 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Mixed Autonomy Traffic Flow With Decentralized Autonomous Vehicles and Multi-Agent RL
Oct 30, 2020
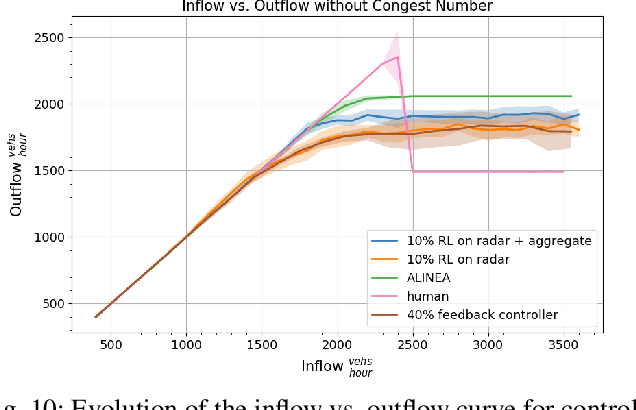
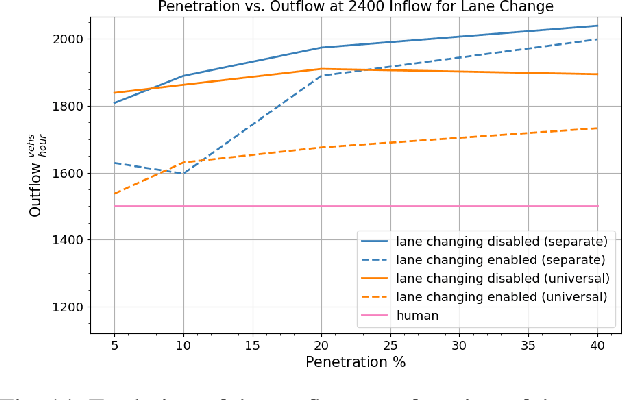
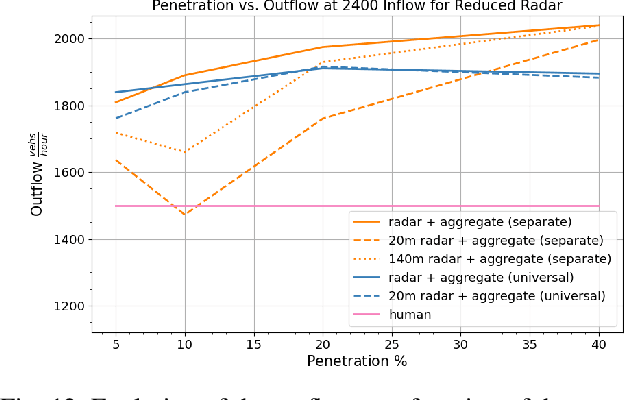
We study the ability of autonomous vehicles to improve the throughput of a bottleneck using a fully decentralized control scheme in a mixed autonomy setting. We consider the problem of improving the throughput of a scaled model of the San Francisco-Oakland Bay Bridge: a two-stage bottleneck where four lanes reduce to two and then reduce to one. Although there is extensive work examining variants of bottleneck control in a centralized setting, there is less study of the challenging multi-agent setting where the large number of interacting AVs leads to significant optimization difficulties for reinforcement learning methods. We apply multi-agent reinforcement algorithms to this problem and demonstrate that significant improvements in bottleneck throughput, from 20\% at a 5\% penetration rate to 33\% at a 40\% penetration rate, can be achieved. We compare our results to a hand-designed feedback controller and demonstrate that our results sharply outperform the feedback controller despite extensive tuning. Additionally, we demonstrate that the RL-based controllers adopt a robust strategy that works across penetration rates whereas the feedback controllers degrade immediately upon penetration rate variation. We investigate the feasibility of both action and observation decentralization and demonstrate that effective strategies are possible using purely local sensing. Finally, we open-source our code at https://github.com/eugenevinitsky/decentralized_bottlenecks.
Robust Reinforcement Learning using Adversarial Populations
Aug 04, 2020
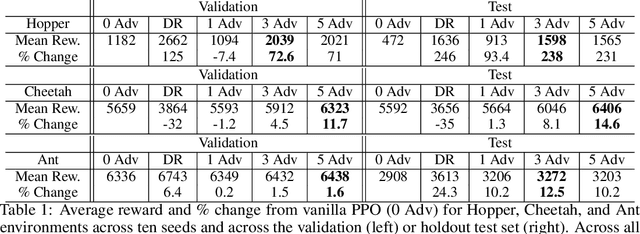
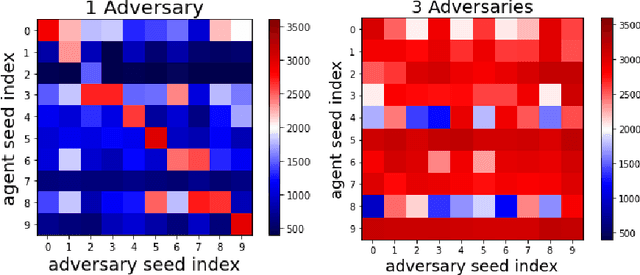
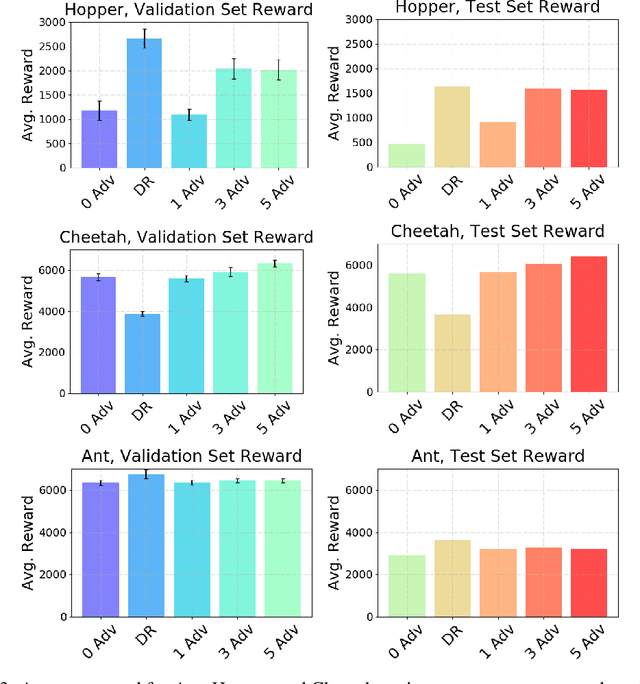
Reinforcement Learning (RL) is an effective tool for controller design but can struggle with issues of robustness, failing catastrophically when the underlying system dynamics are perturbed. The Robust RL formulation tackles this by adding worst-case adversarial noise to the dynamics and constructing the noise distribution as the solution to a zero-sum minimax game. However, existing work on learning solutions to the Robust RL formulation has primarily focused on training a single RL agent against a single adversary. In this work, we demonstrate that using a single adversary does not consistently yield robustness to dynamics variations under standard parametrizations of the adversary; the resulting policy is highly exploitable by new adversaries. We propose a population-based augmentation to the Robust RL formulation in which we randomly initialize a population of adversaries and sample from the population uniformly during training. We empirically validate across robotics benchmarks that the use of an adversarial population results in a more robust policy that also improves out-of-distribution generalization. Finally, we demonstrate that this approach provides comparable robustness and generalization as domain randomization on these benchmarks while avoiding a ubiquitous domain randomization failure mode.
Flow: Architecture and Benchmarking for Reinforcement Learning in Traffic Control
Oct 16, 2017
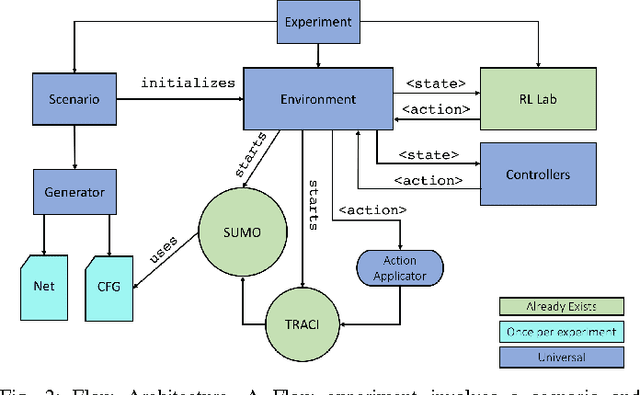

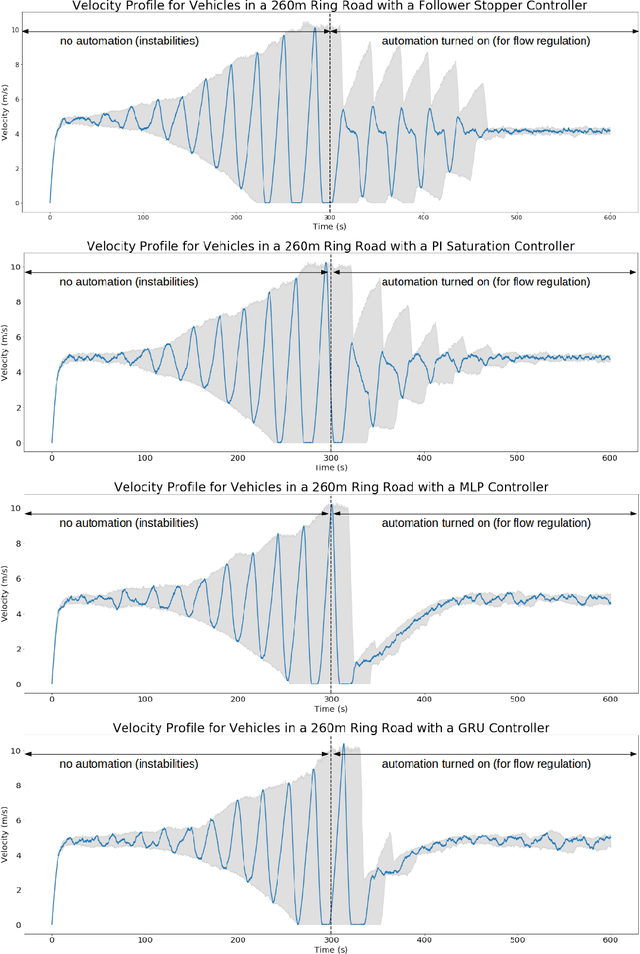
Flow is a new computational framework, built to support a key need triggered by the rapid growth of autonomy in ground traffic: controllers for autonomous vehicles in the presence of complex nonlinear dynamics in traffic. Leveraging recent advances in deep Reinforcement Learning (RL), Flow enables the use of RL methods such as policy gradient for traffic control and enables benchmarking the performance of classical (including hand-designed) controllers with learned policies (control laws). Flow integrates traffic microsimulator SUMO with deep reinforcement learning library rllab and enables the easy design of traffic tasks, including different networks configurations and vehicle dynamics. We use Flow to develop reliable controllers for complex problems, such as controlling mixed-autonomy traffic (involving both autonomous and human-driven vehicles) in a ring road. For this, we first show that state-of-the-art hand-designed controllers excel when in-distribution, but fail to generalize; then, we show that even simple neural network policies can solve the stabilization task across density settings and generalize to out-of-distribution settings.