 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Catastrophe: Active Dendrites Enable Multi-Task Learning in Dynamic Environments
Dec 31, 2021
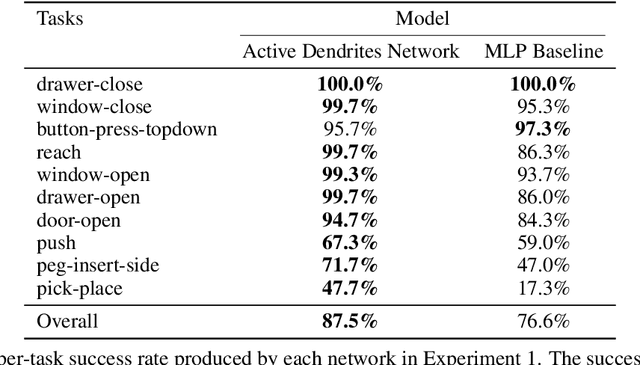
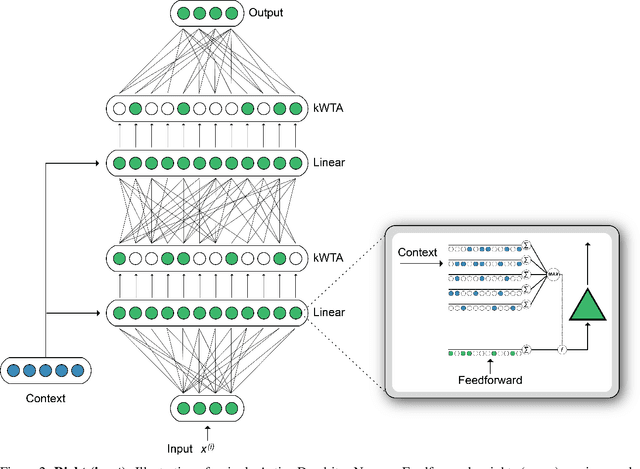

A key challenge for AI is to build embodied systems that operate in dynamically changing environments. Such systems must adapt to changing task contexts and learn continuously. Although standard deep learning systems achieve state of the art results on static benchmarks, they often struggle in dynamic scenarios. In these settings, error signals from multiple contexts can interfere with one another, ultimately leading to a phenomenon known as catastrophic forgetting. In this article we investigate biologically inspired architectures as solutions to these problems. Specifically, we show that the biophysical properties of dendrites and local inhibitory systems enable networks to dynamically restrict and route information in a context-specific manner. Our key contributions are as follows. First, we propose a novel artificial neural network architecture that incorporates active dendrites and sparse representations into the standard deep learning framework. Next, we study the performance of this architecture on two separate benchmarks requiring task-based adaptation: Meta-World, a multi-task reinforcement learning environment where a robotic agent must learn to solve a variety of manipulation tasks simultaneously; and a continual learning benchmark in which the model's prediction task changes throughout training. Analysis on both benchmarks demonstrates the emergence of overlapping but distinct and sparse subnetworks, allowing the system to fluidly learn multiple tasks with minimal forgetting. Our neural implementation marks the first time a single architecture has achieved competitive results on both multi-task and continual learning settings. Our research sheds light on how biological properties of neurons can inform deep learning systems to address dynamic scenarios that are typically impossible for traditional ANNs to solve.
Two Sparsities Are Better Than One: Unlocking the Performance Benefits of Sparse-Sparse Networks
Dec 27, 2021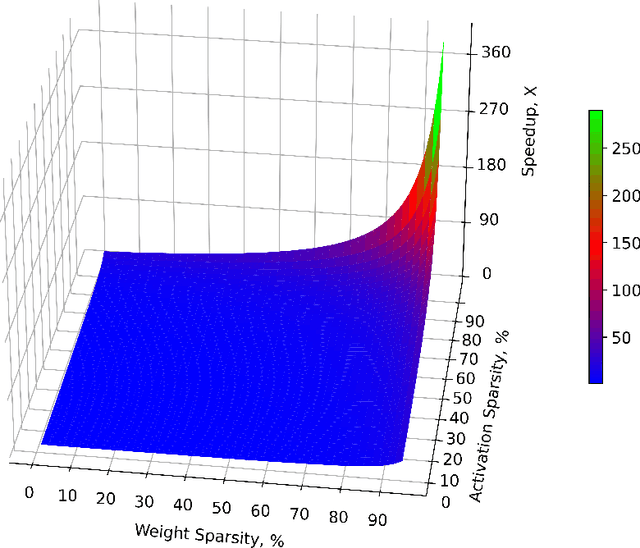
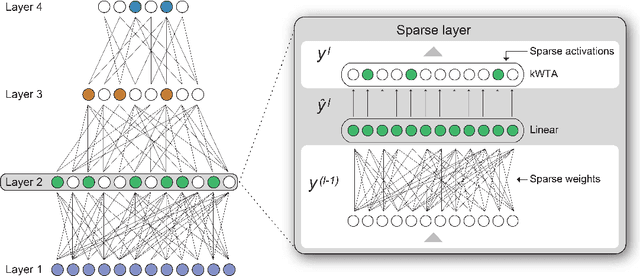

In principle, sparse neural networks should be significantly more efficient than traditional dense networks. Neurons in the brain exhibit two types of sparsity; they are sparsely interconnected and sparsely active. These two types of sparsity, called weight sparsity and activation sparsity, when combined, offer the potential to reduce the computational cost of neural networks by two orders of magnitude. Despite this potential, today's neural networks deliver only modest performance benefits using just weight sparsity, because traditional computing hardware cannot efficiently process sparse networks. In this article we introduce Complementary Sparsity, a novel technique that significantly improves the performance of dual sparse networks on existing hardware. We demonstrate that we can achieve high performance running weight-sparse networks, and we can multiply those speedups by incorporating activation sparsity. Using Complementary Sparsity, we show up to 100X improvement in throughput and energy efficiency performing inference on FPGAs. We analyze scalability and resource tradeoffs for a variety of kernels typical of commercial convolutional networks such as ResNet-50 and MobileNetV2. Our results with Complementary Sparsity suggest that weight plus activation sparsity can be a potent combination for efficiently scaling future AI models.
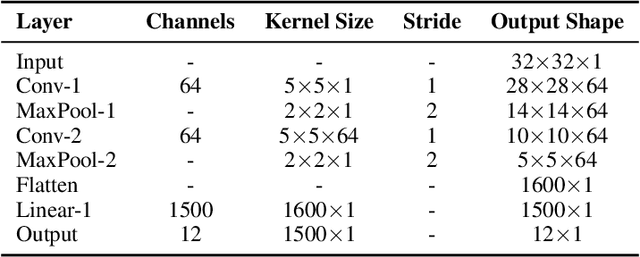
Grid Cell Path Integration For Movement-Based Visual Object Recognition
Feb 17, 2021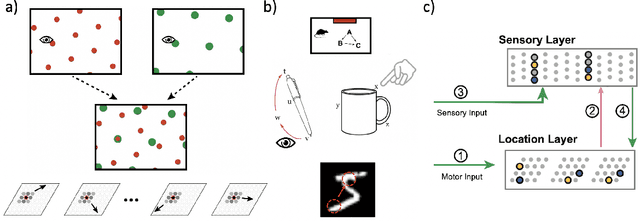
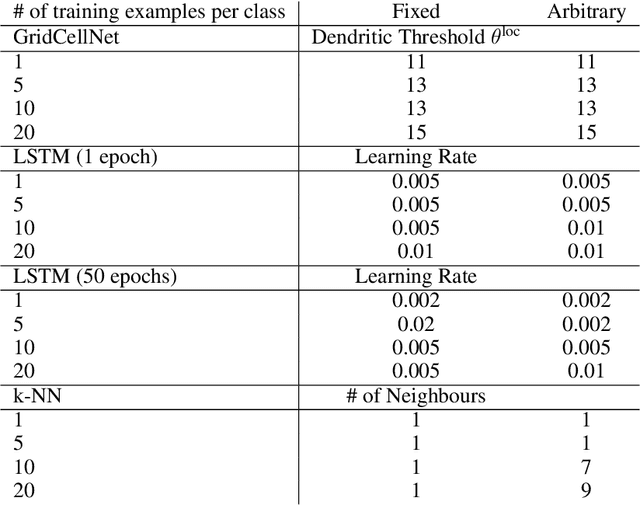
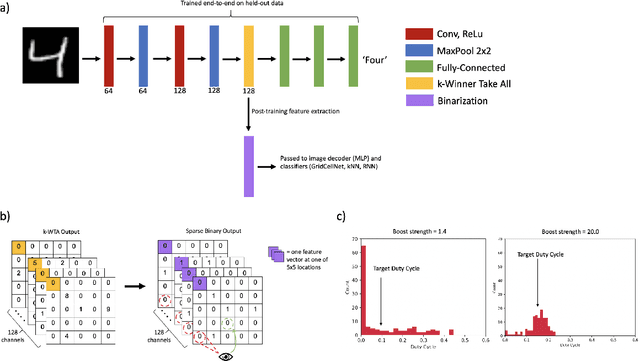
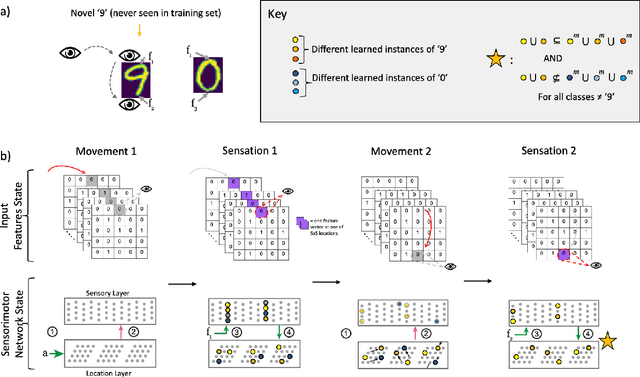
Grid cells enable the brain to model the physical space of the world and navigate effectively via path integration, updating self-position using information from self-movement. Recent proposals suggest that the brain might use similar mechanisms to understand the structure of objects in diverse sensory modalities, including vision. In machine vision, object recognition given a sequence of sensory samples of an image, such as saccades, is a challenging problem when the sequence does not follow a consistent, fixed pattern - yet this is something humans do naturally and effortlessly. We explore how grid cell-based path integration in a cortical network can support reliable recognition of objects given an arbitrary sequence of inputs. Our network (GridCellNet) uses grid cell computations to integrate visual information and make predictions based on movements. We use local Hebbian plasticity rules to learn rapidly from a handful of examples (few-shot learning), and consider the task of recognizing MNIST digits given only a sequence of image feature patches. We compare GridCellNet to k-Nearest Neighbour (k-NN) classifiers as well as recurrent neural networks (RNNs), both of which lack explicit mechanisms for handling arbitrary sequences of input samples. We show that GridCellNet can reliably perform classification, generalizing to both unseen examples and completely novel sequence trajectories. We further show that inference is often successful after sampling a fraction of the input space, enabling the predictive GridCellNet to reconstruct the rest of the image given just a few movements. We propose that dynamically moving agents with active sensors can use grid cell representations not only for navigation, but also for efficient recognition and feature prediction of seen objects.
Long Distance Relationships without Time Travel: Boosting the Performance of a Sparse Predictive Autoencoder in Sequence Modeling
Dec 02, 2019
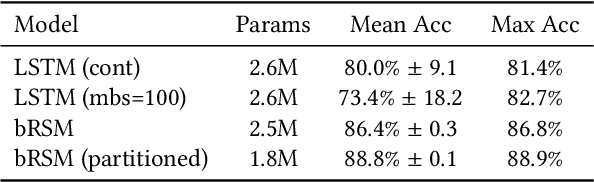

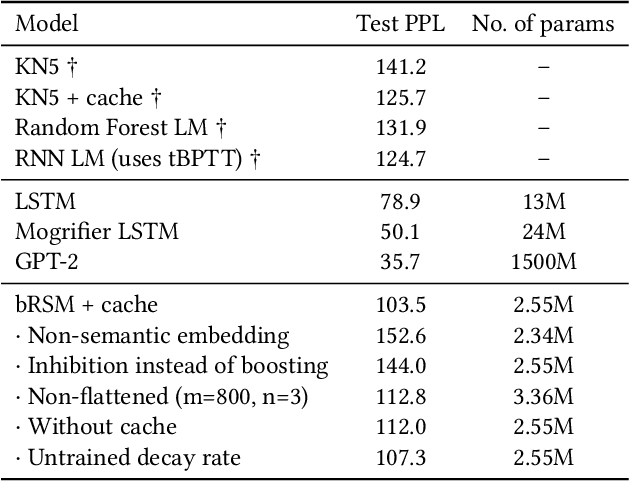
In sequence learning tasks such as language modelling, Recurrent Neural Networks must learn relationships between input features separated by time. State of the art models such as LSTM and Transformer are trained by backpropagation of losses into prior hidden states and inputs held in memory. This allows gradients to flow from present to past and effectively learn with perfect hindsight, but at a significant memory cost. In this paper we show that it is possible to train high performance recurrent networks using information that is local in time, and thereby achieve a significantly reduced memory footprint. We describe a predictive autoencoder called bRSM featuring recurrent connections, sparse activations, and a boosting rule for improved cell utilization. The architecture demonstrates near optimal performance on a non-deterministic (stochastic) partially-observable sequence learning task consisting of high-Markov-order sequences of MNIST digits. We find that this model learns these sequences faster and more completely than an LSTM, and offer several possible explanations why the LSTM architecture might struggle with the partially observable sequence structure in this task. We also apply our model to a next word prediction task on the Penn Treebank (PTB) dataset. We show that a 'flattened' RSM network, when paired with a modern semantic word embedding and the addition of boosting, achieves 103.5 PPL (a 20-point improvement over the best N-gram models), beating ordinary RNNs trained with BPTT and approaching the scores of early LSTM implementations. This work provides encouraging evidence that strong results on challenging tasks such as language modelling may be possible using less memory intensive, biologically-plausible training regimes.
How Can We Be So Dense? The Benefits of Using Highly Sparse Representations
Apr 02, 2019
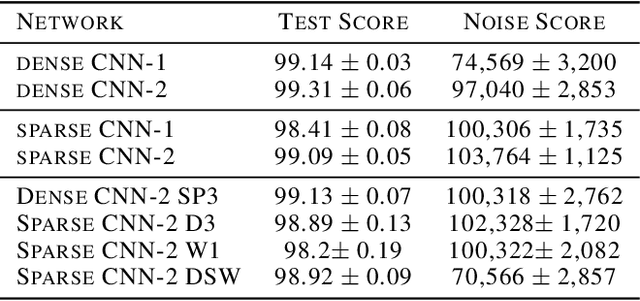
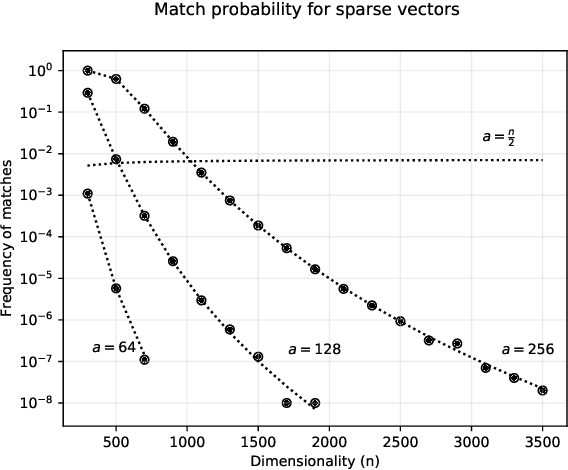

Most artificial networks today rely on dense representations, whereas biological networks rely on sparse representations. In this paper we show how sparse representations can be more robust to noise and interference, as long as the underlying dimensionality is sufficiently high. A key intuition that we develop is that the ratio of the operable volume around a sparse vector divided by the volume of the representational space decreases exponentially with dimensionality. We then analyze computationally efficient sparse networks containing both sparse weights and activations. Simulations on MNIST and the Google Speech Command Dataset show that such networks demonstrate significantly improved robustness and stability compared to dense networks, while maintaining competitive accuracy. We discuss the potential benefits of sparsity on accuracy, noise robustness, hyperparameter tuning, learning speed, computational efficiency, and power requirements.
Real-Time Anomaly Detection for Streaming Analytics
Jul 08, 2016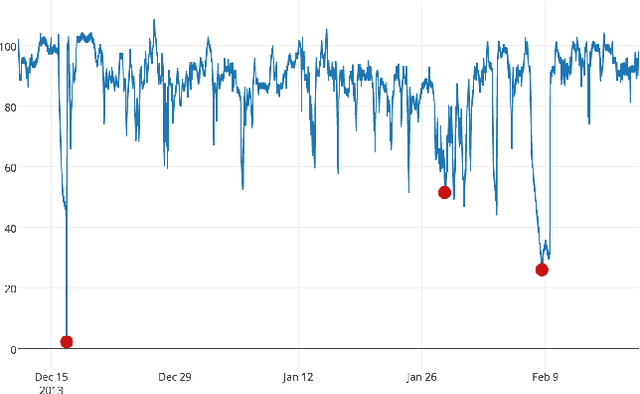
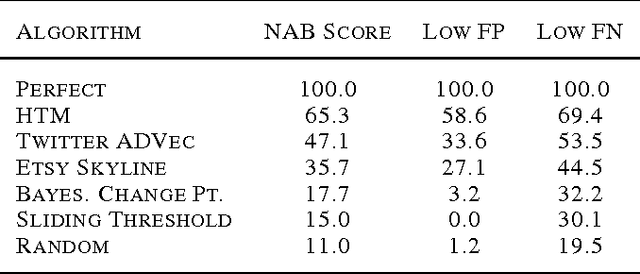
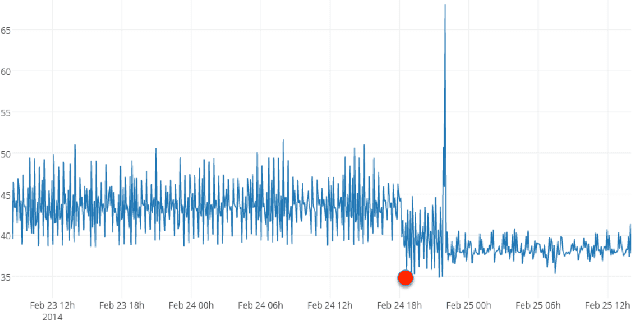

Much of the worlds data is streaming, time-series data, where anomalies give significant information in critical situations. Yet detecting anomalies in streaming data is a difficult task, requiring detectors to process data in real-time, and learn while simultaneously making predictions. We present a novel anomaly detection technique based on an on-line sequence memory algorithm called Hierarchical Temporal Memory (HTM). We show results from a live application that detects anomalies in financial metrics in real-time. We also test the algorithm on NAB, a published benchmark for real-time anomaly detection, where our algorithm achieves best-in-class results.
How do neurons operate on sparse distributed representations? A mathematical theory of sparsity, neurons and active dendrites
May 13, 2016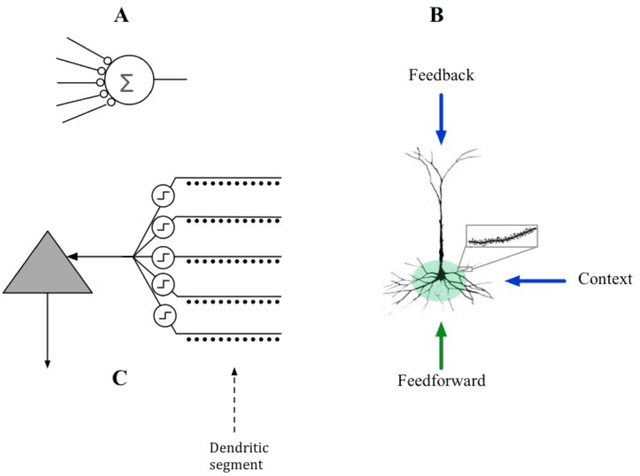
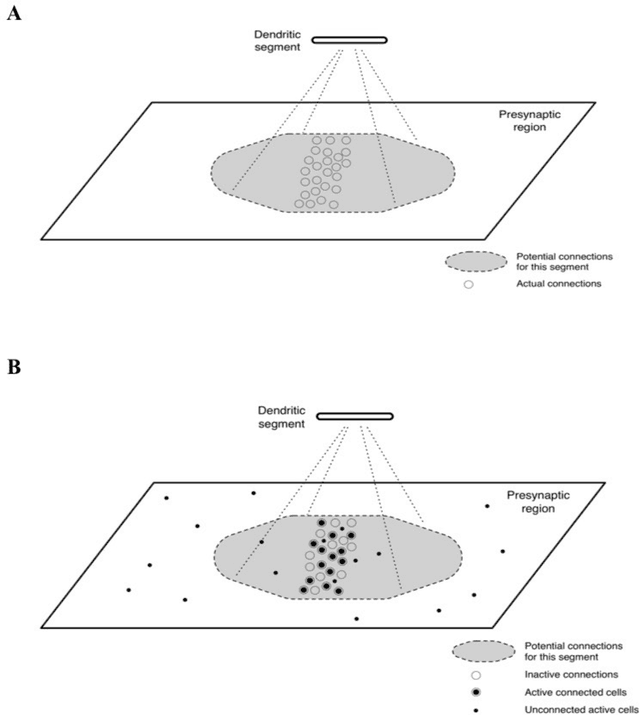
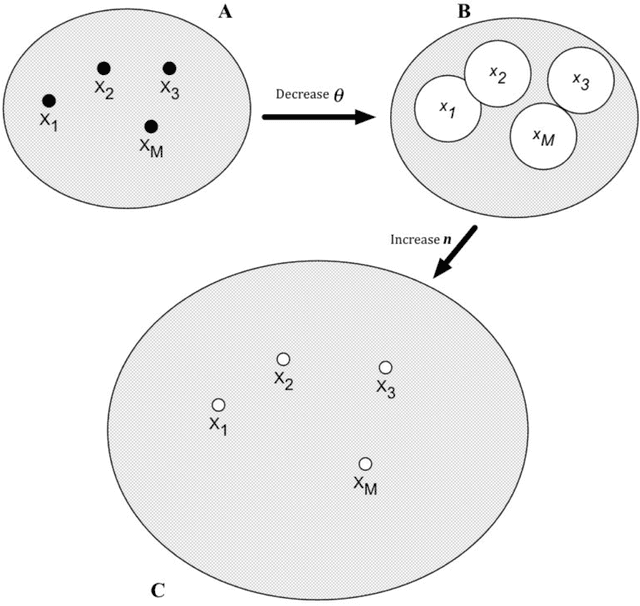
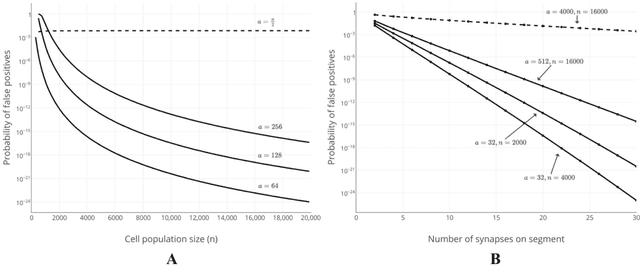
We propose a formal mathematical model for sparse representations and active dendrites in neocortex. Our model is inspired by recent experimental findings on active dendritic processing and NMDA spikes in pyramidal neurons. These experimental and modeling studies suggest that the basic unit of pattern memory in the neocortex is instantiated by small clusters of synapses operated on by localized non-linear dendritic processes. We derive a number of scaling laws that characterize the accuracy of such dendrites in detecting activation patterns in a neuronal population under adverse conditions. We introduce the union property which shows that synapses for multiple patterns can be randomly mixed together within a segment and still lead to highly accurate recognition. We describe simulation results that provide further insight into sparse representations as well as two primary results. First we show that pattern recognition by a neuron with active dendrites can be extremely accurate and robust with high dimensional sparse inputs even when using a tiny number of synapses to recognize large patterns. Second, equations representing recognition accuracy of a dendrite predict optimal NMDA spiking thresholds under a generous set of assumptions. The prediction tightly matches NMDA spiking thresholds measured in the literature. Our model matches many of the known properties of pyramidal neurons. As such the theory provides a mathematical framework for understanding the benefits and limits of sparse representations in cortical networks.
Continuous online sequence learning with an unsupervised neural network model
Apr 28, 2016The ability to recognize and predict temporal sequences of sensory inputs is vital for survival in natural environments. Based on many known properties of cortical neurons, hierarchical temporal memory (HTM) sequence memory is recently proposed as a theoretical framework for sequence learning in the cortex. In this paper, we analyze properties of HTM sequence memory and apply it to sequence learning and prediction problems with streaming data. We show the model is able to continuously learn a large number of variable-order temporal sequences using an unsupervised Hebbian-like learning rule. The sparse temporal codes formed by the model can robustly handle branching temporal sequences by maintaining multiple predictions until there is sufficient disambiguating evidence. We compare the HTM sequence memory with other sequence learning algorithms, including statistical methods: autoregressive integrated moving average (ARIMA), feedforward neural networks: online sequential extreme learning machine (ELM), and recurrent neural networks: long short-term memory (LSTM) and echo-state networks (ESN), on sequence prediction problems with both artificial and real-world data. The HTM model achieves comparable accuracy to other state-of-the-art algorithms. The model also exhibits properties that are critical for sequence learning, including continuous online learning, the ability to handle multiple predictions and branching sequences with high order statistics, robustness to sensor noise and fault tolerance, and good performance without task-specific hyper- parameters tuning. Therefore the HTM sequence memory not only advances our understanding of how the brain may solve the sequence learning problem, but is also applicable to a wide range of real-world problems such as discrete and continuous sequence prediction, anomaly detection, and sequence classification.
Porting HTM Models to the Heidelberg Neuromorphic Computing Platform
Feb 09, 2016
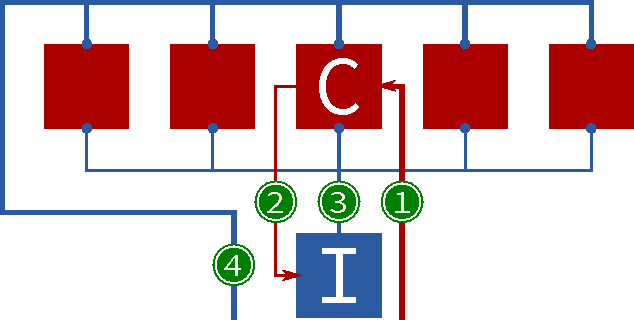


Hierarchical Temporal Memory (HTM) is a computational theory of machine intelligence based on a detailed study of the neocortex. The Heidelberg Neuromorphic Computing Platform, developed as part of the Human Brain Project (HBP), is a mixed-signal (analog and digital) large-scale platform for modeling networks of spiking neurons. In this paper we present the first effort in porting HTM networks to this platform. We describe a framework for simulating key HTM operations using spiking network models. We then describe specific spatial pooling and temporal memory implementations, as well as simulations demonstrating that the fundamental properties are maintained. We discuss issues in implementing the full set of plasticity rules using Spike-Timing Dependent Plasticity (STDP), and rough place and route calculations. Although further work is required, our initial studies indicate that it should be possible to run large-scale HTM networks (including plasticity rules) efficiently on the Heidelberg platform. More generally the exercise of porting high level HTM algorithms to biophysical neuron models promises to be a fruitful area of investigation for future studies.
Why Neurons Have Thousands of Synapses, A Theory of Sequence Memory in Neocortex
Dec 01, 2015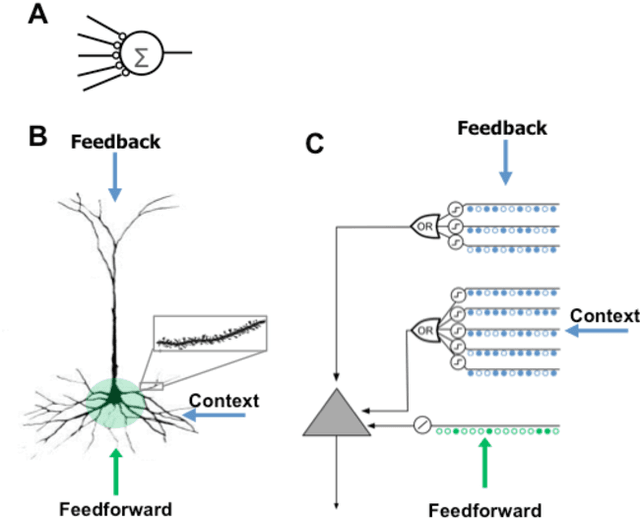
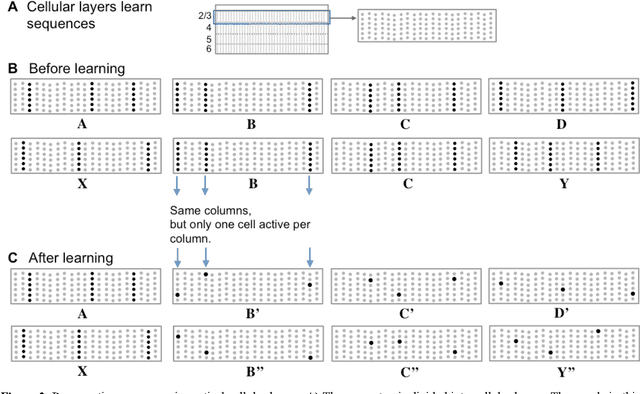
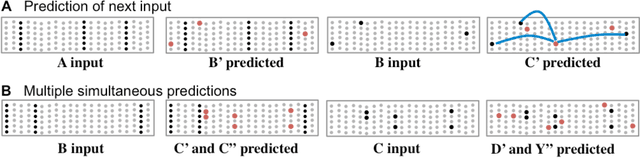
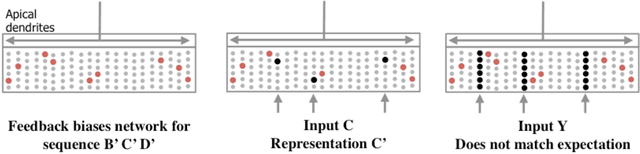
Neocortical neurons have thousands of excitatory synapses. It is a mystery how neurons integrate the input from so many synapses and what kind of large-scale network behavior this enables. It has been previously proposed that non-linear properties of dendrites enable neurons to recognize multiple patterns. In this paper we extend this idea by showing that a neuron with several thousand synapses arranged along active dendrites can learn to accurately and robustly recognize hundreds of unique patterns of cellular activity, even in the presence of large amounts of noise and pattern variation. We then propose a neuron model where some of the patterns recognized by a neuron lead to action potentials and define the classic receptive field of the neuron, whereas the majority of the patterns recognized by a neuron act as predictions by slightly depolarizing the neuron without immediately generating an action potential. We then present a network model based on neurons with these properties and show that the network learns a robust model of time-based sequences. Given the similarity of excitatory neurons throughout the neocortex and the importance of sequence memory in inference and behavior, we propose that this form of sequence memory is a universal property of neocortical tissue. We further propose that cellular layers in the neocortex implement variations of the same sequence memory algorithm to achieve different aspects of inference and behavior. The neuron and network models we introduce are robust over a wide range of parameters as long as the network uses a sparse distributed code of cellular activations. The sequence capacity of the network scales linearly with the number of synapses on each neuron. Thus neurons need thousands of synapses to learn the many temporal patterns in sensory stimuli and motor sequences.
* Submitted for publication