 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathGen: Revealing the Illusion of Mathematical Competence through Text-to-Image Generation
Mar 31, 2026Modern generative models have demonstrated the ability to solve challenging mathematical problems. In many real-world settings, however, mathematical solutions must be expressed visually through diagrams, plots, geometric constructions, and structured symbolic layouts, where correctness depends on precise visual composition. This naturally raises the question of whether generative models can still do so when the answer must be rendered visually rather than written in text? To study this problem, we introduce MathGen, a rigorous benchmark of 900 problems spanning seven core domains, each paired with an executable verifier under a Script-as-a-Judge protocol for deterministic and objective evaluation. Experiments on representative open-source and proprietary text-to-image models show that mathematical fidelity remains a major bottleneck: even the best closed-source model reaches only 42.0% overall accuracy, while open-source models achieve just ~ 1-11%, often near 0% on structured tasks. Overall, current T2I models remain far from competent at even elementary mathematical visual generation.
Rollout-Training Co-Design for Efficient LLM-Based Multi-Agent Reinforcement Learning
Feb 10, 2026Despite algorithm-level innovations for multi-agent reinforcement learning (MARL), the underlying networked infrastructure for large-scale MARL training remains underexplored. Existing training frameworks primarily optimize for single-agent scenarios and fail to address the unique system-level challenges of MARL, including rollout-training synchronization barriers, rollout load imbalance, and training resource underutilization. To bridge this gap, we propose FlexMARL, the first end-to-end training framework that holistically optimizes rollout, training, and their orchestration for large-scale LLM-based MARL. Specifically, FlexMARL introduces the joint orchestrator to manage data flow under the rollout-training disaggregated architecture. Building upon the experience store, a novel micro-batch driven asynchronous pipeline eliminates the synchronization barriers while providing strong consistency guarantees. Rollout engine adopts a parallel sampling scheme combined with hierarchical load balancing, which adapts to skewed inter/intra-agent request patterns. Training engine achieves on-demand hardware binding through agent-centric resource allocation. The training states of different agents are swapped via unified and location-agnostic communication. Empirical results on a large-scale production cluster demonstrate that FlexMARL achieves up to 7.3x speedup and improves hardware utilization by up to 5.6x compared to existing frameworks.
JoyAgents-R1: Joint Evolution Dynamics for Versatile Multi-LLM Agents with Reinforcement Learning
Jun 24, 2025Multi-agent reinforcement learning (MARL) has emerged as a prominent paradigm for increasingly complex tasks. However, joint evolution across heterogeneous agents remains challenging due to cooperative inefficiency and training instability. In this paper, we propose the joint evolution dynamics for MARL called JoyAgents-R1, which first applies Group Relative Policy Optimization (GRPO) to the joint training of heterogeneous multi-agents. By iteratively refining agents' large language models (LLMs) and memories, the method achieves holistic equilibrium with optimal decision-making and memory capabilities. Specifically, JoyAgents-R1 first implements node-wise Monte Carlo sampling on the behavior of each agent across entire reasoning trajectories to enhance GRPO sampling efficiency while maintaining policy diversity. Then, our marginal benefit-driven selection strategy identifies top-$K$ sampling groups with maximal reward fluctuations, enabling targeted agent model updates that improve training stability and maximize joint benefits through cost-effective parameter adjustments. Meanwhile, JoyAgents-R1 introduces an adaptive memory evolution mechanism that repurposes GRPO rewards as cost-free supervisory signals to eliminate repetitive reasoning and accelerate convergence. Experiments across general and domain-specific scenarios demonstrate that JoyAgents-R1 achieves performance comparable to that of larger LLMs while built on smaller open-source models.
TPLogAD: Unsupervised Log Anomaly Detection Based on Event Templates and Key Parameters
Nov 22, 2024
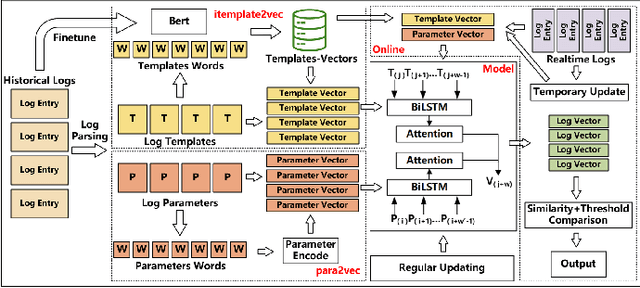
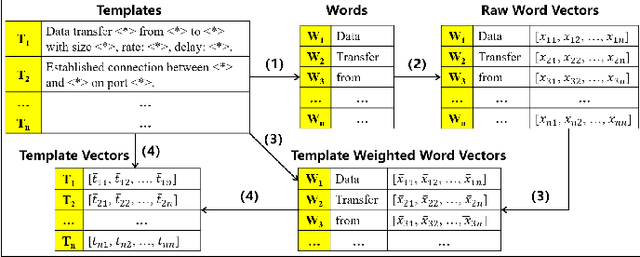
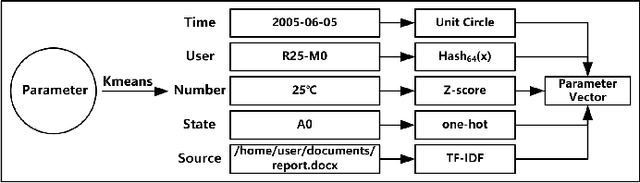
Log-system is an important mechanism for recording the runtime status and events of Web service systems, and anomaly detection in logs is an effective method of detecting problems. However, manual anomaly detection in logs is inefficient, error-prone, and unrealistic. Existing log anomaly detection methods either use the indexes of event templates, or form vectors by embedding the fixed string part of the template as a sentence, or use time parameters for sequence analysis. However, log entries often contain features and semantic information that cannot be fully represented by these methods, resulting in missed and false alarms. In this paper, we propose TPLogAD, a universal unsupervised method for analyzing unstructured logs, which performs anomaly detection based on event templates and key parameters. The itemplate2vec and para2vec included in TPLogAD are two efficient and easy-to-implement semantic representation methods for logs, detecting anomalies in event templates and parameters respectively, which has not been achieved in previous work. Additionally, TPLogAD can avoid the interference of log diversity and dynamics on anomaly detection. Our experiments on four public log datasets show that TPLogAD outperforms existing log anomaly detection methods.
Bayesian Deep Learning Approach for Real-time Lane-based Arrival Curve Reconstruction at Intersection using License Plate Recognition Data
Nov 12, 2024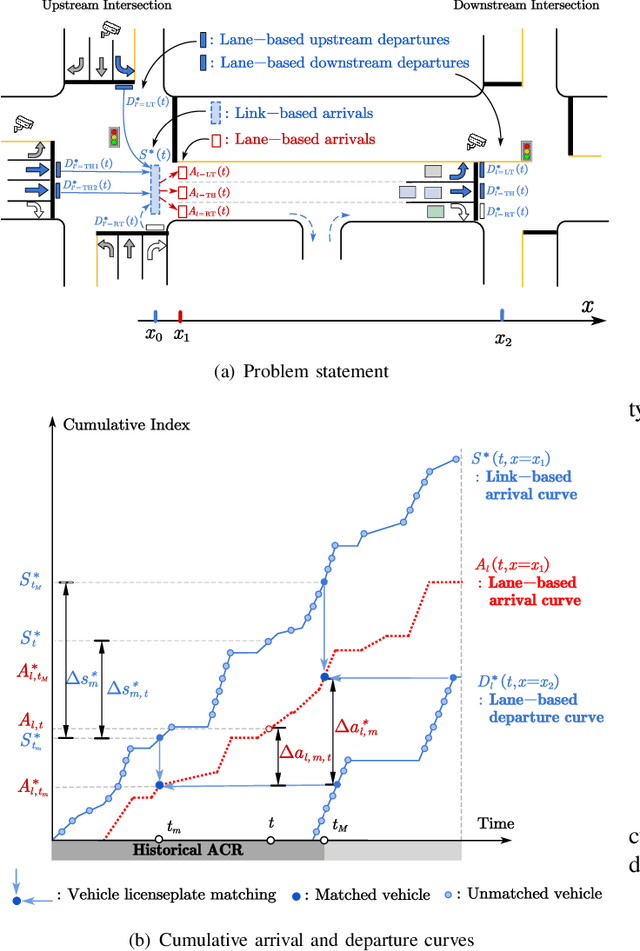
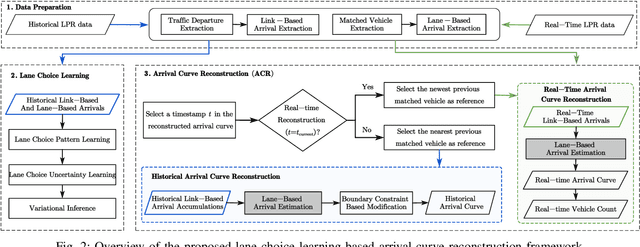
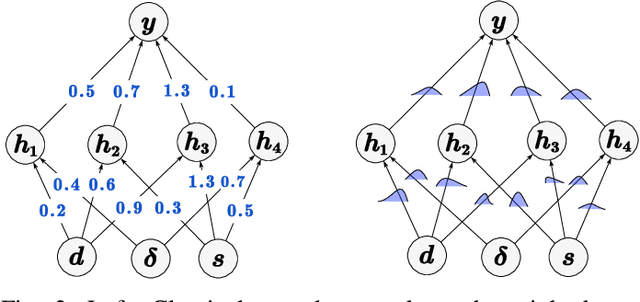
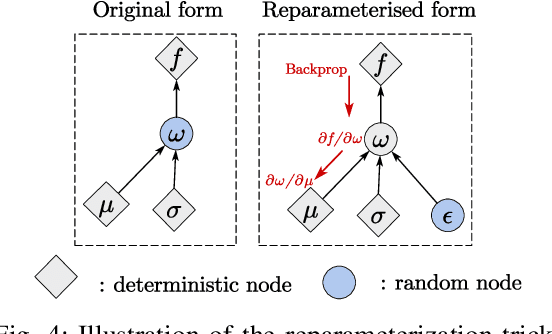
The acquisition of real-time and accurate traffic arrival information is of vital importance for proactive traffic control systems, especially in partially connected vehicle environments. License plate recognition (LPR) data that record both vehicle departures and identities are proven to be desirable in reconstructing lane-based arrival curves in previous works. Existing LPR databased methods are predominantly designed for reconstructing historical arrival curves. For real-time reconstruction of multi-lane urban roads, it is pivotal to determine the lane choice of real-time link-based arrivals, which has not been exploited in previous studies. In this study, we propose a Bayesian deep learning approach for real-time lane-based arrival curve reconstruction, in which the lane choice patterns and uncertainties of link-based arrivals are both characterized. Specifically, the learning process is designed to effectively capture the relationship between partially observed link-based arrivals and lane-based arrivals, which can be physically interpreted as lane choice proportion. Moreover, the lane choice uncertainties are characterized using Bayesian parameter inference techniques, minimizing arrival curve reconstruction uncertainties, especially in low LPR data matching rate conditions. Real-world experiment results conducted in multiple matching rate scenarios demonstrate the superiority and necessity of lane choice modeling in reconstructing arrival curves.
GenesisTex2: Stable, Consistent and High-Quality Text-to-Texture Generation
Sep 27, 2024



Large-scale text-guided image diffusion models have shown astonishing results in text-to-image (T2I) generation. However, applying these models to synthesize textures for 3D geometries remains challenging due to the domain gap between 2D images and textures on a 3D surface. Early works that used a projecting-and-inpainting approach managed to preserve generation diversity but often resulted in noticeable artifacts and style inconsistencies. While recent methods have attempted to address these inconsistencies, they often introduce other issues, such as blurring, over-saturation, or over-smoothing. To overcome these challenges, we propose a novel text-to-texture synthesis framework that leverages pretrained diffusion models. We first introduce a local attention reweighing mechanism in the self-attention layers to guide the model in concentrating on spatial-correlated patches across different views, thereby enhancing local details while preserving cross-view consistency. Additionally, we propose a novel latent space merge pipeline, which further ensures consistency across different viewpoints without sacrificing too much diversity. Our method significantly outperforms existing state-of-the-art techniques regarding texture consistency and visual quality, while delivering results much faster than distillation-based methods. Importantly, our framework does not require additional training or fine-tuning, making it highly adaptable to a wide range of models available on public platforms.
Boosting Column Generation with Graph Neural Networks for Joint Rider Trip Planning and Crew Shift Scheduling
Jan 08, 2024
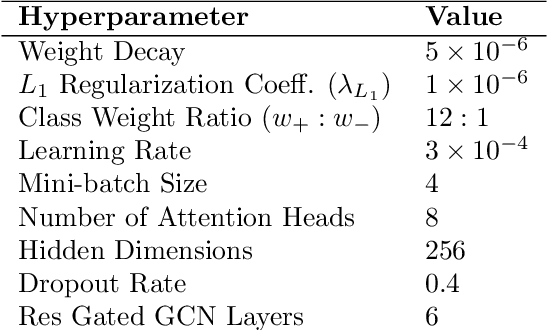

Optimizing service schedules is pivotal to the reliable, efficient, and inclusive on-demand mobility. This pressing challenge is further exacerbated by the increasing needs of an aging population, the over-subscription of existing services, and the lack of effective solution methods. This study addresses the intricacies of service scheduling, by jointly optimizing rider trip planning and crew scheduling for a complex dynamic mobility service. The resulting optimization problems are extremely challenging computationally for state-of-the-art methods. To address this fundamental gap, this paper introduces the Joint Rider Trip Planning and Crew Shift Scheduling Problem (JRTPCSSP) and a novel solution method, called AGGNNI-CG (Attention and Gated GNN- Informed Column Generation), that hybridizes column generation and machine learning to obtain near-optimal solutions to the JRTPCSSP with the real-time constraints of the application. The key idea of the machine-learning component is to dramatically reduce the number of paths to explore in the pricing component, accelerating the most time-consuming component of the column generation. The machine learning component is a graph neural network with an attention mechanism and a gated architecture, that is particularly suited to cater for the different input sizes coming from daily operations. AGGNNI-CG has been applied to a challenging, real-world dataset from the Paratransit system of Chatham County in Georgia. It produces dramatic improvements compared to the baseline column generation approach, which typically cannot produce feasible solutions in reasonable time on both medium-sized and large-scale complex instances. AGGNNI-CG also produces significant improvements in service compared to the existing system.
A Big-Data Driven Framework to Estimating Vehicle Volume based on Mobile Device Location Data
Jan 24, 2023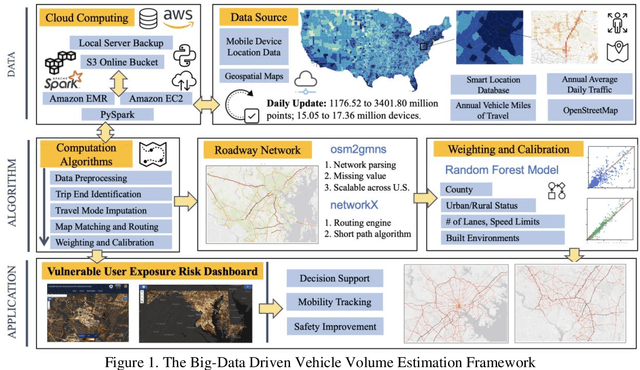
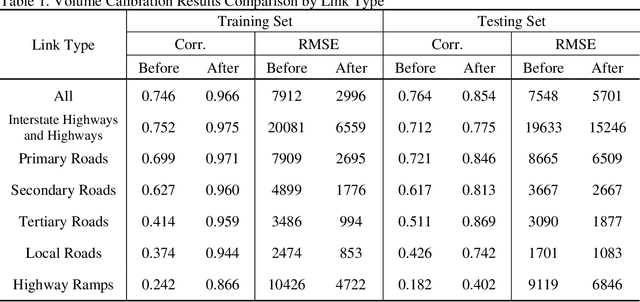
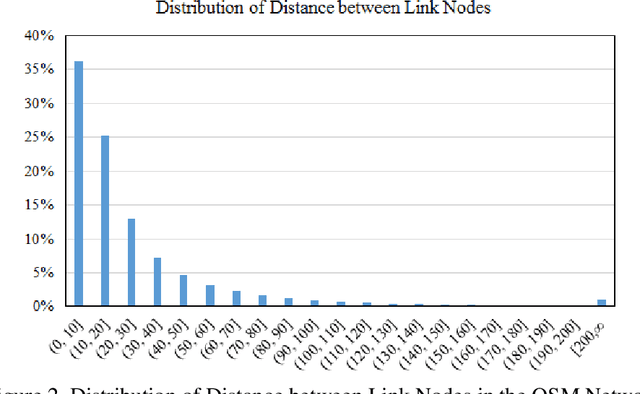
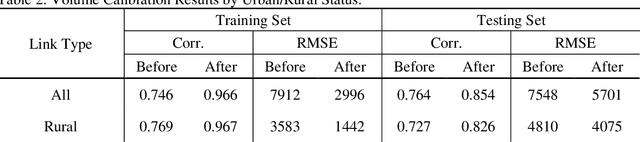
Vehicle volume serves as a critical metric and the fundamental basis for traffic signal control, transportation project prioritization, road maintenance plans and more. Traditional methods of quantifying vehicle volume rely on manual counting, video cameras, and loop detectors at a limited number of locations. These efforts require significant labor and cost for expansions. Researchers and private sector companies have also explored alternative solutions such as probe vehicle data, while still suffering from a low penetration rate. In recent years, along with the technological advancement in mobile sensors and mobile networks, Mobile Device Location Data (MDLD) have been growing dramatically in terms of the spatiotemporal coverage of the population and its mobility. This paper presents a big-data driven framework that can ingest terabytes of MDLD and estimate vehicle volume at a larger geographical area with a larger sample size. The proposed framework first employs a series of cloud-based computational algorithms to extract multimodal trajectories and trip rosters. A scalable map matching and routing algorithm is then applied to snap and route vehicle trajectories to the roadway network. The observed vehicle counts on each roadway segment are weighted and calibrated against ground truth control totals, i.e., Annual Vehicle-Miles of Travel (AVMT), and Annual Average Daily Traffic (AADT). The proposed framework is implemented on the all-street network in the state of Maryland using MDLD for the entire year of 2019. Results indicate that our proposed framework produces reliable vehicle volume estimates and also demonstrate its transferability and the generalization ability.
Decentralized Vehicle Coordination: The Berkeley DeepDrive Drone Dataset
Sep 22, 2022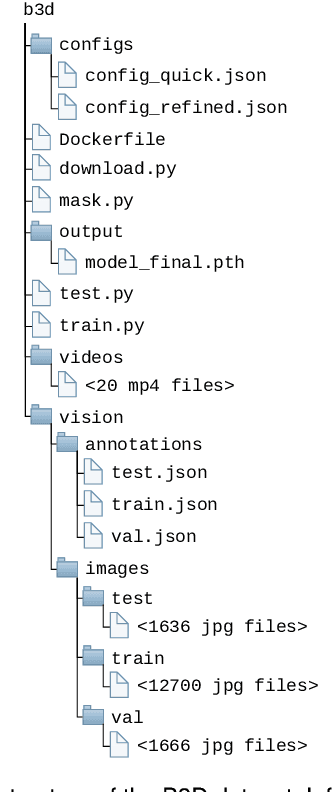
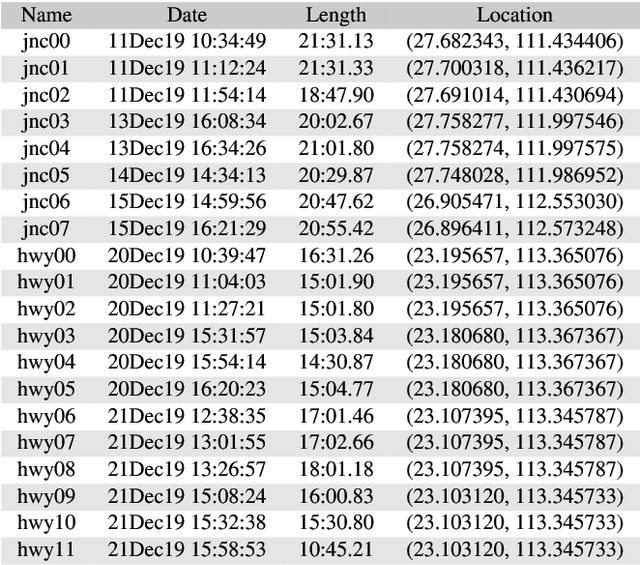


Decentralized multiagent planning has been an important field of research in robotics. An interesting and impactful application in the field is decentralized vehicle coordination in understructured road environments. For example, in an intersection, it is useful yet difficult to deconflict multiple vehicles of intersecting paths in absence of a central coordinator. We learn from common sense that, for a vehicle to navigate through such understructured environments, the driver must understand and conform to the implicit "social etiquette" observed by nearby drivers. To study this implicit driving protocol, we collect the Berkeley DeepDrive Drone dataset. The dataset contains 1) a set of aerial videos recording understructured driving, 2) a collection of images and annotations to train vehicle detection models, and 3) a kit of development scripts for illustrating typical usages. We believe that the dataset is of primary interest for studying decentralized multiagent planning employed by human drivers and, of secondary interest, for computer vision in remote sensing settings.
Pose Guided Image Generation from Misaligned Sources via Residual Flow Based Correction
Feb 02, 2022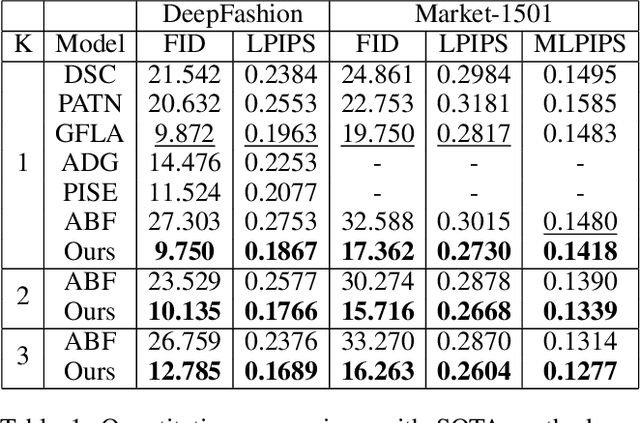
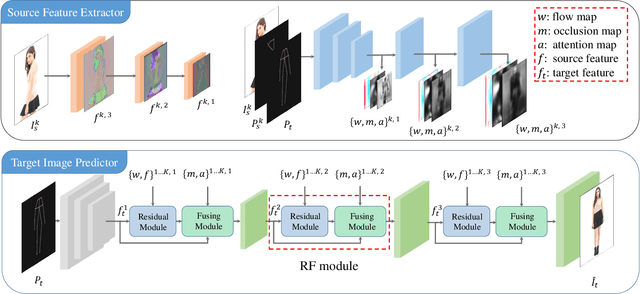
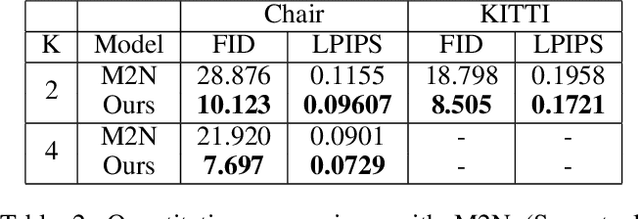
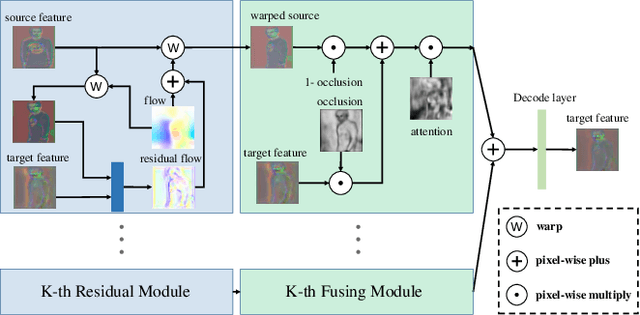
Generating new images with desired properties (e.g. new view/poses) from source images has been enthusiastically pursued recently, due to its wide range of potential applications. One way to ensure high-quality generation is to use multiple sources with complementary information such as different views of the same object. However, as source images are often misaligned due to the large disparities among the camera settings, strong assumptions have been made in the past with respect to the camera(s) or/and the object in interest, limiting the application of such techniques. Therefore, we propose a new general approach which models multiple types of variations among sources, such as view angles, poses, facial expressions, in a unified framework, so that it can be employed on datasets of vastly different nature. We verify our approach on a variety of data including humans bodies, faces, city scenes and 3D objects. Both the qualitative and quantitative results demonstrate the better performance of our method than the state of the art.