 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHippocampal Spatial Mapping As Fast Graph Learning
Jul 01, 2021

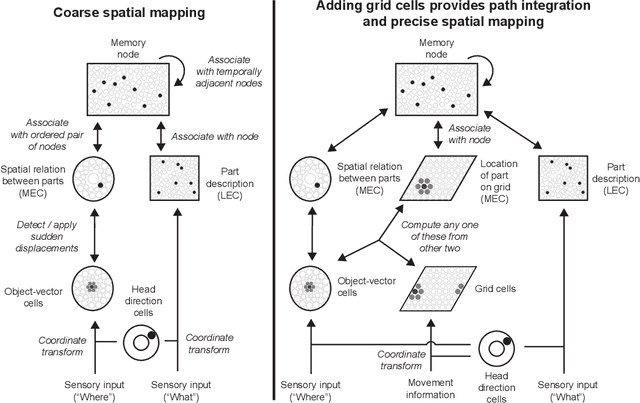

The hippocampal formation is thought to learn spatial maps of environments, and in many models this learning process consists of forming a sensory association for each location in the environment. This is inefficient, akin to learning a large lookup table for each environment. Spatial maps can be learned much more efficiently if the maps instead consist of arrangements of sparse environment parts. In this work, I approach spatial mapping as a problem of learning graphs of environment parts. Each node in the learned graph, represented by hippocampal engram cells, is associated with feature information in lateral entorhinal cortex (LEC) and location information in medial entorhinal cortex (MEC) using empirically observed neuron types. Each edge in the graph represents the relation between two parts, and it is associated with coarse displacement information. This core idea of associating arbitrary information with nodes and edges is not inherently spatial, so this proposed fast-relation-graph-learning algorithm can expand to incorporate many spatial and non-spatial tasks.
Grid Cell Path Integration For Movement-Based Visual Object Recognition
Feb 17, 2021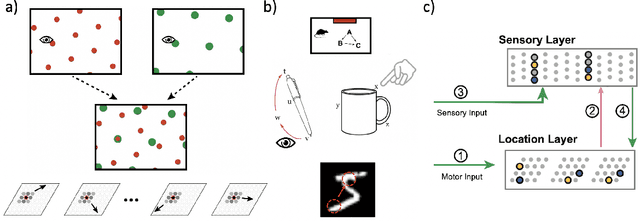
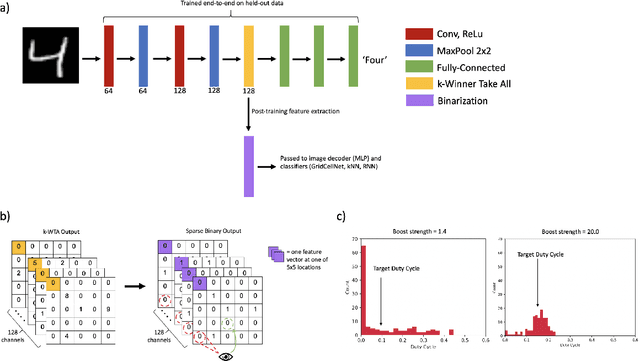
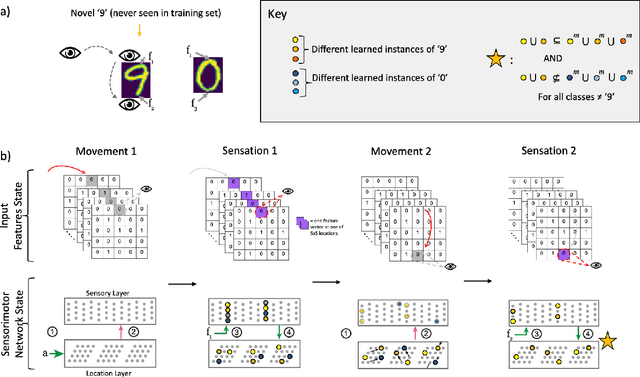
Grid cells enable the brain to model the physical space of the world and navigate effectively via path integration, updating self-position using information from self-movement. Recent proposals suggest that the brain might use similar mechanisms to understand the structure of objects in diverse sensory modalities, including vision. In machine vision, object recognition given a sequence of sensory samples of an image, such as saccades, is a challenging problem when the sequence does not follow a consistent, fixed pattern - yet this is something humans do naturally and effortlessly. We explore how grid cell-based path integration in a cortical network can support reliable recognition of objects given an arbitrary sequence of inputs. Our network (GridCellNet) uses grid cell computations to integrate visual information and make predictions based on movements. We use local Hebbian plasticity rules to learn rapidly from a handful of examples (few-shot learning), and consider the task of recognizing MNIST digits given only a sequence of image feature patches. We compare GridCellNet to k-Nearest Neighbour (k-NN) classifiers as well as recurrent neural networks (RNNs), both of which lack explicit mechanisms for handling arbitrary sequences of input samples. We show that GridCellNet can reliably perform classification, generalizing to both unseen examples and completely novel sequence trajectories. We further show that inference is often successful after sampling a fraction of the input space, enabling the predictive GridCellNet to reconstruct the rest of the image given just a few movements. We propose that dynamically moving agents with active sensors can use grid cell representations not only for navigation, but also for efficient recognition and feature prediction of seen objects.