 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEZ-Sort: Efficient Pairwise Comparison via Zero-Shot CLIP-Based Pre-Ordering and Human-in-the-Loop Sorting
Aug 29, 2025



Pairwise comparison is often favored over absolute rating or ordinal classification in subjective or difficult annotation tasks due to its improved reliability. However, exhaustive comparisons require a massive number of annotations (O(n^2)). Recent work has greatly reduced the annotation burden (O(n log n)) by actively sampling pairwise comparisons using a sorting algorithm. We further improve annotation efficiency by (1) roughly pre-ordering items using the Contrastive Language-Image Pre-training (CLIP) model hierarchically without training, and (2) replacing easy, obvious human comparisons with automated comparisons. The proposed EZ-Sort first produces a CLIP-based zero-shot pre-ordering, then initializes bucket-aware Elo scores, and finally runs an uncertainty-guided human-in-the-loop MergeSort. Validation was conducted using various datasets: face-age estimation (FGNET), historical image chronology (DHCI), and retinal image quality assessment (EyePACS). It showed that EZ-Sort reduced human annotation cost by 90.5% compared to exhaustive pairwise comparisons and by 19.8% compared to prior work (when n = 100), while improving or maintaining inter-rater reliability. These results demonstrate that combining CLIP-based priors with uncertainty-aware sampling yields an efficient and scalable solution for pairwise ranking.
BOLDSimNet: Examining Brain Network Similarity between Task and Resting-State fMRI
Apr 02, 2025Traditional causal connectivity methods in task-based and resting-state functional magnetic resonance imaging (fMRI) face challenges in accurately capturing directed information flow due to their sensitivity to noise and inability to model multivariate dependencies. These limitations hinder the effective comparison of brain networks between cognitive states, making it difficult to analyze network reconfiguration during task and resting states. To address these issues, we propose BOLDSimNet, a novel framework utilizing Multivariate Transfer Entropy (MTE) to measure causal connectivity and network similarity across different cognitive states. Our method groups functionally similar regions of interest (ROIs) rather than spatially adjacent nodes, improving accuracy in network alignment. We applied BOLDSimNet to fMRI data from 40 healthy controls and found that children exhibited higher similarity scores between task and resting states compared to adolescents, indicating reduced variability in attention shifts. In contrast, adolescents showed more differences between task and resting states in the Dorsal Attention Network (DAN) and the Default Mode Network (DMN), reflecting enhanced network adaptability. These findings emphasize developmental variations in the reconfiguration of the causal brain network, showcasing BOLDSimNet's ability to quantify network similarity and identify attentional fluctuations between different cognitive states.
Uncertainty-Weighted Mutual Distillation for Multi-View Fusion
Nov 15, 2024Multi-view learning often faces challenges in effectively leveraging images captured from different angles and locations. This challenge is particularly pronounced when addressing inconsistencies and uncertainties between views. In this paper, we propose a novel Multi-View Uncertainty-Weighted Mutual Distillation (MV-UWMD) method. Our method enhances prediction consistency by performing hierarchical mutual distillation across all possible view combinations, including single-view, partial multi-view, and full multi-view predictions. This introduces an uncertainty-based weighting mechanism through mutual distillation, allowing effective exploitation of unique information from each view while mitigating the impact of uncertain predictions. We extend a CNN-Transformer hybrid architecture to facilitate robust feature learning and integration across multiple view combinations. We conducted extensive experiments using a large, unstructured dataset captured from diverse, non-fixed viewpoints. The results demonstrate that MV-UWMD improves prediction accuracy and consistency compared to existing multi-view learning approaches.
Calibration of ordinal regression networks
Oct 21, 2024Recent studies have shown that deep neural networks are not well-calibrated and produce over-confident predictions. The miscalibration issue primarily stems from the minimization of cross-entropy, which aims to align predicted softmax probabilities with one-hot labels. In ordinal regression tasks, this problem is compounded by an additional challenge: the expectation that softmax probabilities should exhibit unimodal distribution is not met with cross-entropy. Rather, the ordinal regression literature has focused on unimodality and overlooked calibration. To address these issues, we propose a novel loss function that introduces order-aware calibration, ensuring that prediction confidence adheres to ordinal relationships between classes. It incorporates soft ordinal encoding and label-smoothing-based regularization to enforce both calibration and unimodality. Extensive experiments across three popular ordinal regression benchmarks demonstrate that our approach achieves state-of-the-art calibration without compromising accuracy.
Facial Wrinkle Segmentation for Cosmetic Dermatology: Pretraining with Texture Map-Based Weak Supervision
Aug 19, 2024



Facial wrinkle detection plays a crucial role in cosmetic dermatology. Precise manual segmentation of facial wrinkles is challenging and time-consuming, with inherent subjectivity leading to inconsistent results among graders. To address this issue, we propose two solutions. First, we build and release the first public facial wrinkle dataset, `FFHQ-Wrinkle', an extension of the NVIDIA FFHQ dataset. This dataset includes 1,000 images with human labels and 50,000 images with automatically generated weak labels. This dataset can foster the research community to develop advanced wrinkle detection algorithms. Second, we introduce a training strategy for U-Net-like encoder-decoder models to detect wrinkles across the face automatically. Our method employs a two-stage training strategy: texture map pretraining and finetuning on human-labeled data. Initially, we pretrain models on a large dataset with weak labels (N=50k) or masked texture maps generated through computer vision techniques, without human intervention. Subsequently, we finetune the models using human-labeled data (N=1k), which consists of manually labeled wrinkle masks. During finetuning, the network inputs a combination of RGB and masked texture maps, comprising four channels. We effectively combine labels from multiple annotators to minimize subjectivity in manual labeling. Our strategies demonstrate improved segmentation performance in facial wrinkle segmentation both quantitatively and visually compared to existing pretraining methods.
Weakly Supervised Pretraining and Multi-Annotator Supervised Finetuning for Facial Wrinkle Detection
Aug 19, 2024


1. Research question: With the growing interest in skin diseases and skin aesthetics, the ability to predict facial wrinkles is becoming increasingly important. This study aims to evaluate whether a computational model, convolutional neural networks (CNN), can be trained for automated facial wrinkle segmentation. 2. Findings: Our study presents an effective technique for integrating data from multiple annotators and illustrates that transfer learning can enhance performance, resulting in dependable segmentation of facial wrinkles. 3. Meaning: This approach automates intricate and time-consuming tasks of wrinkle analysis with a deep learning framework. It could be used to facilitate skin treatments and diagnostics.
Preoperative Rotator Cuff Tear Prediction from Shoulder Radiographs using a Convolutional Block Attention Module-Integrated Neural Network
Aug 19, 2024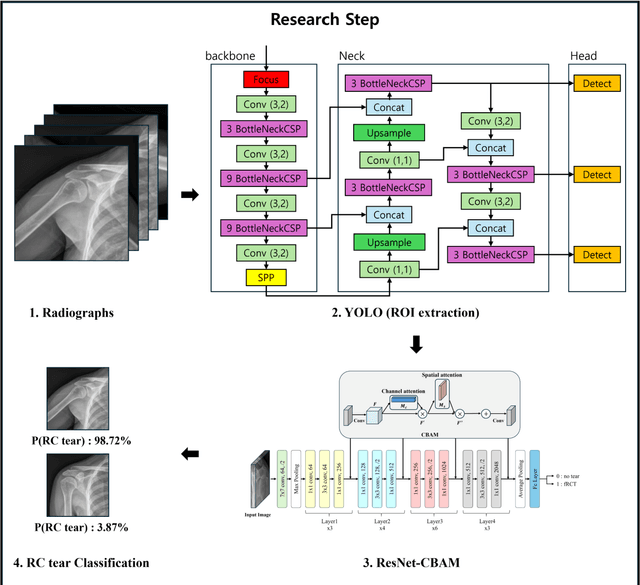



Research question: We test whether a plane shoulder radiograph can be used together with deep learning methods to identify patients with rotator cuff tears as opposed to using an MRI in standard of care. Findings: By integrating convolutional block attention modules into a deep neural network, our model demonstrates high accuracy in detecting patients with rotator cuff tears, achieving an average AUC of 0.889 and an accuracy of 0.831. Meaning: This study validates the efficacy of our deep learning model to accurately detect rotation cuff tears from radiographs, offering a viable pre-assessment or alternative to more expensive imaging techniques such as MRI.
Cyclic 2.5D Perceptual Loss for Cross-Modal 3D Image Synthesis: T1 MRI to Tau-PET
Jun 18, 2024Alzheimer's Disease (AD) is the most common form of dementia, characterised by cognitive decline and biomarkers such as tau-proteins. Tau-positron emission tomography (tau-PET), which employs a radiotracer to selectively bind, detect, and visualise tau protein aggregates within the brain, is valuable for early AD diagnosis but is less accessible due to high costs, limited availability, and its invasive nature. Image synthesis with neural networks enables the generation of tau-PET images from more accessible T1-weighted magnetic resonance imaging (MRI) images. To ensure high-quality image synthesis, we propose a cyclic 2.5D perceptual loss combined with mean squared error and structural similarity index measure (SSIM) losses. The cyclic 2.5D perceptual loss sequentially calculates the axial 2D average perceptual loss for a specified number of epochs, followed by the coronal and sagittal planes for the same number of epochs. This sequence is cyclically performed, with intervals reducing as the cycles repeat. We conduct supervised synthesis of tau-PET images from T1w MRI images using 516 paired T1w MRI and tau-PET 3D images from the ADNI database. For the collected data, we perform preprocessing, including intensity standardisation for tau-PET images from each manufacturer. The proposed loss, applied to generative 3D U-Net and its variants, outperformed those with 2.5D and 3D perceptual losses in SSIM and peak signal-to-noise ratio (PSNR). In addition, including the cyclic 2.5D perceptual loss to the original losses of GAN-based image synthesis models such as CycleGAN and Pix2Pix improves SSIM and PSNR by at least 2% and 3%. Furthermore, by-manufacturer PET standardisation helps the models in synthesising high-quality images than min-max PET normalisation.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.