 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Catastrophe: Active Dendrites Enable Multi-Task Learning in Dynamic Environments
Dec 31, 2021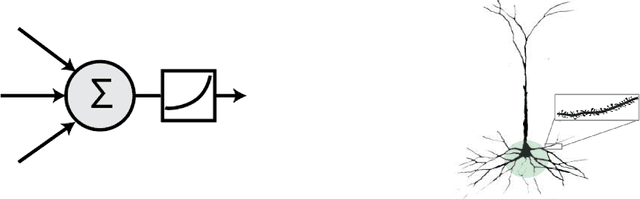
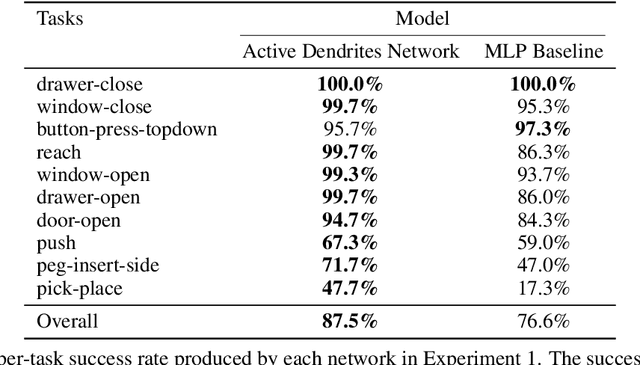
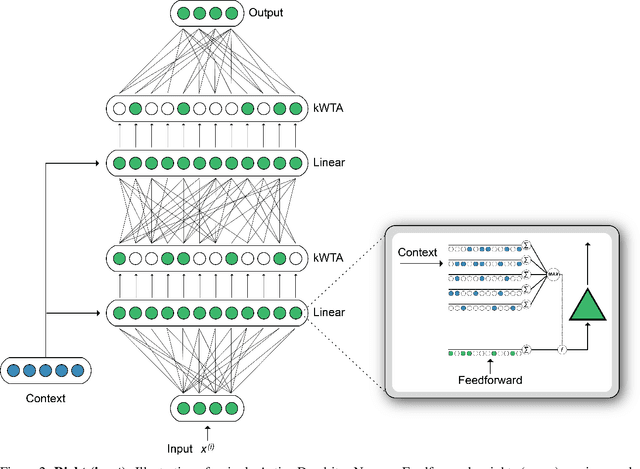

A key challenge for AI is to build embodied systems that operate in dynamically changing environments. Such systems must adapt to changing task contexts and learn continuously. Although standard deep learning systems achieve state of the art results on static benchmarks, they often struggle in dynamic scenarios. In these settings, error signals from multiple contexts can interfere with one another, ultimately leading to a phenomenon known as catastrophic forgetting. In this article we investigate biologically inspired architectures as solutions to these problems. Specifically, we show that the biophysical properties of dendrites and local inhibitory systems enable networks to dynamically restrict and route information in a context-specific manner. Our key contributions are as follows. First, we propose a novel artificial neural network architecture that incorporates active dendrites and sparse representations into the standard deep learning framework. Next, we study the performance of this architecture on two separate benchmarks requiring task-based adaptation: Meta-World, a multi-task reinforcement learning environment where a robotic agent must learn to solve a variety of manipulation tasks simultaneously; and a continual learning benchmark in which the model's prediction task changes throughout training. Analysis on both benchmarks demonstrates the emergence of overlapping but distinct and sparse subnetworks, allowing the system to fluidly learn multiple tasks with minimal forgetting. Our neural implementation marks the first time a single architecture has achieved competitive results on both multi-task and continual learning settings. Our research sheds light on how biological properties of neurons can inform deep learning systems to address dynamic scenarios that are typically impossible for traditional ANNs to solve.
Learning deep representations by mutual information estimation and maximization
Oct 03, 2018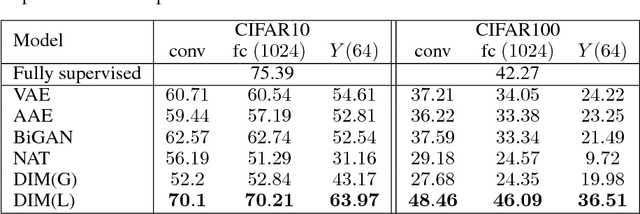
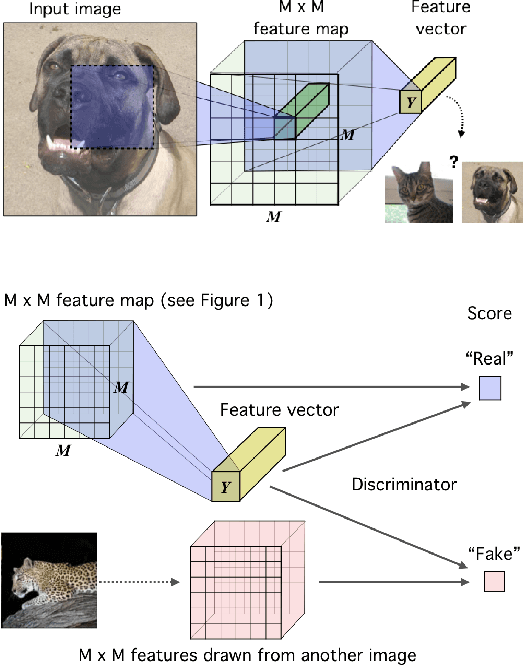
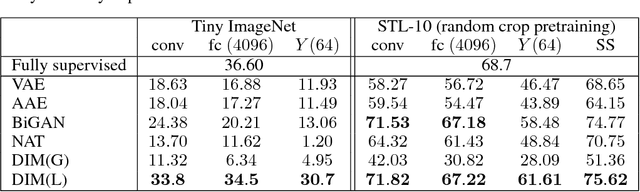
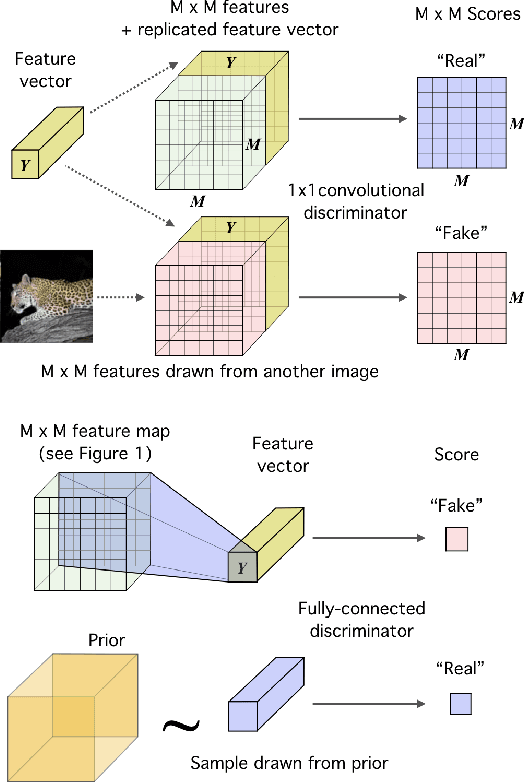
In this work, we perform unsupervised learning of representations by maximizing mutual information between an input and the output of a deep neural network encoder. Importantly, we show that structure matters: incorporating knowledge about locality of the input to the objective can greatly influence a representation's suitability for downstream tasks. We further control characteristics of the representation by matching to a prior distribution adversarially. Our method, which we call Deep InfoMax (DIM), outperforms a number of popular unsupervised learning methods and competes with fully-supervised learning on several classification tasks. DIM opens new avenues for unsupervised learning of representations and is an important step towards flexible formulations of representation-learning objectives for specific end-goals.
Variance Regularizing Adversarial Learning
Aug 19, 2018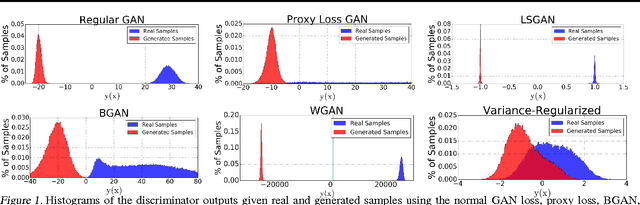

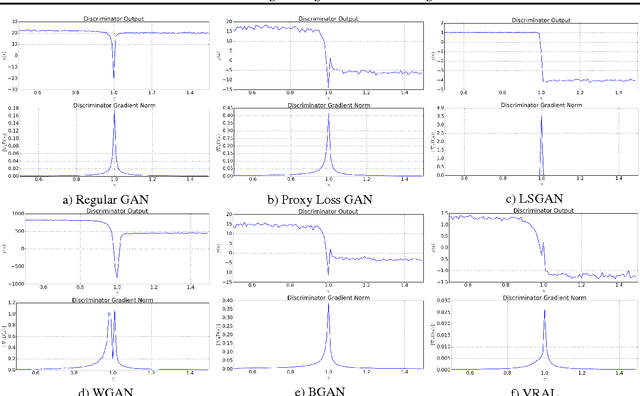

We introduce a novel approach for training adversarial models by replacing the discriminator score with a bi-modal Gaussian distribution over the real/fake indicator variables. In order to do this, we train the Gaussian classifier to match the target bi-modal distribution implicitly through meta-adversarial training. We hypothesize that this approach ensures a non-zero gradient to the generator, even in the limit of a perfect classifier. We test our method against standard benchmark image datasets as well as show the classifier output distribution is smooth and has overlap between the real and fake modes.
On the Challenges of Detecting Rude Conversational Behaviour
Dec 28, 2017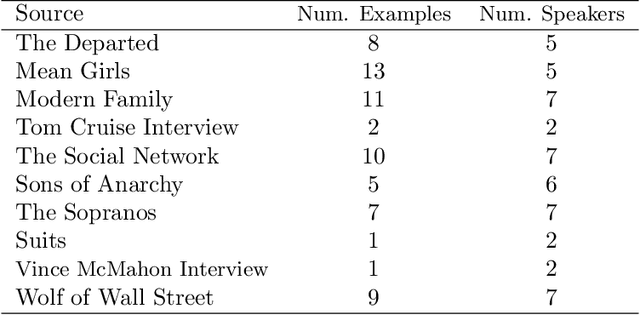
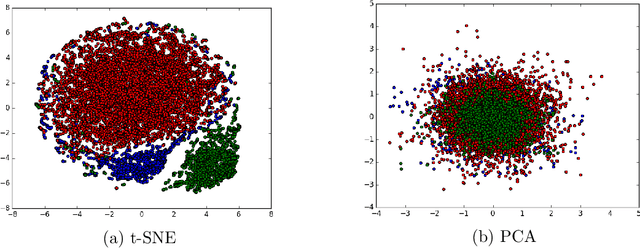

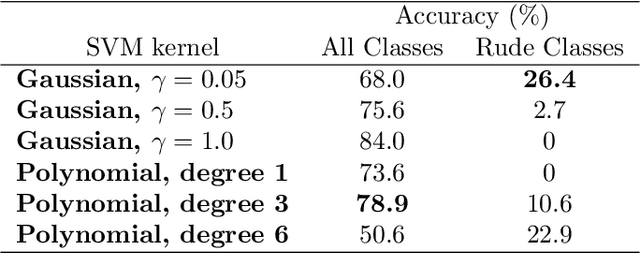
In this study, we aim to identify moments of rudeness between two individuals. In particular, we segment all occurrences of rudeness in conversations into three broad, distinct categories and try to identify each. We show how machine learning algorithms can be used to identify rudeness based on acoustic and semantic signals extracted from conversations. Furthermore, we make note of our shortcomings in this task and highlight what makes this problem inherently difficult. Finally, we provide next steps which are needed to ensure further success in identifying rudeness in conversations.