 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Think Var-by-Var: Large Language Models Enable Ad Hoc Probabilistic Reasoning
Dec 03, 2024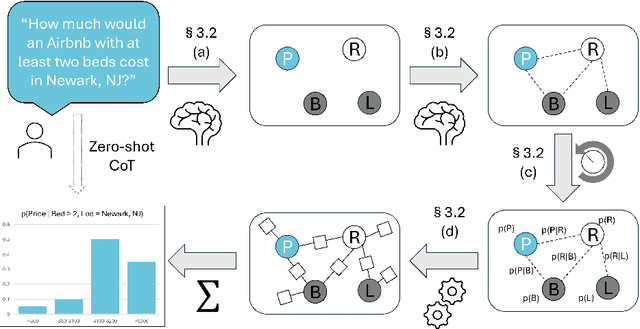

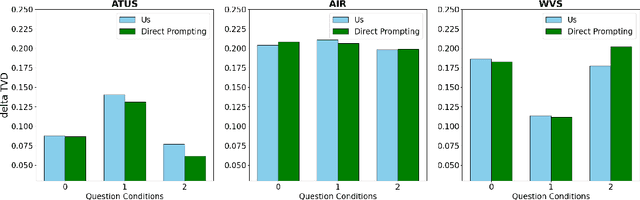

A hallmark of intelligence is the ability to flesh out underspecified situations using "common sense." We propose to extract that common sense from large language models (LLMs), in a form that can feed into probabilistic inference. We focus our investigation on $\textit{guesstimation}$ questions such as "How much are Airbnb listings in Newark, NJ?" Formulating a sensible answer without access to data requires drawing on, and integrating, bits of common knowledge about how $\texttt{Price}$ and $\texttt{Location}$ may relate to other variables, such as $\texttt{Property Type}$. Our framework answers such a question by synthesizing an $\textit{ad hoc}$ probabilistic model. First we prompt an LLM to propose a set of random variables relevant to the question, followed by moment constraints on their joint distribution. We then optimize the joint distribution $p$ within a log-linear family to maximize the overall constraint satisfaction. Our experiments show that LLMs can successfully be prompted to propose reasonable variables, and while the proposed numerical constraints can be noisy, jointly optimizing for their satisfaction reconciles them. When evaluated on probabilistic questions derived from three real-world tabular datasets, we find that our framework performs comparably to a direct prompting baseline in terms of total variation distance from the dataset distribution, and is similarly robust to noise.
Polygon Intersection-over-Union Loss for Viewpoint-Agnostic Monocular 3D Vehicle Detection
Sep 13, 2023



Monocular 3D object detection is a challenging task because depth information is difficult to obtain from 2D images. A subset of viewpoint-agnostic monocular 3D detection methods also do not explicitly leverage scene homography or geometry during training, meaning that a model trained thusly can detect objects in images from arbitrary viewpoints. Such works predict the projections of the 3D bounding boxes on the image plane to estimate the location of the 3D boxes, but these projections are not rectangular so the calculation of IoU between these projected polygons is not straightforward. This work proposes an efficient, fully differentiable algorithm for the calculation of IoU between two convex polygons, which can be utilized to compute the IoU between two 3D bounding box footprints viewed from an arbitrary angle. We test the performance of the proposed polygon IoU loss (PIoU loss) on three state-of-the-art viewpoint-agnostic 3D detection models. Experiments demonstrate that the proposed PIoU loss converges faster than L1 loss and that in 3D detection models, a combination of PIoU loss and L1 loss gives better results than L1 loss alone (+1.64% AP70 for MonoCon on cars, +0.18% AP70 for RTM3D on cars, and +0.83%/+2.46% AP50/AP25 for MonoRCNN on cyclists).