 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of SAM: Segment Anything Under Corruptions and Beyond
Jun 13, 2023



Segment anything model (SAM), as the name suggests, is claimed to be capable of cutting out any object. SAM is a vision foundation model which demonstrates impressive zero-shot transfer performance with the guidance of a prompt. However, there is currently a lack of comprehensive evaluation of its robustness performance under various types of corruptions. Prior works show that SAM is biased towards texture (style) rather than shape, motivated by which we start by investigating SAM's robustness against style transfer, which is synthetic corruption. With the effect of corruptions interpreted as a style change, we further evaluate its robustness on 15 common corruptions with 5 severity levels for each real-world corruption. Beyond the corruptions, we further evaluate the SAM robustness on local occlusion and adversarial perturbations. Overall, this work provides a comprehensive empirical study on the robustness of the SAM under corruptions and beyond.
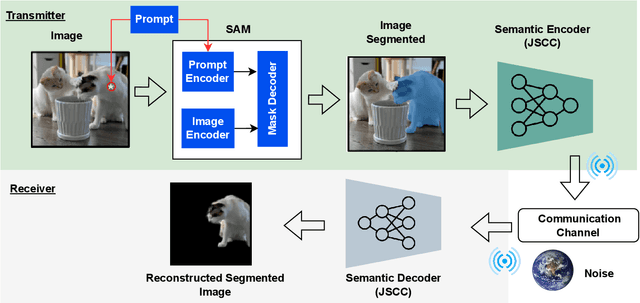
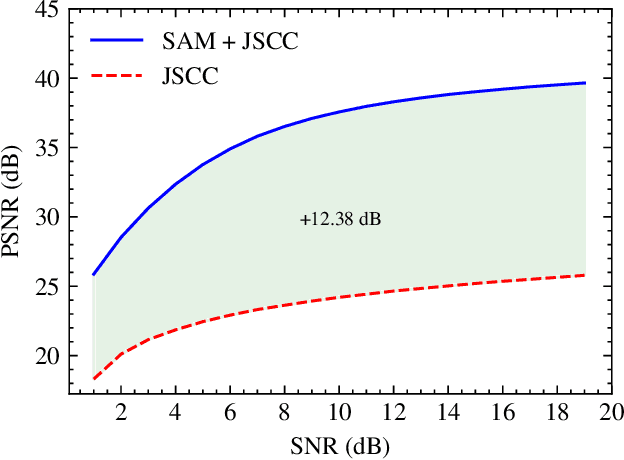
Segment Anything Meets Semantic Communication
Jun 03, 2023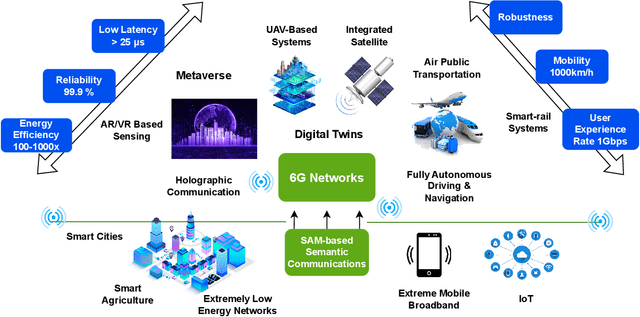

In light of the diminishing returns of traditional methods for enhancing transmission rates, the domain of semantic communication presents promising new frontiers. Focusing on image transmission, this paper explores the application of foundation models, particularly the Segment Anything Model (SAM) developed by Meta AI Research, to improve semantic communication. SAM is a promptable image segmentation model that has gained attention for its ability to perform zero-shot segmentation tasks without explicit training or domain-specific knowledge. By employing SAM's segmentation capability and lightweight neural network architecture for semantic coding, we propose a practical approach to semantic communication. We demonstrate that this approach retains critical semantic features, achieving higher image reconstruction quality and reducing communication overhead. This practical solution eliminates the resource-intensive stage of training a segmentation model and can be applied to any semantic coding architecture, paving the way for real-world applications.