 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Dynamical Prospection: Modeling Mental Simulation as Particle Filtering for Sensorimotor Control during Pathfinding
Mar 14, 2021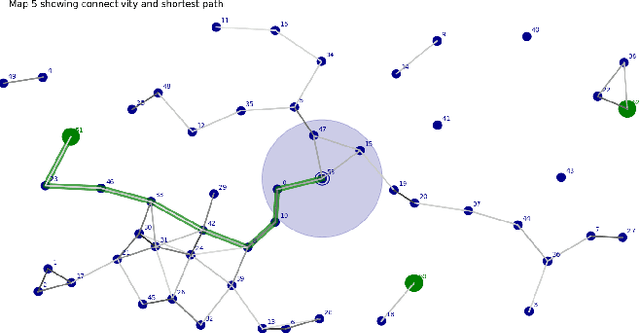


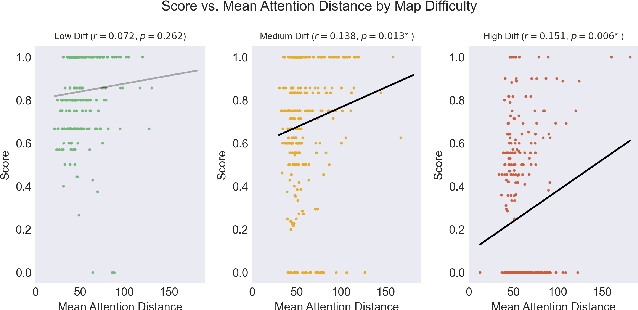
What do humans do when confronted with a common challenge: we know where we want to go but we are not yet sure the best way to get there, or even if we can. This is the problem posed to agents during spatial navigation and pathfinding, and its solution may give us clues about the more abstract domain of planning in general. In this work, we model pathfinding behavior in a continuous, explicitly exploratory paradigm. In our task, participants (and agents) must coordinate both visual exploration and navigation within a partially observable environment. Our contribution has three primary components: 1) an analysis of behavioral data from 81 human participants in a novel pathfinding paradigm conducted as an online experiment, 2) a proposal to model prospective mental simulation during navigation as particle filtering, and 3) an instantiation of this proposal in a computational agent. We show that our model, Active Dynamical Prospection, demonstrates similar patterns of map solution rate, path selection, and trial duration, as well as attentional behavior (at both aggregate and individual levels) when compared with data from human participants. We also find that both distal attention and delay prior to first move (both potential correlates of prospective simulation) are predictive of task performance.
Long Distance Relationships without Time Travel: Boosting the Performance of a Sparse Predictive Autoencoder in Sequence Modeling
Dec 02, 2019
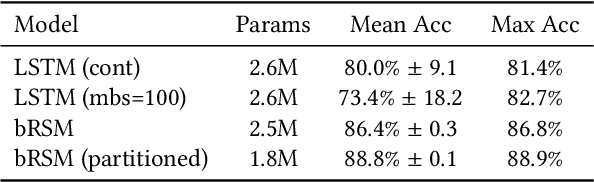

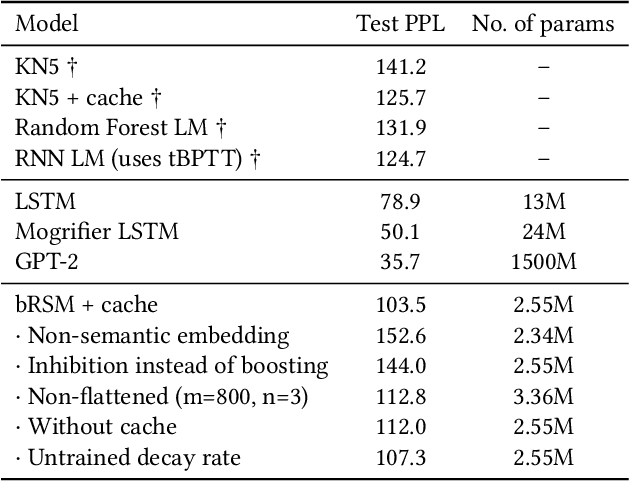
In sequence learning tasks such as language modelling, Recurrent Neural Networks must learn relationships between input features separated by time. State of the art models such as LSTM and Transformer are trained by backpropagation of losses into prior hidden states and inputs held in memory. This allows gradients to flow from present to past and effectively learn with perfect hindsight, but at a significant memory cost. In this paper we show that it is possible to train high performance recurrent networks using information that is local in time, and thereby achieve a significantly reduced memory footprint. We describe a predictive autoencoder called bRSM featuring recurrent connections, sparse activations, and a boosting rule for improved cell utilization. The architecture demonstrates near optimal performance on a non-deterministic (stochastic) partially-observable sequence learning task consisting of high-Markov-order sequences of MNIST digits. We find that this model learns these sequences faster and more completely than an LSTM, and offer several possible explanations why the LSTM architecture might struggle with the partially observable sequence structure in this task. We also apply our model to a next word prediction task on the Penn Treebank (PTB) dataset. We show that a 'flattened' RSM network, when paired with a modern semantic word embedding and the addition of boosting, achieves 103.5 PPL (a 20-point improvement over the best N-gram models), beating ordinary RNNs trained with BPTT and approaching the scores of early LSTM implementations. This work provides encouraging evidence that strong results on challenging tasks such as language modelling may be possible using less memory intensive, biologically-plausible training regimes.