 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation to Scaled City: Zero-Shot Policy Transfer for Traffic Control via Autonomous Vehicles
Paper and Code
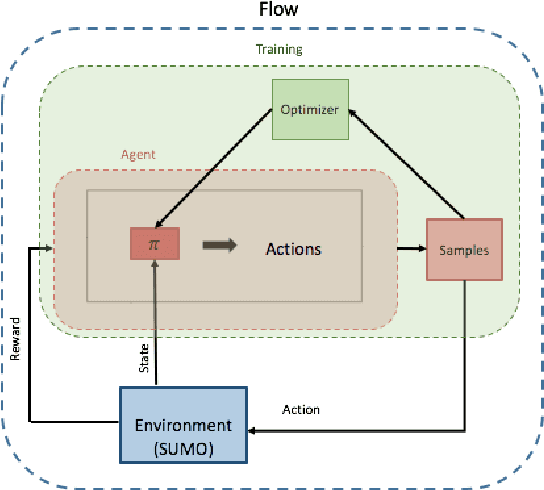
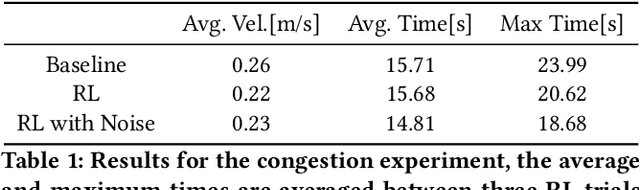

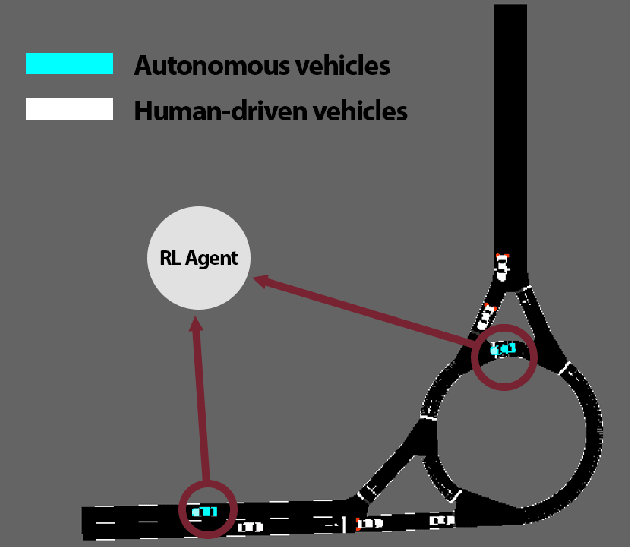
Using deep reinforcement learning, we train control policies for autonomous vehicles leading a platoon of vehicles onto a roundabout. Using Flow, a library for deep reinforcement learning in micro-simulators, we train two policies, one policy with noise injected into the state and action space and one without any injected noise. In simulation, the autonomous vehicle learns an emergent metering behavior for both policies in which it slows to allow for smoother merging. We then directly transfer this policy without any tuning to the University of Delaware Scaled Smart City (UDSSC), a 1:25 scale testbed for connected and automated vehicles. We characterize the performance of both policies on the scaled city. We show that the noise-free policy winds up crashing and only occasionally metering. However, the noise-injected policy consistently performs the metering behavior and remains collision-free, suggesting that the noise helps with the zero-shot policy transfer. Additionally, the transferred, noise-injected policy leads to a 5% reduction of average travel time and a reduction of 22% in maximum travel time in the UDSSC. Videos of the controllers can be found at https://sites.google.com/view/iccps-policy-transfer.