 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Based Oscillation Dampening: Scaling up Single-Agent RL algorithms to a 100 AV highway field operational test
Feb 26, 2024In this article, we explore the technical details of the reinforcement learning (RL) algorithms that were deployed in the largest field test of automated vehicles designed to smooth traffic flow in history as of 2023, uncovering the challenges and breakthroughs that come with developing RL controllers for automated vehicles. We delve into the fundamental concepts behind RL algorithms and their application in the context of self-driving cars, discussing the developmental process from simulation to deployment in detail, from designing simulators to reward function shaping. We present the results in both simulation and deployment, discussing the flow-smoothing benefits of the RL controller. From understanding the basics of Markov decision processes to exploring advanced techniques such as deep RL, our article offers a comprehensive overview and deep dive of the theoretical foundations and practical implementations driving this rapidly evolving field. We also showcase real-world case studies and alternative research projects that highlight the impact of RL controllers in revolutionizing autonomous driving. From tackling complex urban environments to dealing with unpredictable traffic scenarios, these intelligent controllers are pushing the boundaries of what automated vehicles can achieve. Furthermore, we examine the safety considerations and hardware-focused technical details surrounding deployment of RL controllers into automated vehicles. As these algorithms learn and evolve through interactions with the environment, ensuring their behavior aligns with safety standards becomes crucial. We explore the methodologies and frameworks being developed to address these challenges, emphasizing the importance of building reliable control systems for automated vehicles.
Traffic Smoothing Controllers for Autonomous Vehicles Using Deep Reinforcement Learning and Real-World Trajectory Data
Jan 18, 2024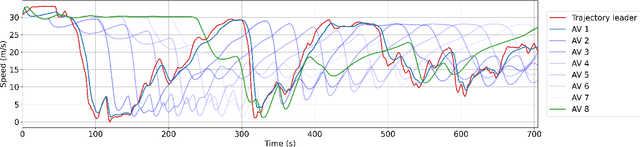
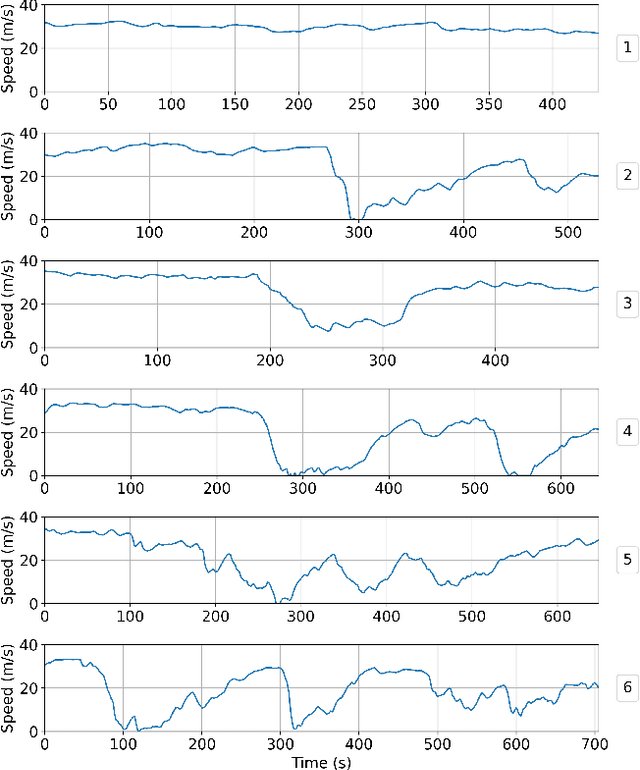
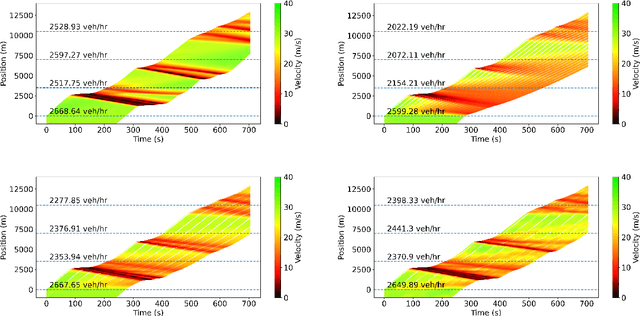
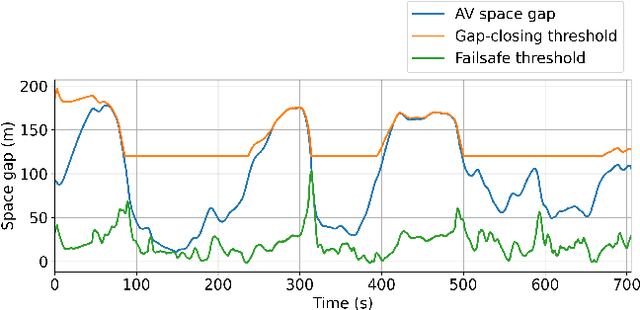
Designing traffic-smoothing cruise controllers that can be deployed onto autonomous vehicles is a key step towards improving traffic flow, reducing congestion, and enhancing fuel efficiency in mixed autonomy traffic. We bypass the common issue of having to carefully fine-tune a large traffic microsimulator by leveraging real-world trajectory data from the I-24 highway in Tennessee, replayed in a one-lane simulation. Using standard deep reinforcement learning methods, we train energy-reducing wave-smoothing policies. As an input to the agent, we observe the speed and distance of only the vehicle in front, which are local states readily available on most recent vehicles, as well as non-local observations about the downstream state of the traffic. We show that at a low 4% autonomous vehicle penetration rate, we achieve significant fuel savings of over 15% on trajectories exhibiting many stop-and-go waves. Finally, we analyze the smoothing effect of the controllers and demonstrate robustness to adding lane-changing into the simulation as well as the removal of downstream information.
Robust Reinforcement Learning using Adversarial Populations
Aug 04, 2020
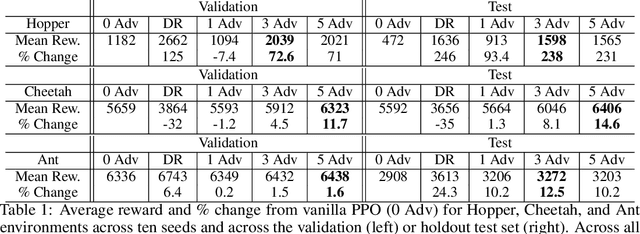
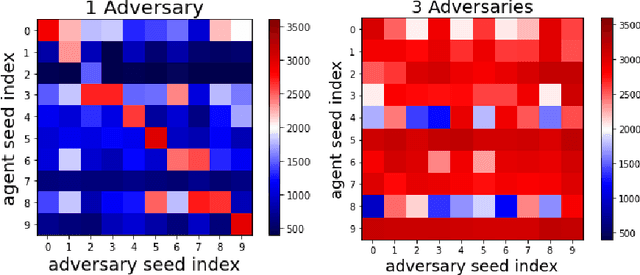
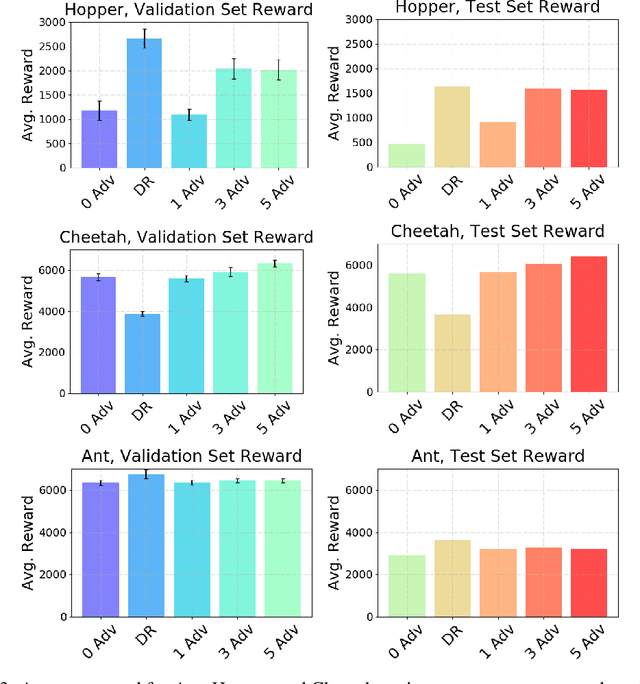
Reinforcement Learning (RL) is an effective tool for controller design but can struggle with issues of robustness, failing catastrophically when the underlying system dynamics are perturbed. The Robust RL formulation tackles this by adding worst-case adversarial noise to the dynamics and constructing the noise distribution as the solution to a zero-sum minimax game. However, existing work on learning solutions to the Robust RL formulation has primarily focused on training a single RL agent against a single adversary. In this work, we demonstrate that using a single adversary does not consistently yield robustness to dynamics variations under standard parametrizations of the adversary; the resulting policy is highly exploitable by new adversaries. We propose a population-based augmentation to the Robust RL formulation in which we randomly initialize a population of adversaries and sample from the population uniformly during training. We empirically validate across robotics benchmarks that the use of an adversarial population results in a more robust policy that also improves out-of-distribution generalization. Finally, we demonstrate that this approach provides comparable robustness and generalization as domain randomization on these benchmarks while avoiding a ubiquitous domain randomization failure mode.
Simulation to Scaled City: Zero-Shot Policy Transfer for Traffic Control via Autonomous Vehicles
Feb 22, 2019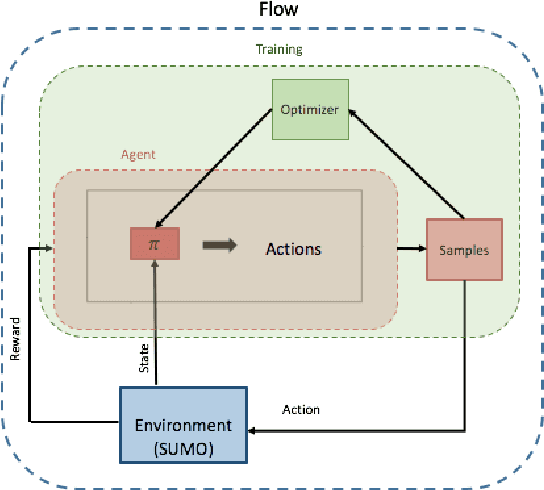
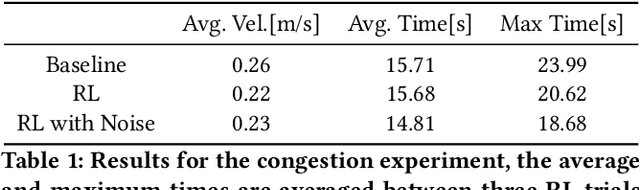

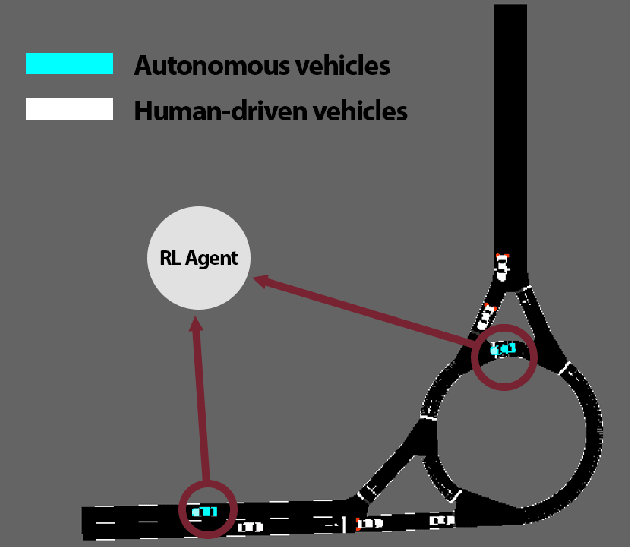
Using deep reinforcement learning, we train control policies for autonomous vehicles leading a platoon of vehicles onto a roundabout. Using Flow, a library for deep reinforcement learning in micro-simulators, we train two policies, one policy with noise injected into the state and action space and one without any injected noise. In simulation, the autonomous vehicle learns an emergent metering behavior for both policies in which it slows to allow for smoother merging. We then directly transfer this policy without any tuning to the University of Delaware Scaled Smart City (UDSSC), a 1:25 scale testbed for connected and automated vehicles. We characterize the performance of both policies on the scaled city. We show that the noise-free policy winds up crashing and only occasionally metering. However, the noise-injected policy consistently performs the metering behavior and remains collision-free, suggesting that the noise helps with the zero-shot policy transfer. Additionally, the transferred, noise-injected policy leads to a 5% reduction of average travel time and a reduction of 22% in maximum travel time in the UDSSC. Videos of the controllers can be found at https://sites.google.com/view/iccps-policy-transfer.