 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
Apr 30, 2024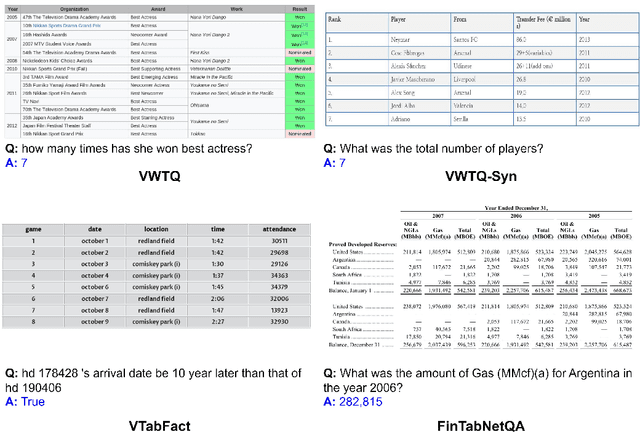
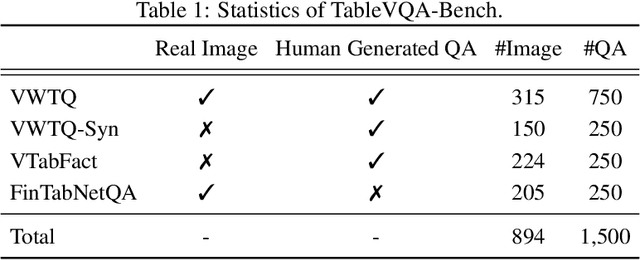
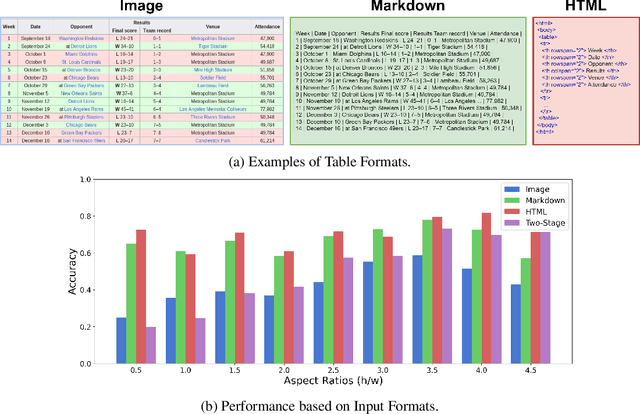
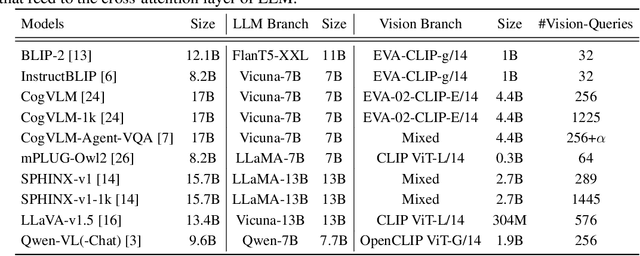
In this paper, we establish a benchmark for table visual question answering, referred to as the TableVQA-Bench, derived from pre-existing table question-answering (QA) and table structure recognition datasets. It is important to note that existing datasets have not incorporated images or QA pairs, which are two crucial components of TableVQA. As such, the primary objective of this paper is to obtain these necessary components. Specifically, images are sourced either through the application of a \textit{stylesheet} or by employing the proposed table rendering system. QA pairs are generated by exploiting the large language model (LLM) where the input is a text-formatted table. Ultimately, the completed TableVQA-Bench comprises 1,500 QA pairs. We comprehensively compare the performance of various multi-modal large language models (MLLMs) on TableVQA-Bench. GPT-4V achieves the highest accuracy among commercial and open-sourced MLLMs from our experiments. Moreover, we discover that the number of vision queries plays a significant role in TableVQA performance. To further analyze the capabilities of MLLMs in comparison to their LLM backbones, we investigate by presenting image-formatted tables to MLLMs and text-formatted tables to LLMs, respectively. Our findings suggest that processing visual inputs is more challenging than text inputs, as evidenced by the lower performance of MLLMs, despite generally requiring higher computational costs than LLMs. The proposed TableVQA-Bench and evaluation codes are available at \href{https://github.com/naver-ai/tablevqabench}{https://github.com/naver-ai/tablevqabench}.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
SCOB: Universal Text Understanding via Character-wise Supervised Contrastive Learning with Online Text Rendering for Bridging Domain Gap
Sep 21, 2023


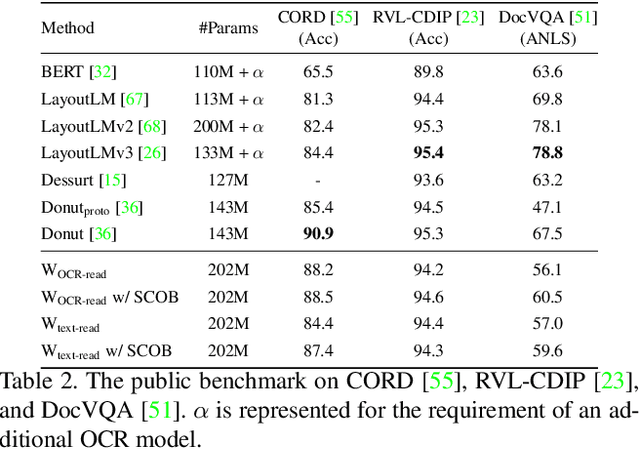
Inspired by the great success of language model (LM)-based pre-training, recent studies in visual document understanding have explored LM-based pre-training methods for modeling text within document images. Among them, pre-training that reads all text from an image has shown promise, but often exhibits instability and even fails when applied to broader domains, such as those involving both visual documents and scene text images. This is a substantial limitation for real-world scenarios, where the processing of text image inputs in diverse domains is essential. In this paper, we investigate effective pre-training tasks in the broader domains and also propose a novel pre-training method called SCOB that leverages character-wise supervised contrastive learning with online text rendering to effectively pre-train document and scene text domains by bridging the domain gap. Moreover, SCOB enables weakly supervised learning, significantly reducing annotation costs. Extensive benchmarks demonstrate that SCOB generally improves vanilla pre-training methods and achieves comparable performance to state-of-the-art methods. Our findings suggest that SCOB can be served generally and effectively for read-type pre-training methods. The code will be available at https://github.com/naver-ai/scob.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023
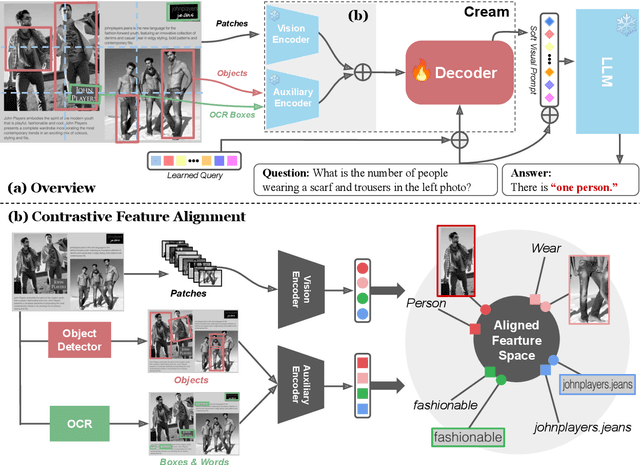

Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream
Towards Unified Scene Text Spotting based on Sequence Generation
Apr 07, 2023
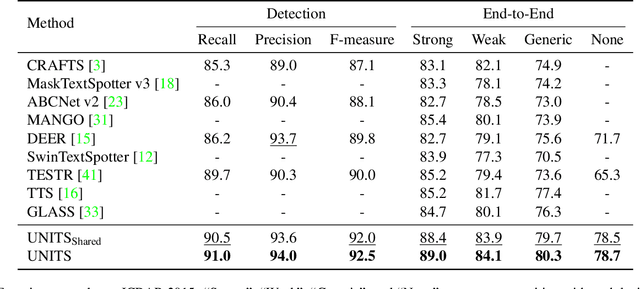

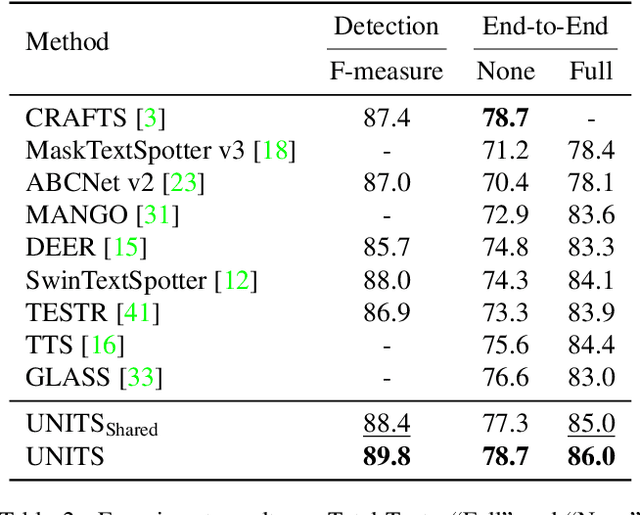
Sequence generation models have recently made significant progress in unifying various vision tasks. Although some auto-regressive models have demonstrated promising results in end-to-end text spotting, they use specific detection formats while ignoring various text shapes and are limited in the maximum number of text instances that can be detected. To overcome these limitations, we propose a UNIfied scene Text Spotter, called UNITS. Our model unifies various detection formats, including quadrilaterals and polygons, allowing it to detect text in arbitrary shapes. Additionally, we apply starting-point prompting to enable the model to extract texts from an arbitrary starting point, thereby extracting more texts beyond the number of instances it was trained on. Experimental results demonstrate that our method achieves competitive performance compared to state-of-the-art methods. Further analysis shows that UNITS can extract a larger number of texts than it was trained on. We provide the code for our method at https://github.com/clovaai/units.
Technical Report on Web-based Visual Corpus Construction for Visual Document Understanding
Nov 07, 2022



We present a dataset generator engine named Web-based Visual Corpus Builder (Webvicob). Webvicob can readily construct a large-scale visual corpus (i.e., images with text annotations) from a raw Wikipedia HTML dump. In this report, we validate that Webvicob-generated data can cover a wide range of context and knowledge and helps practitioners to build a powerful Visual Document Understanding (VDU) backbone. The proposed engine is publicly available at https://github.com/clovaai/webvicob.
DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting
Mar 10, 2022
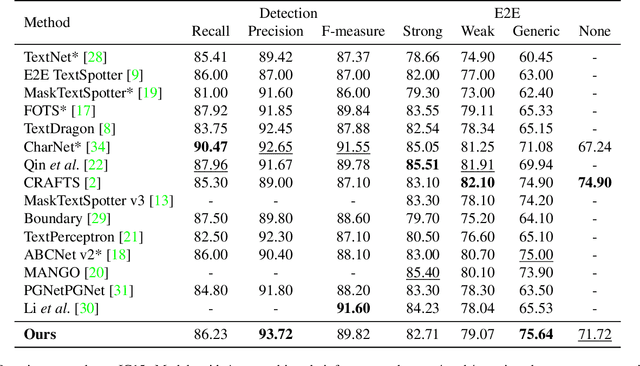
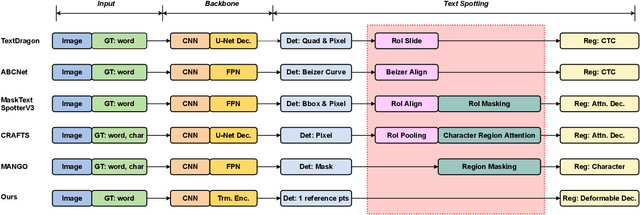
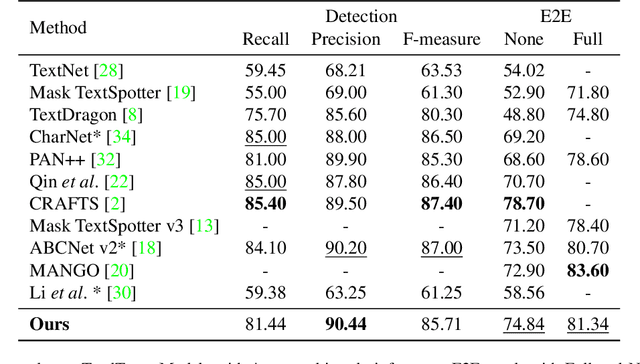
Recent end-to-end scene text spotters have achieved great improvement in recognizing arbitrary-shaped text instances. Common approaches for text spotting use region of interest pooling or segmentation masks to restrict features to single text instances. However, this makes it hard for the recognizer to decode correct sequences when the detection is not accurate i.e. one or more characters are cropped out. Considering that it is hard to accurately decide word boundaries with only the detector, we propose a novel Detection-agnostic End-to-End Recognizer, DEER, framework. The proposed method reduces the tight dependency between detection and recognition modules by bridging them with a single reference point for each text instance, instead of using detected regions. The proposed method allows the decoder to recognize the texts that are indicated by the reference point, with features from the whole image. Since only a single point is required to recognize the text, the proposed method enables text spotting without an arbitrarily-shaped detector or bounding polygon annotations. Experimental results present that the proposed method achieves competitive results on regular and arbitrarily-shaped text spotting benchmarks. Further analysis shows that DEER is robust to the detection errors. The code and dataset will be publicly available.
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Nov 30, 2021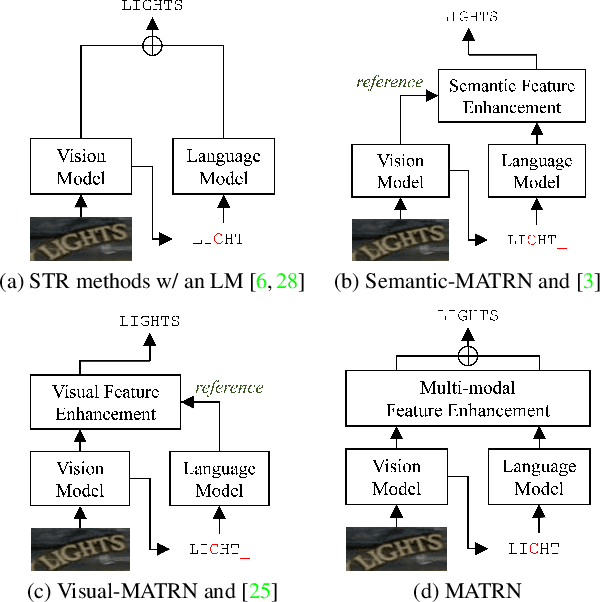
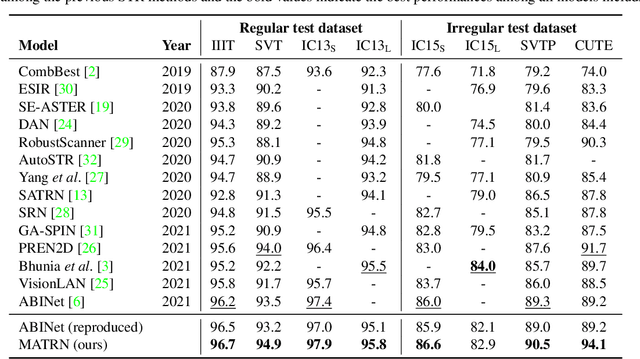
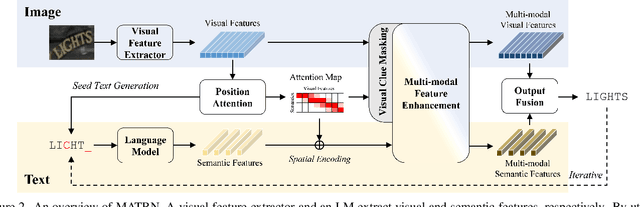
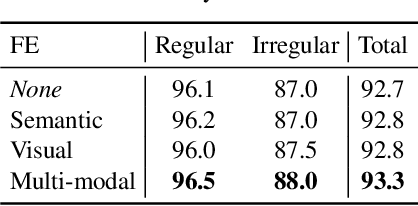
Linguistic knowledge has brought great benefits to scene text recognition by providing semantics to refine character sequences. However, since linguistic knowledge has been applied individually on the output sequence, previous methods have not fully utilized the semantics to understand visual clues for text recognition. This paper introduces a novel method, called Multi-modAl Text Recognition Network (MATRN), that enables interactions between visual and semantic features for better recognition performances. Specifically, MATRN identifies visual and semantic feature pairs and encodes spatial information into semantic features. Based on the spatial encoding, visual and semantic features are enhanced by referring to related features in the other modality. Furthermore, MATRN stimulates combining semantic features into visual features by hiding visual clues related to the character in the training phase. Our experiments demonstrate that MATRN achieves state-of-the-art performances on seven benchmarks with large margins, while naive combinations of two modalities show marginal improvements. Further ablative studies prove the effectiveness of our proposed components. Our implementation will be publicly available.
RewriteNet: Realistic Scene Text Image Generation via Editing Text in Real-world Image
Jul 23, 2021
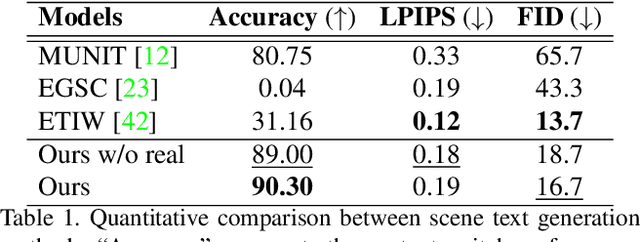
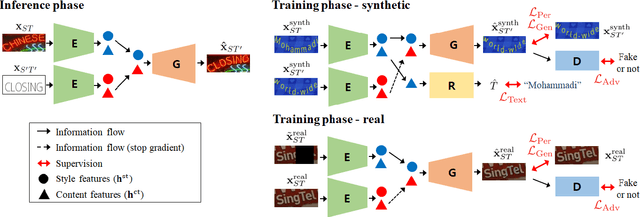
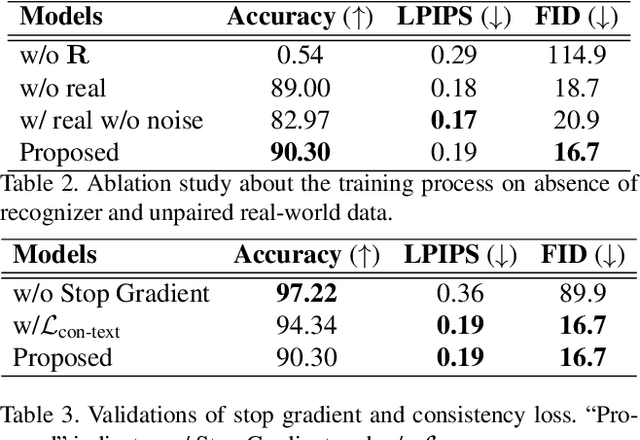
Scene text editing (STE), which converts a text in a scene image into the desired text while preserving an original style, is a challenging task due to a complex intervention between text and style. To address this challenge, we propose a novel representational learning-based STE model, referred to as RewriteNet that employs textual information as well as visual information. We assume that the scene text image can be decomposed into content and style features where the former represents the text information and style represents scene text characteristics such as font, alignment, and background. Under this assumption, we propose a method to separately encode content and style features of the input image by introducing the scene text recognizer that is trained by text information. Then, a text-edited image is generated by combining the style feature from the original image and the content feature from the target text. Unlike previous works that are only able to use synthetic images in the training phase, we also exploit real-world images by proposing a self-supervised training scheme, which bridges the domain gap between synthetic and real data. Our experiments demonstrate that RewriteNet achieves better quantitative and qualitative performance than other comparisons. Moreover, we validate that the use of text information and the self-supervised training scheme improves text switching performance. The implementation and dataset will be publicly available.
SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models
Jul 20, 2021

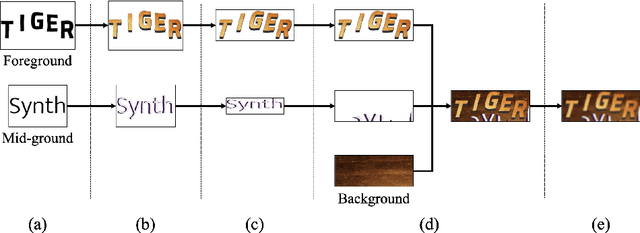
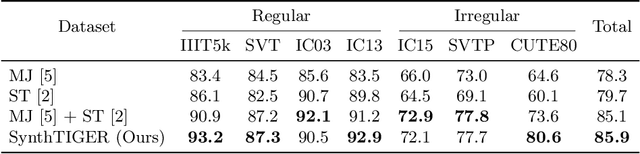
For successful scene text recognition (STR) models, synthetic text image generators have alleviated the lack of annotated text images from the real world. Specifically, they generate multiple text images with diverse backgrounds, font styles, and text shapes and enable STR models to learn visual patterns that might not be accessible from manually annotated data. In this paper, we introduce a new synthetic text image generator, SynthTIGER, by analyzing techniques used for text image synthesis and integrating effective ones under a single algorithm. Moreover, we propose two techniques that alleviate the long-tail problem in length and character distributions of training data. In our experiments, SynthTIGER achieves better STR performance than the combination of synthetic datasets, MJSynth (MJ) and SynthText (ST). Our ablation study demonstrates the benefits of using sub-components of SynthTIGER and the guideline on generating synthetic text images for STR models. Our implementation is publicly available at https://github.com/clovaai/synthtiger.