 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Catastrophe: Active Dendrites Enable Multi-Task Learning in Dynamic Environments
Dec 31, 2021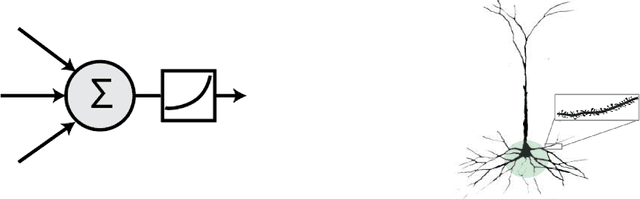
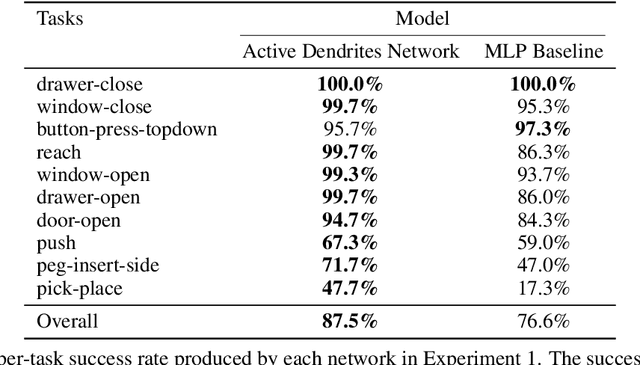
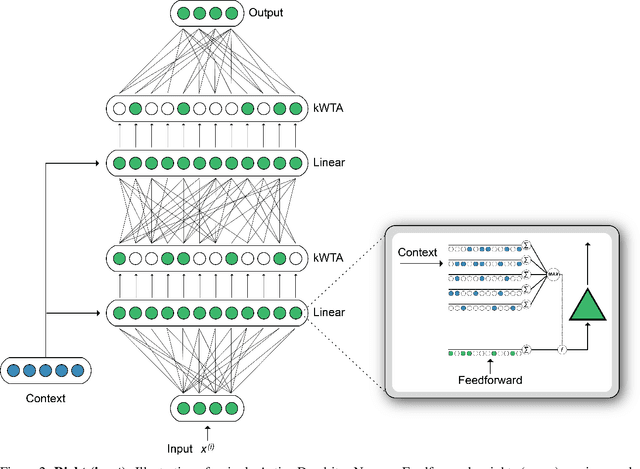

A key challenge for AI is to build embodied systems that operate in dynamically changing environments. Such systems must adapt to changing task contexts and learn continuously. Although standard deep learning systems achieve state of the art results on static benchmarks, they often struggle in dynamic scenarios. In these settings, error signals from multiple contexts can interfere with one another, ultimately leading to a phenomenon known as catastrophic forgetting. In this article we investigate biologically inspired architectures as solutions to these problems. Specifically, we show that the biophysical properties of dendrites and local inhibitory systems enable networks to dynamically restrict and route information in a context-specific manner. Our key contributions are as follows. First, we propose a novel artificial neural network architecture that incorporates active dendrites and sparse representations into the standard deep learning framework. Next, we study the performance of this architecture on two separate benchmarks requiring task-based adaptation: Meta-World, a multi-task reinforcement learning environment where a robotic agent must learn to solve a variety of manipulation tasks simultaneously; and a continual learning benchmark in which the model's prediction task changes throughout training. Analysis on both benchmarks demonstrates the emergence of overlapping but distinct and sparse subnetworks, allowing the system to fluidly learn multiple tasks with minimal forgetting. Our neural implementation marks the first time a single architecture has achieved competitive results on both multi-task and continual learning settings. Our research sheds light on how biological properties of neurons can inform deep learning systems to address dynamic scenarios that are typically impossible for traditional ANNs to solve.
Experience Sharing Between Cooperative Reinforcement Learning Agents
Nov 06, 2019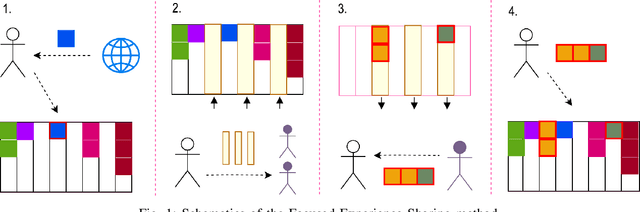


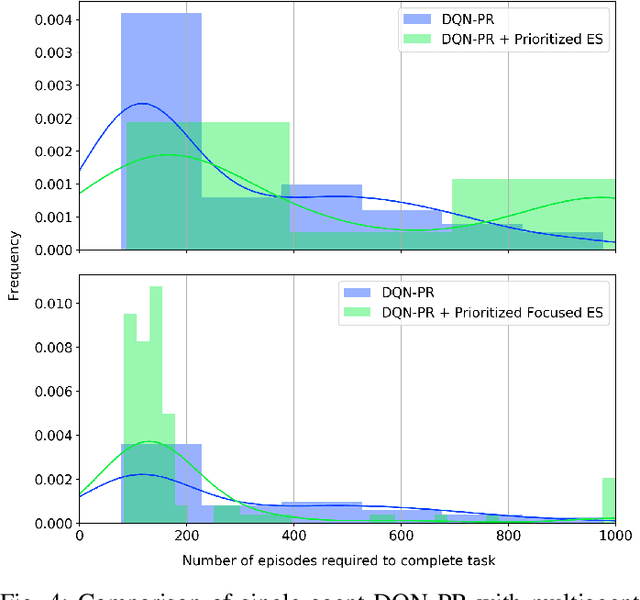
The idea of experience sharing between cooperative agents naturally emerges from our understanding of how humans learn. Our evolution as a species is tightly linked to the ability to exchange learned knowledge with one another. It follows that experience sharing (ES) between autonomous and independent agents could become the key to accelerate learning in cooperative multiagent settings. We investigate if randomly selecting experiences to share can increase the performance of deep reinforcement learning agents, and propose three new methods for selecting experiences to accelerate the learning process. Firstly, we introduce Focused ES, which prioritizes unexplored regions of the state space. Secondly, we present Prioritized ES, in which temporal-difference error is used as a measure of priority. Finally, we devise Focused Prioritized ES, which combines both previous approaches. The methods are empirically validated in a control problem. While sharing randomly selected experiences between two Deep Q-Network agents shows no improvement over a single agent baseline, we show that the proposed ES methods can successfully outperform the baseline. In particular, the Focused ES accelerates learning by a factor of 2, reducing by 51% the number of episodes required to complete the task.