 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Weight Masks for Domain Transfer
Aug 26, 2023

One of the major drawbacks of deep learning models for computer vision has been their inability to retain multiple sources of information in a modular fashion. For instance, given a network that has been trained on a source task, we would like to re-train this network on a similar, yet different, target task while maintaining its performance on the source task. Simultaneously, researchers have extensively studied modularization of network weights to localize and identify the set of weights culpable for eliciting the observed performance on a given task. One set of works studies the modularization induced in the weights of a neural network by learning and analysing weight masks. In this work, we combine these fields to study three such weight masking methods and analyse their ability to mitigate "forgetting'' on the source task while also allowing for efficient finetuning on the target task. We find that different masking techniques have trade-offs in retaining knowledge in the source task without adversely affecting target task performance.
Hindsight-DICE: Stable Credit Assignment for Deep Reinforcement Learning
Jul 21, 2023Oftentimes, environments for sequential decision-making problems can be quite sparse in the provision of evaluative feedback to guide reinforcement-learning agents. In the extreme case, long trajectories of behavior are merely punctuated with a single terminal feedback signal, engendering a significant temporal delay between the observation of non-trivial reward and the individual steps of behavior culpable for eliciting such feedback. Coping with such a credit assignment challenge is one of the hallmark characteristics of reinforcement learning and, in this work, we capitalize on existing importance-sampling ratio estimation techniques for off-policy evaluation to drastically improve the handling of credit assignment with policy-gradient methods. While the use of so-called hindsight policies offers a principled mechanism for reweighting on-policy data by saliency to the observed trajectory return, naively applying importance sampling results in unstable or excessively lagged learning. In contrast, our hindsight distribution correction facilitates stable, efficient learning across a broad range of environments where credit assignment plagues baseline methods.
Avoiding Catastrophe: Active Dendrites Enable Multi-Task Learning in Dynamic Environments
Dec 31, 2021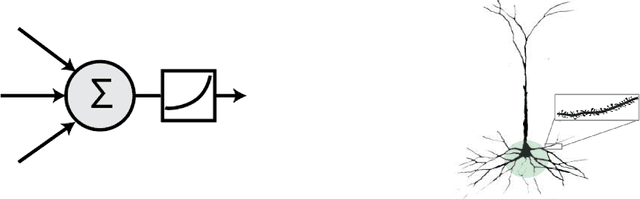
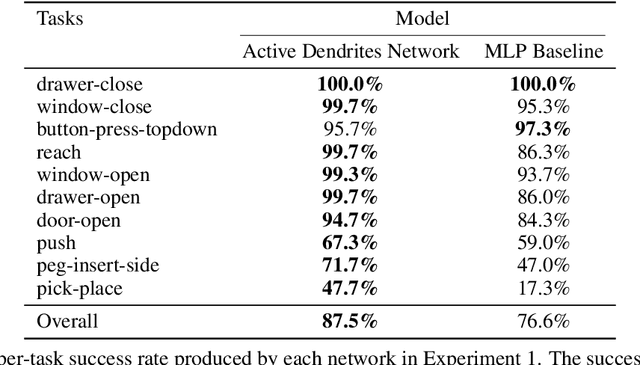
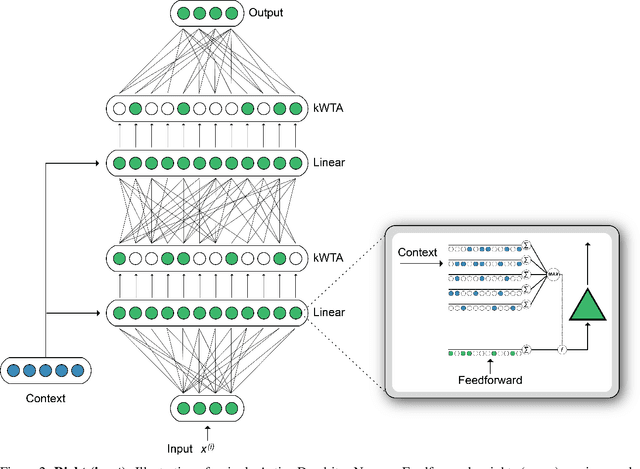

A key challenge for AI is to build embodied systems that operate in dynamically changing environments. Such systems must adapt to changing task contexts and learn continuously. Although standard deep learning systems achieve state of the art results on static benchmarks, they often struggle in dynamic scenarios. In these settings, error signals from multiple contexts can interfere with one another, ultimately leading to a phenomenon known as catastrophic forgetting. In this article we investigate biologically inspired architectures as solutions to these problems. Specifically, we show that the biophysical properties of dendrites and local inhibitory systems enable networks to dynamically restrict and route information in a context-specific manner. Our key contributions are as follows. First, we propose a novel artificial neural network architecture that incorporates active dendrites and sparse representations into the standard deep learning framework. Next, we study the performance of this architecture on two separate benchmarks requiring task-based adaptation: Meta-World, a multi-task reinforcement learning environment where a robotic agent must learn to solve a variety of manipulation tasks simultaneously; and a continual learning benchmark in which the model's prediction task changes throughout training. Analysis on both benchmarks demonstrates the emergence of overlapping but distinct and sparse subnetworks, allowing the system to fluidly learn multiple tasks with minimal forgetting. Our neural implementation marks the first time a single architecture has achieved competitive results on both multi-task and continual learning settings. Our research sheds light on how biological properties of neurons can inform deep learning systems to address dynamic scenarios that are typically impossible for traditional ANNs to solve.
The Surprising Effectiveness of MAPPO in Cooperative, Multi-Agent Games
Mar 02, 2021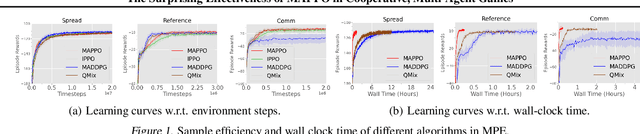
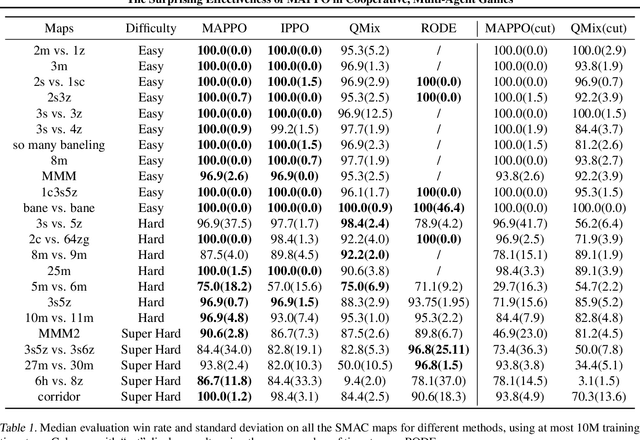
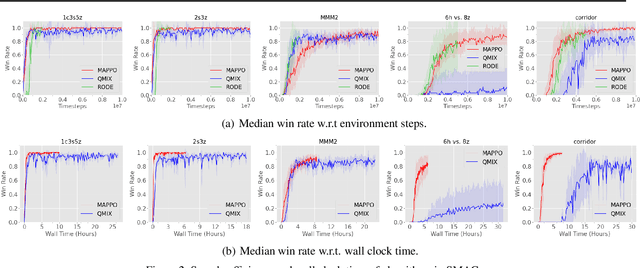
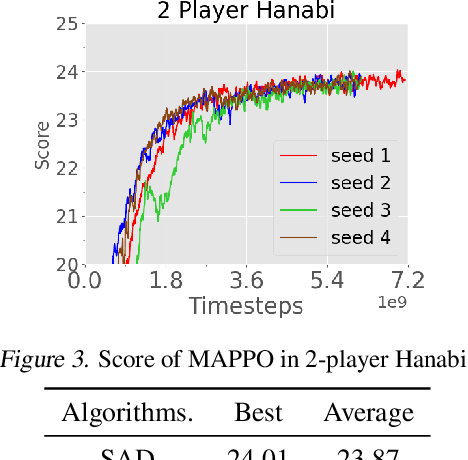
Proximal Policy Optimization (PPO) is a popular on-policy reinforcement learning algorithm but is significantly less utilized than off-policy learning algorithms in multi-agent problems. In this work, we investigate Multi-Agent PPO (MAPPO), a multi-agent PPO variant which adopts a centralized value function. Using a 1-GPU desktop, we show that MAPPO achieves performance comparable to the state-of-the-art in three popular multi-agent testbeds: the Particle World environments, Starcraft II Micromanagement Tasks, and the Hanabi Challenge, with minimal hyperparameter tuning and without any domain-specific algorithmic modifications or architectures. In the majority of environments, we find that compared to off-policy baselines, MAPPO achieves better or comparable sample complexity as well as substantially faster running time. Finally, we present 5 factors most influential to MAPPO's practical performance with ablation studies.