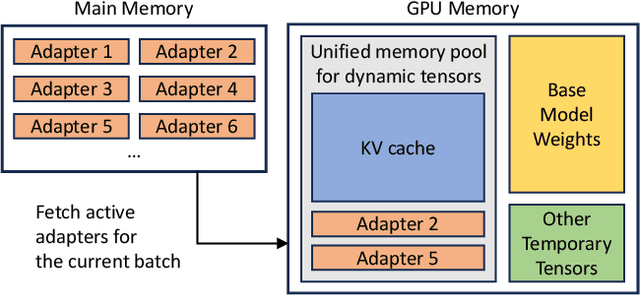

The "pretrain-then-finetune" paradigm is commonly adopted in the deployment of large language models. Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method, is often employed to adapt a base model to a multitude of tasks, resulting in a substantial collection of LoRA adapters derived from one base model. We observe that this paradigm presents significant opportunities for batched inference during serving. To capitalize on these opportunities, we present S-LoRA, a system designed for the scalable serving of many LoRA adapters. S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes Unified Paging. Unified Paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead. Compared to state-of-the-art libraries such as HuggingFace PEFT and vLLM (with naive support of LoRA serving), S-LoRA can improve the throughput by up to 4 times and increase the number of served adapters by several orders of magnitude. As a result, S-LoRA enables scalable serving of many task-specific fine-tuned models and offers the potential for large-scale customized fine-tuning services. The code is available at https://github.com/S-LoRA/S-LoRA
Decentralized Vehicle Coordination: The Berkeley DeepDrive Drone Dataset
Sep 22, 2022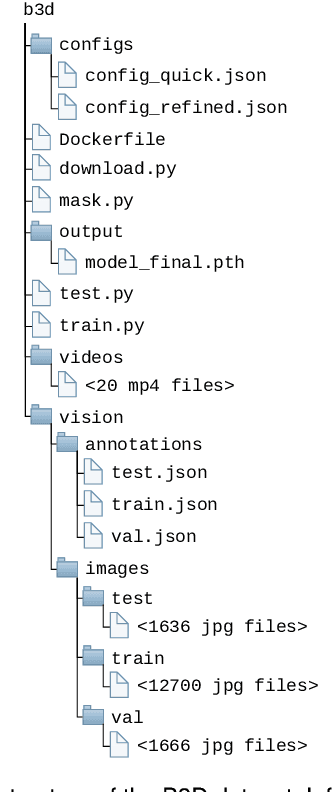
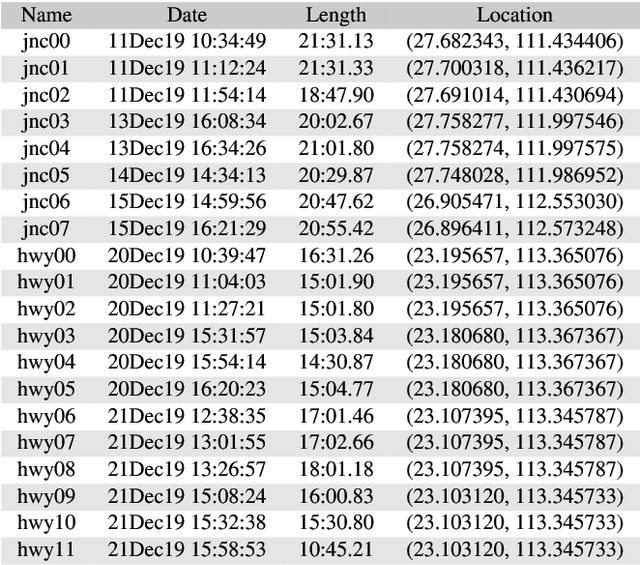


Decentralized multiagent planning has been an important field of research in robotics. An interesting and impactful application in the field is decentralized vehicle coordination in understructured road environments. For example, in an intersection, it is useful yet difficult to deconflict multiple vehicles of intersecting paths in absence of a central coordinator. We learn from common sense that, for a vehicle to navigate through such understructured environments, the driver must understand and conform to the implicit "social etiquette" observed by nearby drivers. To study this implicit driving protocol, we collect the Berkeley DeepDrive Drone dataset. The dataset contains 1) a set of aerial videos recording understructured driving, 2) a collection of images and annotations to train vehicle detection models, and 3) a kit of development scripts for illustrating typical usages. We believe that the dataset is of primary interest for studying decentralized multiagent planning employed by human drivers and, of secondary interest, for computer vision in remote sensing settings.