 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Adaptive Smoothing Methods for Freeway Traffic Reconstruction
Feb 02, 2026The adaptive smoothing method (ASM) is a widely used approach for traffic state reconstruction. This article presents a Python implementation of ASM, featuring end-to-end calibration using real-world ground truth data. The calibration is formulated as a parameterized kernel optimization problem. The model is calibrated using data from a full-state observation testbed, with input from a sparse radar sensor network. The implementation is developed in PyTorch, enabling integration with various deep learning methods. We evaluate the results in terms of speed distribution, spatio-temporal error distribution, and spatial error to provide benchmark metrics for the traffic reconstruction problem. We further demonstrate the usability of the calibrated method across multiple freeways. Finally, we discuss the challenges of reproducibility in general traffic model calibration and the limitations of ASM. This article is reproducible and can serve as a benchmark for various freeway operation tasks.
Virtual trajectories for I-24 MOTION: data and tools
Nov 17, 2023



This article introduces a new virtual trajectory dataset derived from the I-24 MOTION INCEPTION v1.0.0 dataset to address challenges in analyzing large but noisy trajectory datasets. Building on the concept of virtual trajectories, we provide a Python implementation to generate virtual trajectories from large raw datasets that are typically challenging to process due to their size. We demonstrate the practical utility of these trajectories in assessing speed variability and travel times across different lanes within the INCEPTION dataset. The virtual trajectory dataset opens future research on traffic waves and their impact on energy.
So you think you can track?
Sep 13, 2023
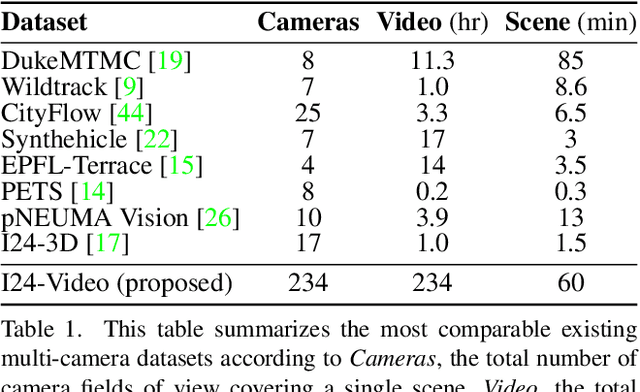


This work introduces a multi-camera tracking dataset consisting of 234 hours of video data recorded concurrently from 234 overlapping HD cameras covering a 4.2 mile stretch of 8-10 lane interstate highway near Nashville, TN. The video is recorded during a period of high traffic density with 500+ objects typically visible within the scene and typical object longevities of 3-15 minutes. GPS trajectories from 270 vehicle passes through the scene are manually corrected in the video data to provide a set of ground-truth trajectories for recall-oriented tracking metrics, and object detections are provided for each camera in the scene (159 million total before cross-camera fusion). Initial benchmarking of tracking-by-detection algorithms is performed against the GPS trajectories, and a best HOTA of only 9.5% is obtained (best recall 75.9% at IOU 0.1, 47.9 average IDs per ground truth object), indicating the benchmarked trackers do not perform sufficiently well at the long temporal and spatial durations required for traffic scene understanding.
Polygon Intersection-over-Union Loss for Viewpoint-Agnostic Monocular 3D Vehicle Detection
Sep 13, 2023



Monocular 3D object detection is a challenging task because depth information is difficult to obtain from 2D images. A subset of viewpoint-agnostic monocular 3D detection methods also do not explicitly leverage scene homography or geometry during training, meaning that a model trained thusly can detect objects in images from arbitrary viewpoints. Such works predict the projections of the 3D bounding boxes on the image plane to estimate the location of the 3D boxes, but these projections are not rectangular so the calculation of IoU between these projected polygons is not straightforward. This work proposes an efficient, fully differentiable algorithm for the calculation of IoU between two convex polygons, which can be utilized to compute the IoU between two 3D bounding box footprints viewed from an arbitrary angle. We test the performance of the proposed polygon IoU loss (PIoU loss) on three state-of-the-art viewpoint-agnostic 3D detection models. Experiments demonstrate that the proposed PIoU loss converges faster than L1 loss and that in 3D detection models, a combination of PIoU loss and L1 loss gives better results than L1 loss alone (+1.64% AP70 for MonoCon on cars, +0.18% AP70 for RTM3D on cars, and +0.83%/+2.46% AP50/AP25 for MonoRCNN on cyclists).
The Interstate-24 3D Dataset: a new benchmark for 3D multi-camera vehicle tracking
Aug 28, 2023



This work presents a novel video dataset recorded from overlapping highway traffic cameras along an urban interstate, enabling multi-camera 3D object tracking in a traffic monitoring context. Data is released from 3 scenes containing video from at least 16 cameras each, totaling 57 minutes in length. 877,000 3D bounding boxes and corresponding object tracklets are fully and accurately annotated for each camera field of view and are combined into a spatially and temporally continuous set of vehicle trajectories for each scene. Lastly, existing algorithms are combined to benchmark a number of 3D multi-camera tracking pipelines on the dataset, with results indicating that the dataset is challenging due to the difficulty of matching objects traveling at high speeds across cameras and heavy object occlusion, potentially for hundreds of frames, during congested traffic. This work aims to enable the development of accurate and automatic vehicle trajectory extraction algorithms, which will play a vital role in understanding impacts of autonomous vehicle technologies on the safety and efficiency of traffic.
I-24 MOTION: An instrument for freeway traffic science
Jan 30, 2023



The Interstate-24 MObility Technology Interstate Observation Network (I-24 MOTION) is a new instrument for traffic science located near Nashville, Tennessee. I-24 MOTION consists of 276 pole-mounted high-resolution traffic cameras that provide seamless coverage of approximately 4.2 miles I-24, a 4-5 lane (each direction) freeway with frequently observed congestion. The cameras are connected via fiber optic network to a compute facility where vehicle trajectories are extracted from the video imagery using computer vision techniques. Approximately 230 million vehicle miles of travel occur within I-24 MOTION annually. The main output of the instrument are vehicle trajectory datasets that contain the position of each vehicle on the freeway, as well as other supplementary information vehicle dimensions and class. This article describes the design and creation of the instrument, and provides the first publicly available datasets generated from the instrument. The datasets published with this article contains at least 4 hours of vehicle trajectory data for each of 10 days. As the system continues to mature, all trajectory data will be made publicly available at i24motion.org/data.
Automatic vehicle trajectory data reconstruction at scale
Dec 15, 2022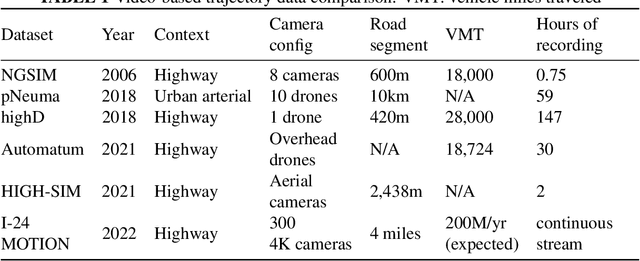
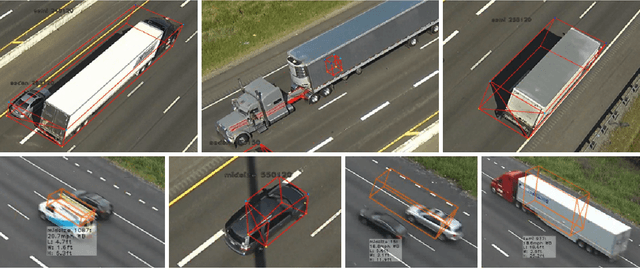
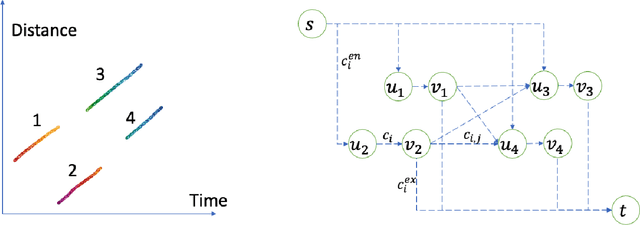

Vehicle trajectory data has received increasing research attention over the past decades. With the technological sensing improvements such as high-resolution video cameras, in-vehicle radars and lidars, abundant individual and contextual traffic data is now available. However, though the data quantity is massive, it is by itself of limited utility for traffic research because of noise and systematic sensing errors, thus necessitates proper processing to ensure data quality. We draw particular attention to extracting high-resolution vehicle trajectory data from video cameras as traffic monitoring cameras are becoming increasingly ubiquitous. We explore methods for automatic trajectory data reconciliation, given "raw" vehicle detection and tracking information from automatic video processing algorithms. We propose a pipeline including a) an online data association algorithm to match fragments that are associated to the same object (vehicle), which is formulated as a min-cost network flow problem of a graph, and b) a trajectory reconciliation method formulated as a quadratic program to enhance raw detection data. The pipeline leverages vehicle dynamics and physical constraints to associate tracked objects when they become fragmented, remove measurement noise on trajectories and impute missing data due to fragmentations. The accuracy is benchmarked on a sample of manually-labeled data, which shows that the reconciled trajectories improve the accuracy on all the tested input data for a wide range of measures. An online version of the reconciliation pipeline is implemented and will be applied in a continuous video processing system running on a camera network covering a 4-mile stretch of Interstate-24 near Nashville, Tennessee.
Localization-Based Tracking
Apr 12, 2021

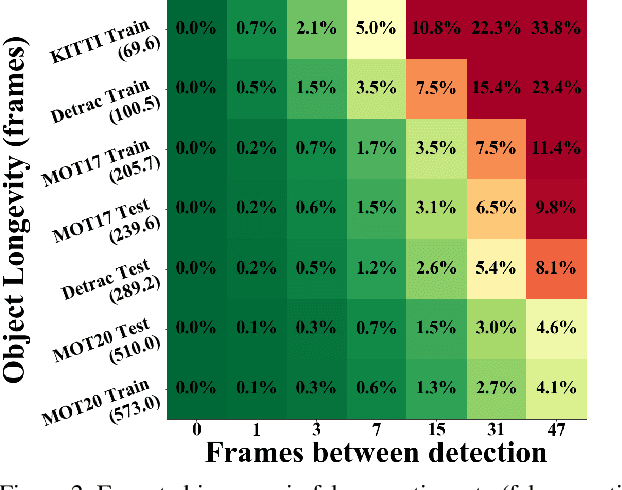
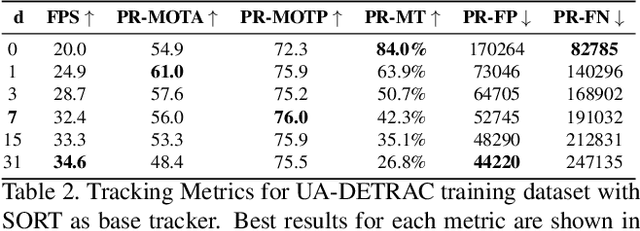
End-to-end production of object tracklets from high resolution video in real-time and with high accuracy remains a challenging problem due to the cost of object detection on each frame. In this work we present Localization-based Tracking (LBT), an extension to any tracker that follows the tracking by detection or joint detection and tracking paradigms. Localization-based Tracking focuses only on regions likely to contain objects to boost detection speed and avoid matching errors. We evaluate LBT as an extension to two example trackers (KIOU and SORT) on the UA-DETRAC and MOT20 datasets. LBT-extended trackers outperform all other reported algorithms in terms of PR-MOTA, PR-MOTP, and mostly tracked objects on the UA-DETRAC benchmark, establishing a new state-of-the art. relative to tracking by detection with KIOU, LBT-extended KIOU achieves a 25% higher frame-rate and is 1.1% more accurate in terms of PR-MOTA on the UA-DETRAC dataset. LBT-extended SORT achieves a 62% speedup and a 3.2% increase in PR-MOTA on the UA-DETRAC dataset. On MOT20, LBT-extended KIOU has a 50% higher frame-rate than tracking by detection and is 0.4% more accurate in terms of MOTA. As of submission time, our LBT-extended KIOU tracker places 10th overall on the MOT20 benchmark.