 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLighthouseGS: Indoor Structure-aware 3D Gaussian Splatting for Panorama-Style Mobile Captures
Jul 08, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled real-time novel view synthesis (NVS) with impressive quality in indoor scenes. However, achieving high-fidelity rendering requires meticulously captured images covering the entire scene, limiting accessibility for general users. We aim to develop a practical 3DGS-based NVS framework using simple panorama-style motion with a handheld camera (e.g., mobile device). While convenient, this rotation-dominant motion and narrow baseline make accurate camera pose and 3D point estimation challenging, especially in textureless indoor scenes. To address these challenges, we propose LighthouseGS, a novel framework inspired by the lighthouse-like sweeping motion of panoramic views. LighthouseGS leverages rough geometric priors, such as mobile device camera poses and monocular depth estimation, and utilizes the planar structures often found in indoor environments. We present a new initialization method called plane scaffold assembly to generate consistent 3D points on these structures, followed by a stable pruning strategy to enhance geometry and optimization stability. Additionally, we introduce geometric and photometric corrections to resolve inconsistencies from motion drift and auto-exposure in mobile devices. Tested on collected real and synthetic indoor scenes, LighthouseGS delivers photorealistic rendering, surpassing state-of-the-art methods and demonstrating the potential for panoramic view synthesis and object placement.
MeTTA: Single-View to 3D Textured Mesh Reconstruction with Test-Time Adaptation
Aug 21, 2024
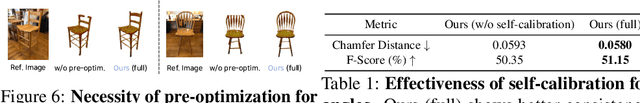

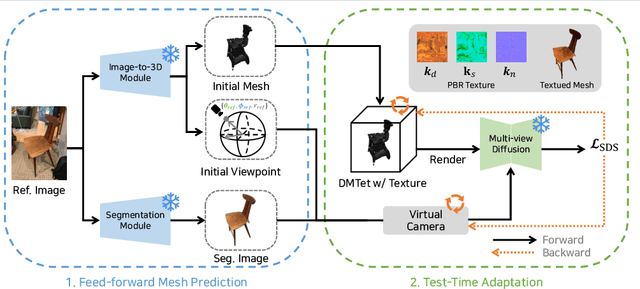
Reconstructing 3D from a single view image is a long-standing challenge. One of the popular approaches to tackle this problem is learning-based methods, but dealing with the test cases unfamiliar with training data (Out-of-distribution; OoD) introduces an additional challenge. To adapt for unseen samples in test time, we propose MeTTA, a test-time adaptation (TTA) exploiting generative prior. We design joint optimization of 3D geometry, appearance, and pose to handle OoD cases with only a single view image. However, the alignment between the reference image and the 3D shape via the estimated viewpoint could be erroneous, which leads to ambiguity. To address this ambiguity, we carefully design learnable virtual cameras and their self-calibration. In our experiments, we demonstrate that MeTTA effectively deals with OoD scenarios at failure cases of existing learning-based 3D reconstruction models and enables obtaining a realistic appearance with physically based rendering (PBR) textures.
TRACE: Table Reconstruction Aligned to Corner and Edges
May 01, 2023



A table is an object that captures structured and informative content within a document, and recognizing a table in an image is challenging due to the complexity and variety of table layouts. Many previous works typically adopt a two-stage approach; (1) Table detection(TD) localizes the table region in an image and (2) Table Structure Recognition(TSR) identifies row- and column-wise adjacency relations between the cells. The use of a two-stage approach often entails the consequences of error propagation between the modules and raises training and inference inefficiency. In this work, we analyze the natural characteristics of a table, where a table is composed of cells and each cell is made up of borders consisting of edges. We propose a novel method to reconstruct the table in a bottom-up manner. Through a simple process, the proposed method separates cell boundaries from low-level features, such as corners and edges, and localizes table positions by combining the cells. A simple design makes the model easier to train and requires less computation than previous two-stage methods. We achieve state-of-the-art performance on the ICDAR2013 table competition benchmark and Wired Table in the Wild(WTW) dataset.
DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting
Mar 10, 2022
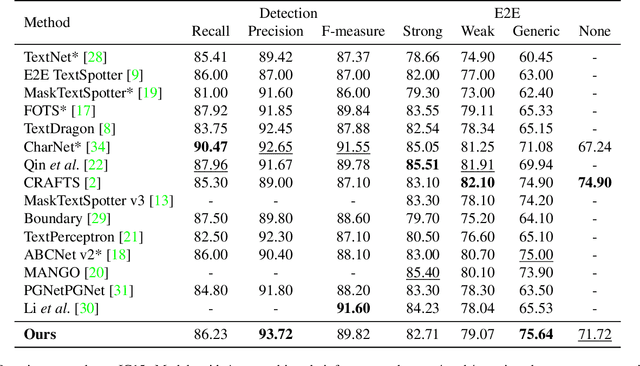
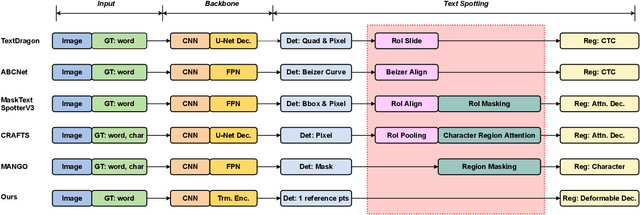
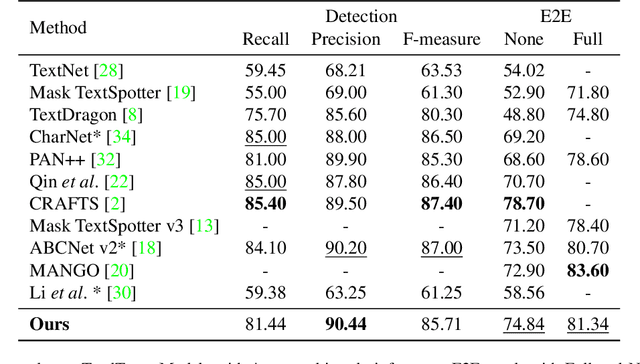
Recent end-to-end scene text spotters have achieved great improvement in recognizing arbitrary-shaped text instances. Common approaches for text spotting use region of interest pooling or segmentation masks to restrict features to single text instances. However, this makes it hard for the recognizer to decode correct sequences when the detection is not accurate i.e. one or more characters are cropped out. Considering that it is hard to accurately decide word boundaries with only the detector, we propose a novel Detection-agnostic End-to-End Recognizer, DEER, framework. The proposed method reduces the tight dependency between detection and recognition modules by bridging them with a single reference point for each text instance, instead of using detected regions. The proposed method allows the decoder to recognize the texts that are indicated by the reference point, with features from the whole image. Since only a single point is required to recognize the text, the proposed method enables text spotting without an arbitrarily-shaped detector or bounding polygon annotations. Experimental results present that the proposed method achieves competitive results on regular and arbitrarily-shaped text spotting benchmarks. Further analysis shows that DEER is robust to the detection errors. The code and dataset will be publicly available.