 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration of ordinal regression networks
Oct 21, 2024Recent studies have shown that deep neural networks are not well-calibrated and produce over-confident predictions. The miscalibration issue primarily stems from the minimization of cross-entropy, which aims to align predicted softmax probabilities with one-hot labels. In ordinal regression tasks, this problem is compounded by an additional challenge: the expectation that softmax probabilities should exhibit unimodal distribution is not met with cross-entropy. Rather, the ordinal regression literature has focused on unimodality and overlooked calibration. To address these issues, we propose a novel loss function that introduces order-aware calibration, ensuring that prediction confidence adheres to ordinal relationships between classes. It incorporates soft ordinal encoding and label-smoothing-based regularization to enforce both calibration and unimodality. Extensive experiments across three popular ordinal regression benchmarks demonstrate that our approach achieves state-of-the-art calibration without compromising accuracy.
Proxy Anchor-based Unsupervised Learning for Continuous Generalized Category Discovery
Jul 20, 2023
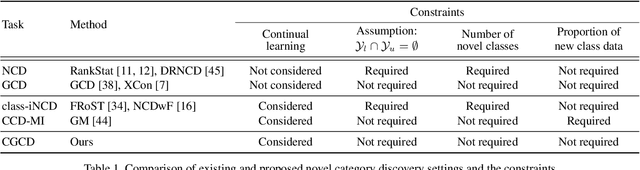
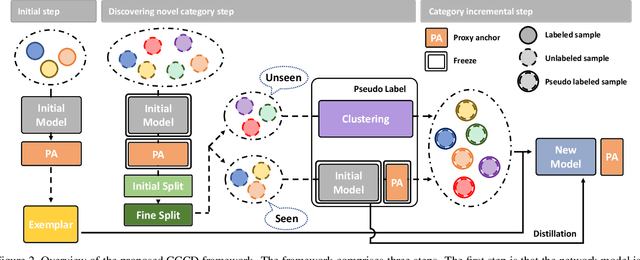
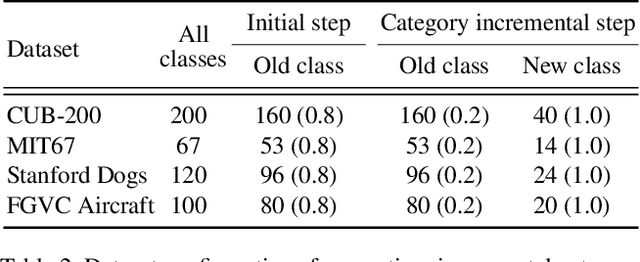
Recent advances in deep learning have significantly improved the performance of various computer vision applications. However, discovering novel categories in an incremental learning scenario remains a challenging problem due to the lack of prior knowledge about the number and nature of new categories. Existing methods for novel category discovery are limited by their reliance on labeled datasets and prior knowledge about the number of novel categories and the proportion of novel samples in the batch. To address the limitations and more accurately reflect real-world scenarios, in this paper, we propose a novel unsupervised class incremental learning approach for discovering novel categories on unlabeled sets without prior knowledge. The proposed method fine-tunes the feature extractor and proxy anchors on labeled sets, then splits samples into old and novel categories and clusters on the unlabeled dataset. Furthermore, the proxy anchors-based exemplar generates representative category vectors to mitigate catastrophic forgetting. Experimental results demonstrate that our proposed approach outperforms the state-of-the-art methods on fine-grained datasets under real-world scenarios.
AI-KD: Adversarial learning and Implicit regularization for self-Knowledge Distillation
Nov 20, 2022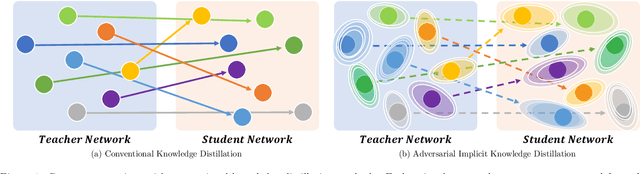
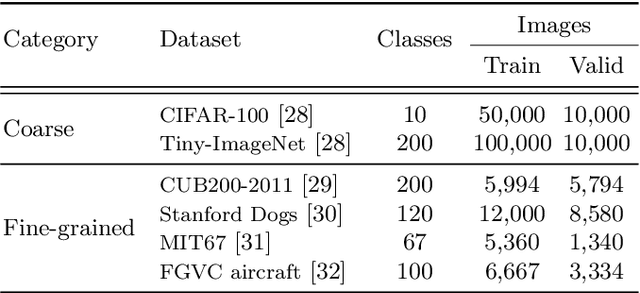
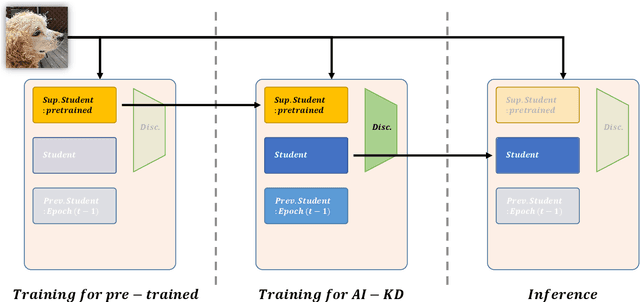
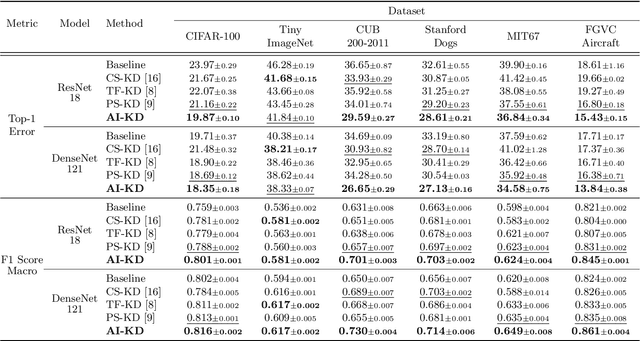
We present a novel adversarial penalized self-knowledge distillation method, named adversarial learning and implicit regularization for self-knowledge distillation (AI-KD), which regularizes the training procedure by adversarial learning and implicit distillations. Our model not only distills the deterministic and progressive knowledge which are from the pre-trained and previous epoch predictive probabilities but also transfers the knowledge of the deterministic predictive distributions using adversarial learning. The motivation is that the self-knowledge distillation methods regularize the predictive probabilities with soft targets, but the exact distributions may be hard to predict. Our method deploys a discriminator to distinguish the distributions between the pre-trained and student models while the student model is trained to fool the discriminator in the trained procedure. Thus, the student model not only can learn the pre-trained model's predictive probabilities but also align the distributions between the pre-trained and student models. We demonstrate the effectiveness of the proposed method with network architectures on multiple datasets and show the proposed method achieves better performance than state-of-the-art methods.
SplitNet: Learnable Clean-Noisy Label Splitting for Learning with Noisy Labels
Nov 20, 2022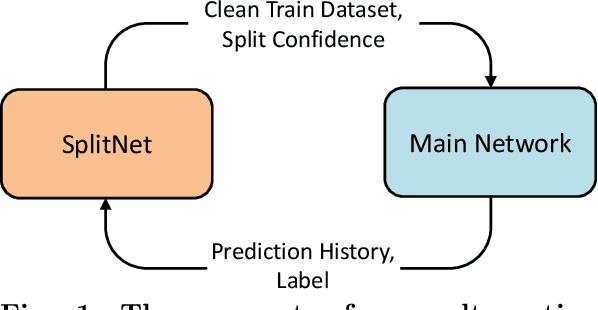
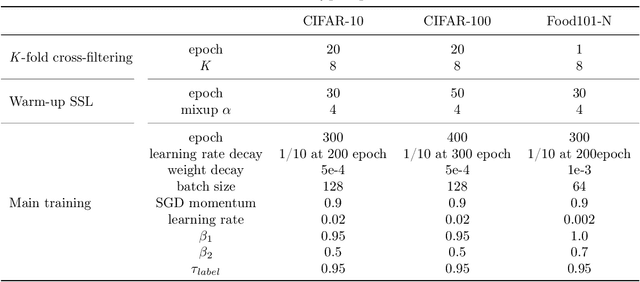
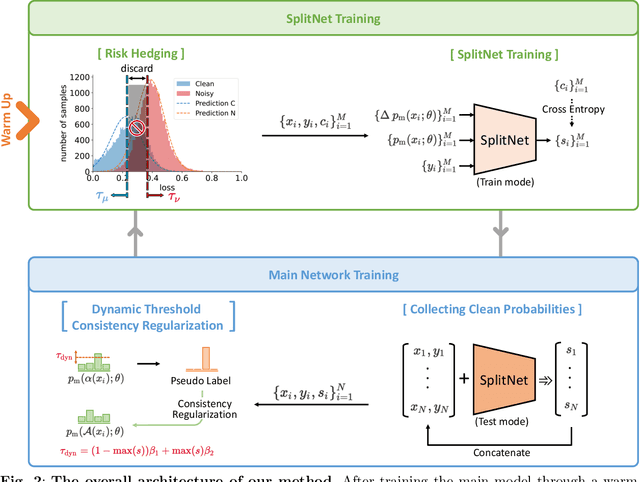
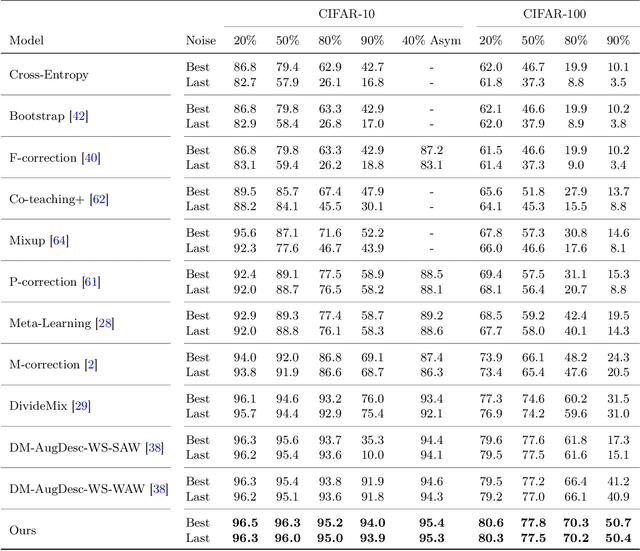
Annotating the dataset with high-quality labels is crucial for performance of deep network, but in real world scenarios, the labels are often contaminated by noise. To address this, some methods were proposed to automatically split clean and noisy labels, and learn a semi-supervised learner in a Learning with Noisy Labels (LNL) framework. However, they leverage a handcrafted module for clean-noisy label splitting, which induces a confirmation bias in the semi-supervised learning phase and limits the performance. In this paper, we for the first time present a learnable module for clean-noisy label splitting, dubbed SplitNet, and a novel LNL framework which complementarily trains the SplitNet and main network for the LNL task. We propose to use a dynamic threshold based on a split confidence by SplitNet to better optimize semi-supervised learner. To enhance SplitNet training, we also present a risk hedging method. Our proposed method performs at a state-of-the-art level especially in high noise ratio settings on various LNL benchmarks.
ConMatch: Semi-Supervised Learning with Confidence-Guided Consistency Regularization
Aug 18, 2022
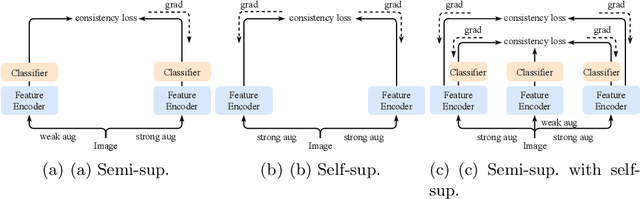
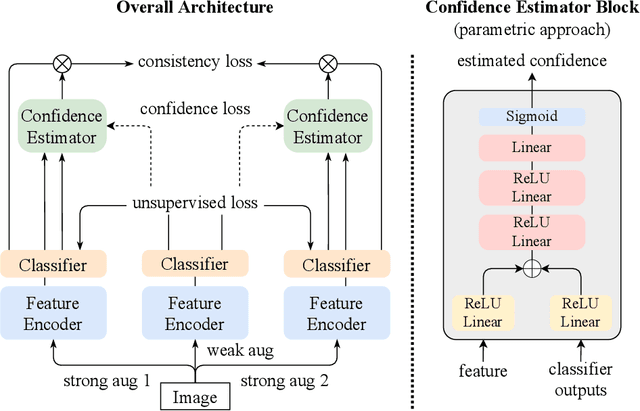
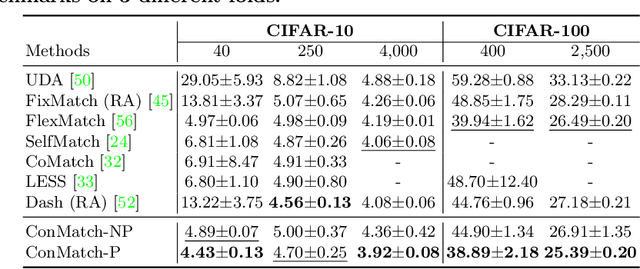
We present a novel semi-supervised learning framework that intelligently leverages the consistency regularization between the model's predictions from two strongly-augmented views of an image, weighted by a confidence of pseudo-label, dubbed ConMatch. While the latest semi-supervised learning methods use weakly- and strongly-augmented views of an image to define a directional consistency loss, how to define such direction for the consistency regularization between two strongly-augmented views remains unexplored. To account for this, we present novel confidence measures for pseudo-labels from strongly-augmented views by means of weakly-augmented view as an anchor in non-parametric and parametric approaches. Especially, in parametric approach, we present, for the first time, to learn the confidence of pseudo-label within the networks, which is learned with backbone model in an end-to-end manner. In addition, we also present a stage-wise training to boost the convergence of training. When incorporated in existing semi-supervised learners, ConMatch consistently boosts the performance. We conduct experiments to demonstrate the effectiveness of our ConMatch over the latest methods and provide extensive ablation studies. Code has been made publicly available at https://github.com/JiwonCocoder/ConMatch.
Semi-Supervised Learning of Semantic Correspondence with Pseudo-Labels
Apr 05, 2022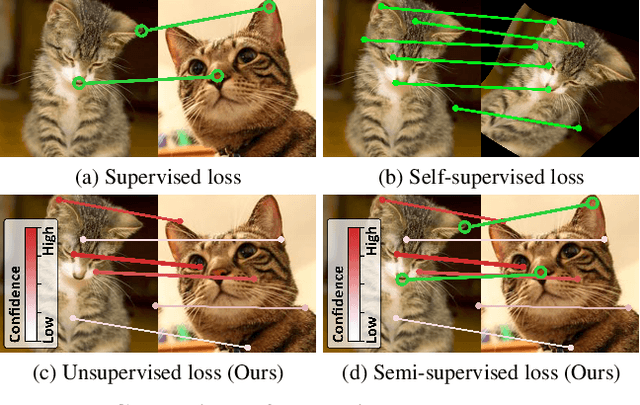
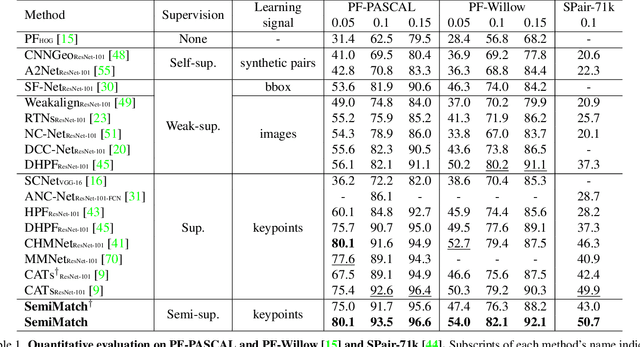
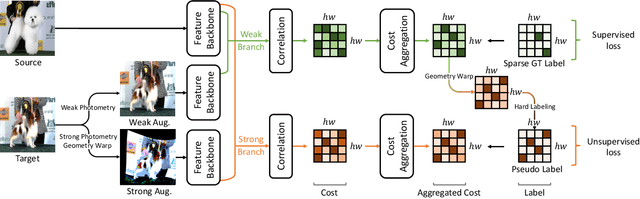
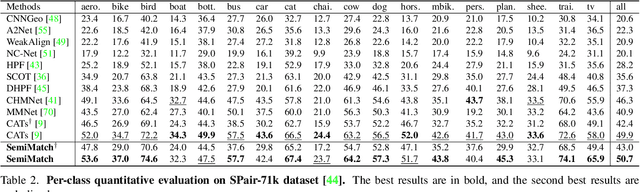
Establishing dense correspondences across semantically similar images remains a challenging task due to the significant intra-class variations and background clutters. Traditionally, a supervised learning was used for training the models, which required tremendous manually-labeled data, while some methods suggested a self-supervised or weakly-supervised learning to mitigate the reliance on the labeled data, but with limited performance. In this paper, we present a simple, but effective solution for semantic correspondence that learns the networks in a semi-supervised manner by supplementing few ground-truth correspondences via utilization of a large amount of confident correspondences as pseudo-labels, called SemiMatch. Specifically, our framework generates the pseudo-labels using the model's prediction itself between source and weakly-augmented target, and uses pseudo-labels to learn the model again between source and strongly-augmented target, which improves the robustness of the model. We also present a novel confidence measure for pseudo-labels and data augmentation tailored for semantic correspondence. In experiments, SemiMatch achieves state-of-the-art performance on various benchmarks, especially on PF-Willow by a large margin.
AggMatch: Aggregating Pseudo Labels for Semi-Supervised Learning
Jan 25, 2022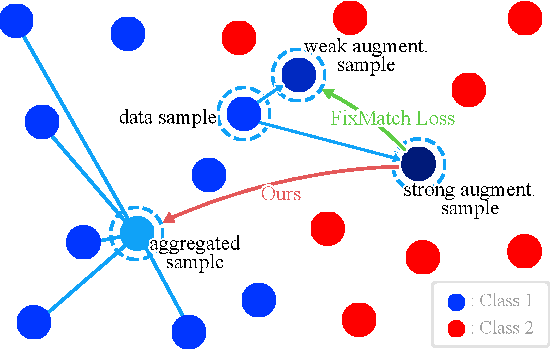
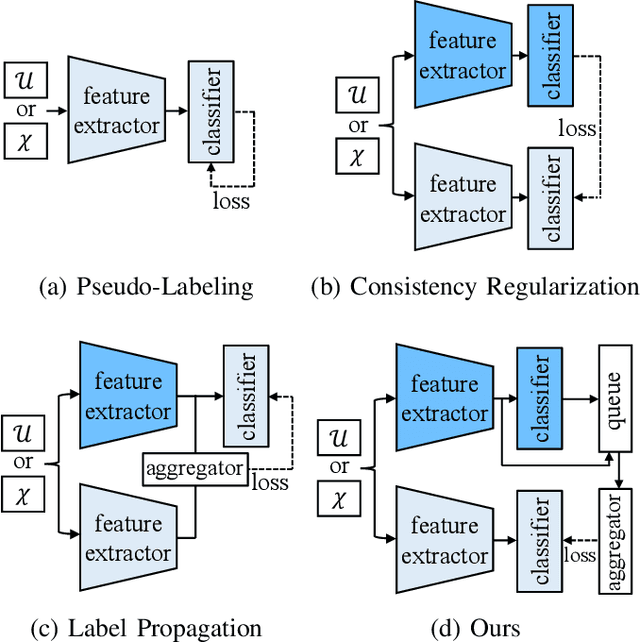
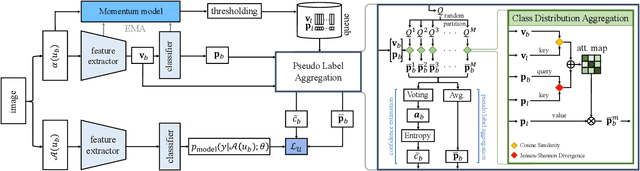
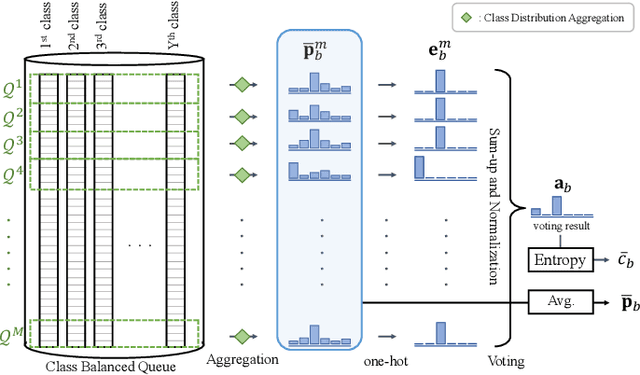
Semi-supervised learning (SSL) has recently proven to be an effective paradigm for leveraging a huge amount of unlabeled data while mitigating the reliance on large labeled data. Conventional methods focused on extracting a pseudo label from individual unlabeled data sample and thus they mostly struggled to handle inaccurate or noisy pseudo labels, which degenerate performance. In this paper, we address this limitation with a novel SSL framework for aggregating pseudo labels, called AggMatch, which refines initial pseudo labels by using different confident instances. Specifically, we introduce an aggregation module for consistency regularization framework that aggregates the initial pseudo labels based on the similarity between the instances. To enlarge the aggregation candidates beyond the mini-batch, we present a class-balanced confidence-aware queue built with the momentum model, encouraging to provide more stable and consistent aggregation. We also propose a novel uncertainty-based confidence measure for the pseudo label by considering the consensus among multiple hypotheses with different subsets of the queue. We conduct experiments to demonstrate the effectiveness of AggMatch over the latest methods on standard benchmarks and provide extensive analyses.