 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Air Traffic Safety Assessment Around Non-Towered Airports Using Large Language Models
May 12, 2026We investigate frameworks for post-flight safety analysis at non-towered airports using large language models (LLMs). Non-towered airports rely on the Common Traffic Advisory Frequency (CTAF) for air traffic coordination and experience frequent near mid-air collisions due to the pilot self-announcement communication protocol. We propose a general vision-language model (VLM) approach to analyze the transcribed CTAF radio communications in natural language, METeorological Aerodrome Report (METAR) weather data, Automatic Dependent Surveillance-Broadcast (ADS-B) flight trajectories, and Visual Flight Rules sectional charts of the airfield. We provide a preliminary study at Half Moon Bay Airport, with a qualitative real world case study and a quantitative evaluation using a new synthetic dataset of communications and weather modalities. We qualitatively evaluate our framework on real flight data using Gemini 2.5 Pro, demonstrating accurate identification of a right-of-way violation. The synthetic dataset is derived from real examples and includes a 12-category hazard taxonomy, and is used to benchmark three open-source (Qwen 2.5-7B, Mistral-7B, Gemma-2-9B) and three closed-source (GPT-4o, GPT-5.4, Claude Sonnet 4.6) LLM models on the subset of inputs related to CTAF and METAR. Even limited to CTAF and METAR inputs and open source LLMs, instances of our framework typically achieve a macro F1 score above 0.85 on a binary nominal/danger classification task. Future work includes a quantitative evaluation across all modalities and a larger number of real world examples. Taken together, our results suggest that VLM analysis of safety at non-towered airports may be a valuable future capability.
Unsupervised Anomaly Detection in Multi-Agent Trajectory Prediction via Transformer-Based Models
Jan 28, 2026Identifying safety-critical scenarios is essential for autonomous driving, but the rarity of such events makes supervised labeling impractical. Traditional rule-based metrics like Time-to-Collision are too simplistic to capture complex interaction risks, and existing methods lack a systematic way to verify whether statistical anomalies truly reflect physical danger. To address this gap, we propose an unsupervised anomaly detection framework based on a multi-agent Transformer that models normal driving and measures deviations through prediction residuals. A dual evaluation scheme has been proposed to assess both detection stability and physical alignment: Stability is measured using standard ranking metrics in which Kendall Rank Correlation Coefficient captures rank agreement and Jaccard index captures the consistency of the top-K selected items; Physical alignment is assessed through correlations with established Surrogate Safety Measures (SSM). Experiments on the NGSIM dataset demonstrate our framework's effectiveness: We show that the maximum residual aggregator achieves the highest physical alignment while maintaining stability. Furthermore, our framework identifies 388 unique anomalies missed by Time-to-Collision and statistical baselines, capturing subtle multi-agent risks like reactive braking under lateral drift. The detected anomalies are further clustered into four interpretable risk types, offering actionable insights for simulation and testing.
Reevaluating Policy Gradient Methods for Imperfect-Information Games
Feb 13, 2025In the past decade, motivated by the putative failure of naive self-play deep reinforcement learning (DRL) in adversarial imperfect-information games, researchers have developed numerous DRL algorithms based on fictitious play (FP), double oracle (DO), and counterfactual regret minimization (CFR). In light of recent results of the magnetic mirror descent algorithm, we hypothesize that simpler generic policy gradient methods like PPO are competitive with or superior to these FP, DO, and CFR-based DRL approaches. To facilitate the resolution of this hypothesis, we implement and release the first broadly accessible exact exploitability computations for four large games. Using these games, we conduct the largest-ever exploitability comparison of DRL algorithms for imperfect-information games. Over 5600 training runs, FP, DO, and CFR-based approaches fail to outperform generic policy gradient methods. Code is available at https://github.com/nathanlct/IIG-RL-Benchmark and https://github.com/gabrfarina/exp-a-spiel .
Scalable Learning of Segment-Level Traffic Congestion Functions
May 09, 2024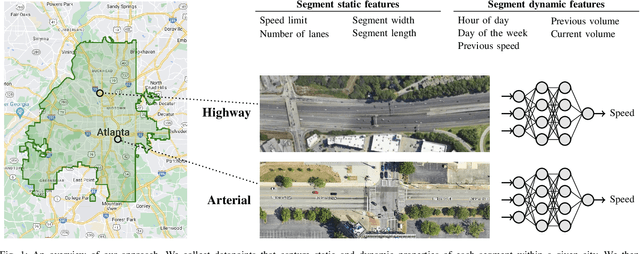
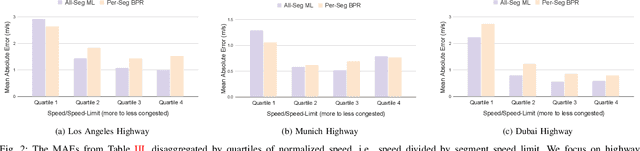
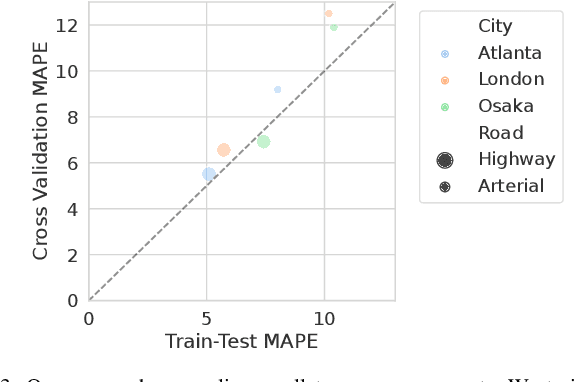
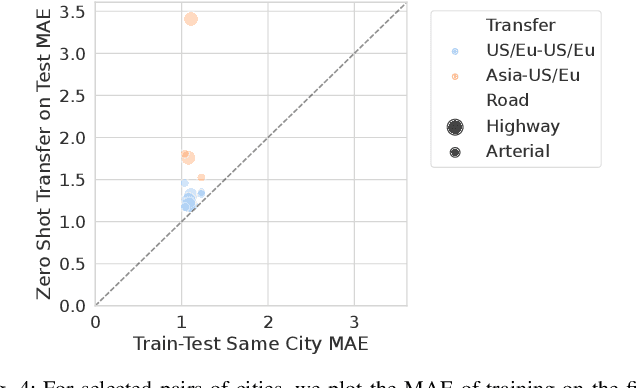
We propose and study a data-driven framework for identifying traffic congestion functions (numerical relationships between observations of macroscopic traffic variables) at global scale and segment-level granularity. In contrast to methods that estimate a separate set of parameters for each roadway, ours learns a single black-box function over all roadways in a metropolitan area. First, we pool traffic data from all segments into one dataset, combining static attributes with dynamic time-dependent features. Second, we train a feed-forward neural network on this dataset, which we can then use on any segment in the area. We evaluate how well our framework identifies congestion functions on observed segments and how it generalizes to unobserved segments and predicts segment attributes on a large dataset covering multiple cities worldwide. For identification error on observed segments, our single data-driven congestion function compares favorably to segment-specific model-based functions on highway roads, but has room to improve on arterial roads. For generalization, our approach shows strong performance across cities and road types: both on unobserved segments in the same city and on zero-shot transfer learning between cities. Finally, for predicting segment attributes, we find that our approach can approximate critical densities for individual segments using their static properties.
Enabling Mixed Autonomy Traffic Control
Oct 28, 2023



We demonstrate a new capability of automated vehicles: mixed autonomy traffic control. With this new capability, automated vehicles can shape the traffic flows composed of other non-automated vehicles, which has the promise to improve safety, efficiency, and energy outcomes in transportation systems at a societal scale. Investigating mixed autonomy mobile traffic control must be done in situ given that the complex dynamics of other drivers and their response to a team of automated vehicles cannot be effectively modeled. This capability has been blocked because there is no existing scalable and affordable platform for experimental control. This paper introduces an extensible open-source hardware and software platform, enabling a team of 100 vehicles to execute several different vehicular control algorithms as a collaborative fleet, composed of three different makes and models, which drove 22752 miles in a combined 1022 hours, over 5 days in Nashville, TN in November 2022.
So you think you can track?
Sep 13, 2023
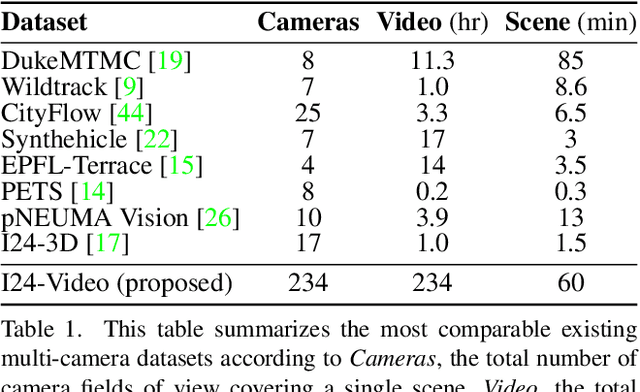


This work introduces a multi-camera tracking dataset consisting of 234 hours of video data recorded concurrently from 234 overlapping HD cameras covering a 4.2 mile stretch of 8-10 lane interstate highway near Nashville, TN. The video is recorded during a period of high traffic density with 500+ objects typically visible within the scene and typical object longevities of 3-15 minutes. GPS trajectories from 270 vehicle passes through the scene are manually corrected in the video data to provide a set of ground-truth trajectories for recall-oriented tracking metrics, and object detections are provided for each camera in the scene (159 million total before cross-camera fusion). Initial benchmarking of tracking-by-detection algorithms is performed against the GPS trajectories, and a best HOTA of only 9.5% is obtained (best recall 75.9% at IOU 0.1, 47.9 average IDs per ground truth object), indicating the benchmarked trackers do not perform sufficiently well at the long temporal and spatial durations required for traffic scene understanding.
Decentralized Vehicle Coordination: The Berkeley DeepDrive Drone Dataset
Sep 22, 2022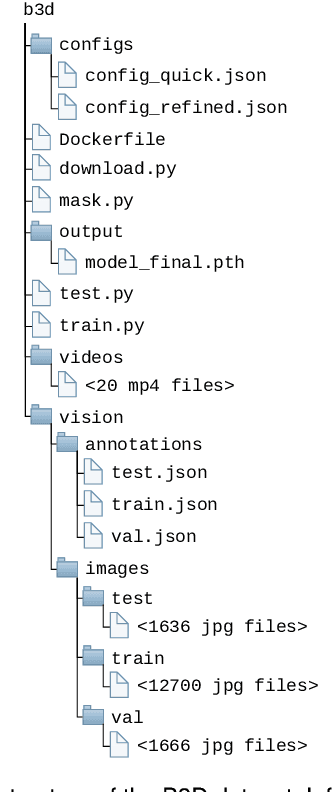


Decentralized multiagent planning has been an important field of research in robotics. An interesting and impactful application in the field is decentralized vehicle coordination in understructured road environments. For example, in an intersection, it is useful yet difficult to deconflict multiple vehicles of intersecting paths in absence of a central coordinator. We learn from common sense that, for a vehicle to navigate through such understructured environments, the driver must understand and conform to the implicit "social etiquette" observed by nearby drivers. To study this implicit driving protocol, we collect the Berkeley DeepDrive Drone dataset. The dataset contains 1) a set of aerial videos recording understructured driving, 2) a collection of images and annotations to train vehicle detection models, and 3) a kit of development scripts for illustrating typical usages. We believe that the dataset is of primary interest for studying decentralized multiagent planning employed by human drivers and, of secondary interest, for computer vision in remote sensing settings.
Multi-Adversarial Safety Analysis for Autonomous Vehicles
Dec 29, 2021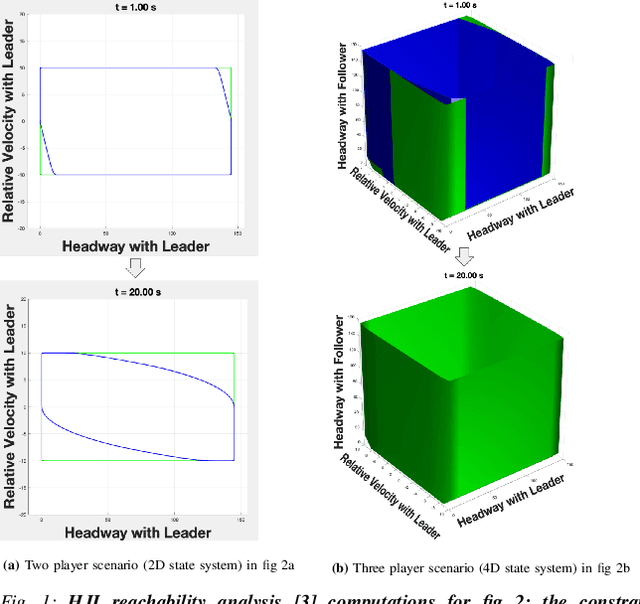

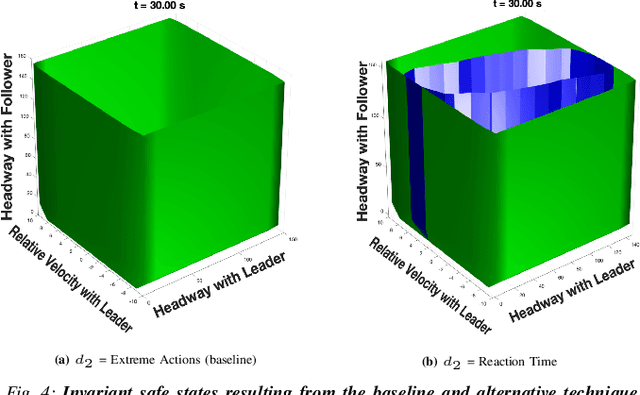
This work in progress considers reachability-based safety analysis in the domain of autonomous driving in multi-agent systems. We formulate the safety problem for a car following scenario as a differential game and study how different modelling strategies yield very different behaviors regardless of the validity of the strategies in other scenarios. Given the nature of real-life driving scenarios, we propose a modeling strategy in our formulation that accounts for subtle interactions between agents, and compare its Hamiltonian results to other baselines. Our formulation encourages reduction of conservativeness in Hamilton-Jacobi safety analysis to provide better safety guarantees during navigation.
The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games
Mar 02, 2021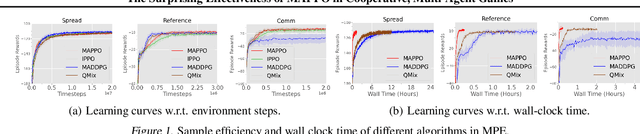
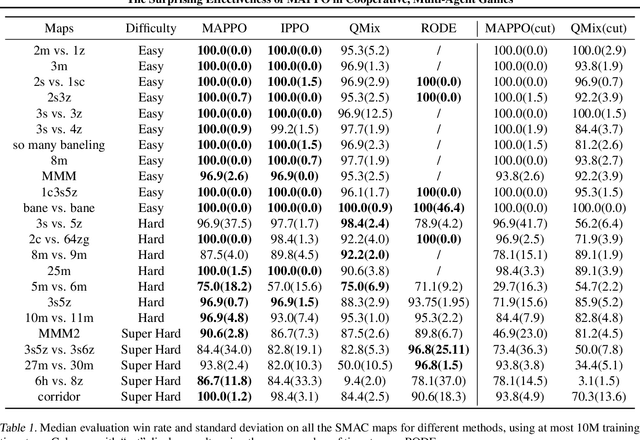
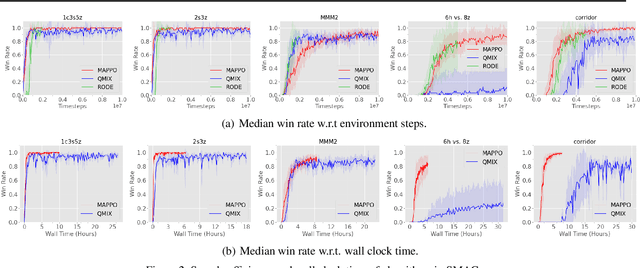
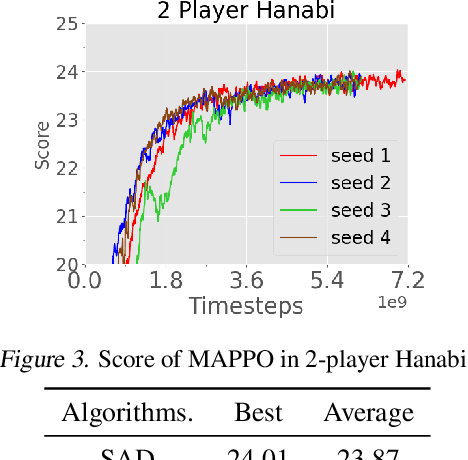
Proximal Policy Optimization (PPO) is a popular on-policy reinforcement learning algorithm but is significantly less utilized than off-policy learning algorithms in multi-agent problems. In this work, we investigate Multi-Agent PPO (MAPPO), a multi-agent PPO variant which adopts a centralized value function. Using a 1-GPU desktop, we show that MAPPO achieves performance comparable to the state-of-the-art in three popular multi-agent testbeds: the Particle World environments, Starcraft II Micromanagement Tasks, and the Hanabi Challenge, with minimal hyperparameter tuning and without any domain-specific algorithmic modifications or architectures. In the majority of environments, we find that compared to off-policy baselines, MAPPO achieves better or comparable sample complexity as well as substantially faster running time. Finally, we present 5 factors most influential to MAPPO's practical performance with ablation studies.
A Graph Convolutional Network with Signal Phasing Information for Arterial Traffic Prediction
Dec 25, 2020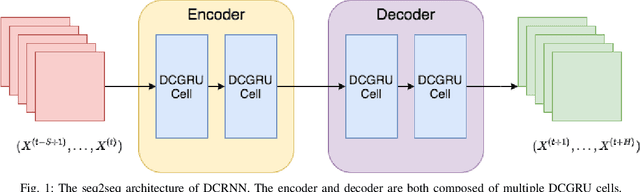
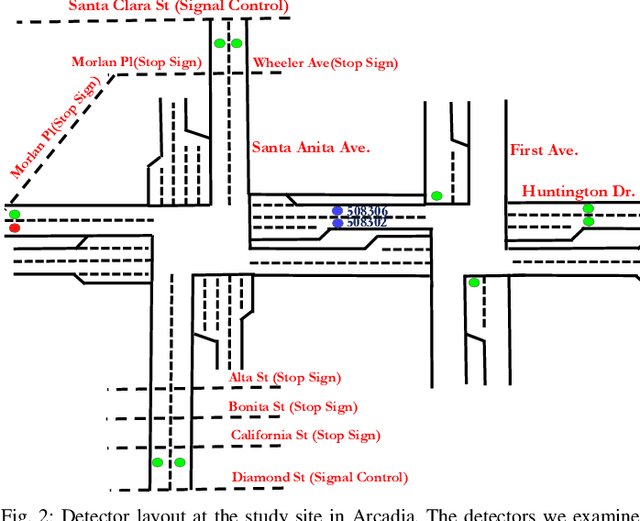
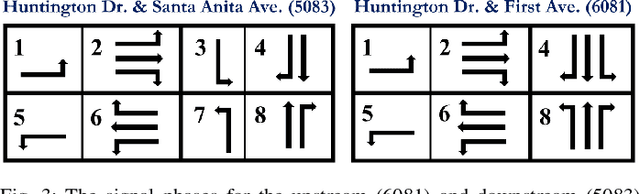
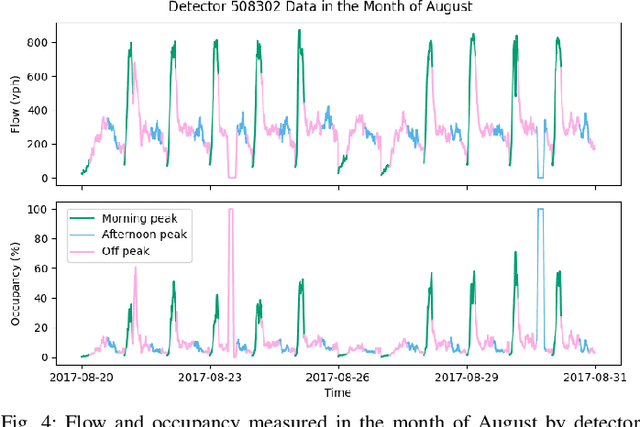
Accurate and reliable prediction of traffic measurements plays a crucial role in the development of modern intelligent transportation systems. Due to more complex road geometries and the presence of signal control, arterial traffic prediction is a level above freeway traffic prediction. Many existing studies on arterial traffic prediction only consider temporal measurements of flow and occupancy from loop sensors and neglect the rich spatial relationships between upstream and downstream detectors. As a result, they often suffer large prediction errors, especially for long horizons. We fill this gap by enhancing a deep learning approach, Diffusion Convolutional Recurrent Neural Network, with spatial information generated from signal timing plans at targeted intersections. Traffic at signalized intersections is modeled as a diffusion process with a transition matrix constructed from the phase splits of the signal phase timing plan. We apply this novel method to predict traffic flow from loop sensor measurements and signal timing plans at an arterial intersection in Arcadia, CA. We demonstrate that our proposed method yields superior forecasts; for a prediction horizon of 30 minutes, we cut the MAPE down to 16% for morning peaks, 10% for off peaks, and even 8% for afternoon peaks. In addition, we exemplify the robustness of our model through a number of experiments with various settings in detector coverage, detector type, and data quality.