 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games
Paper and Code
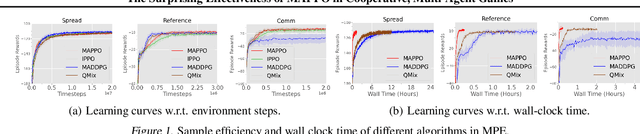
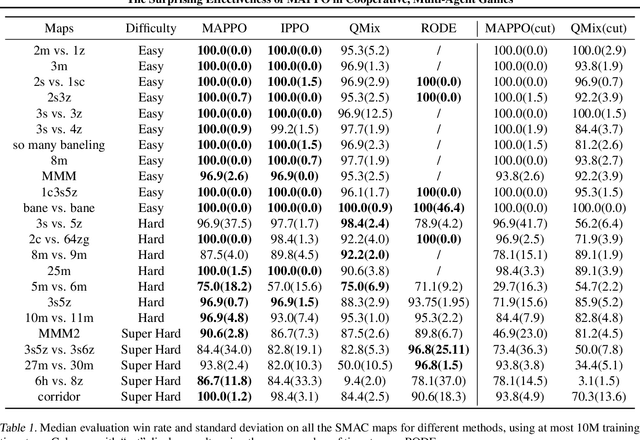
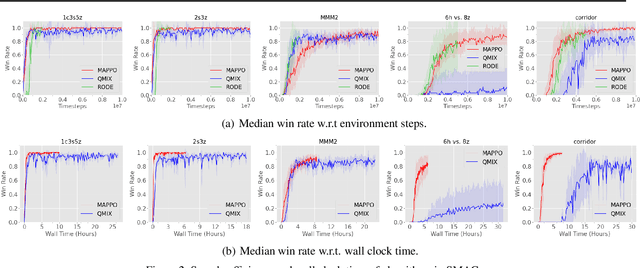
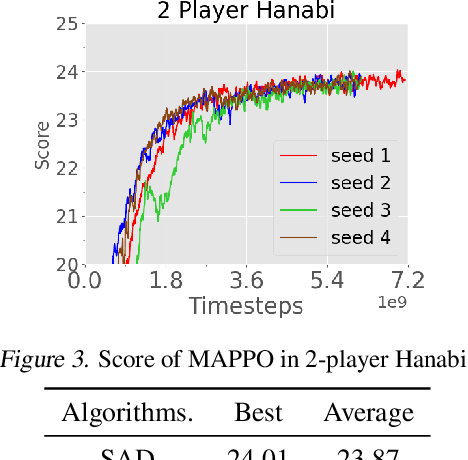
Proximal Policy Optimization (PPO) is a popular on-policy reinforcement learning algorithm but is significantly less utilized than off-policy learning algorithms in multi-agent problems. In this work, we investigate Multi-Agent PPO (MAPPO), a multi-agent PPO variant which adopts a centralized value function. Using a 1-GPU desktop, we show that MAPPO achieves performance comparable to the state-of-the-art in three popular multi-agent testbeds: the Particle World environments, Starcraft II Micromanagement Tasks, and the Hanabi Challenge, with minimal hyperparameter tuning and without any domain-specific algorithmic modifications or architectures. In the majority of environments, we find that compared to off-policy baselines, MAPPO achieves better or comparable sample complexity as well as substantially faster running time. Finally, we present 5 factors most influential to MAPPO's practical performance with ablation studies.