 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
Apr 30, 2024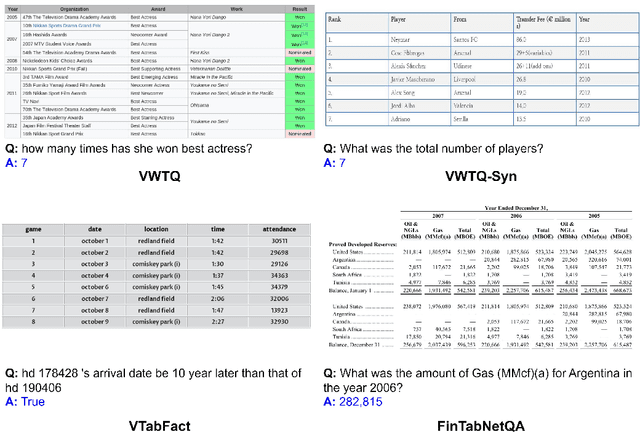
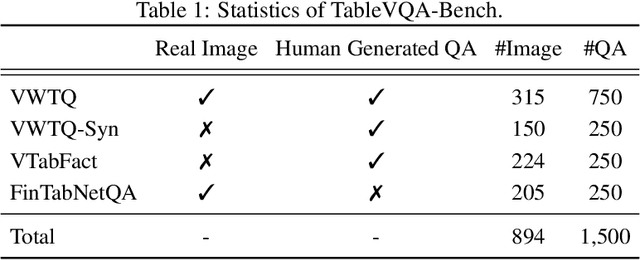
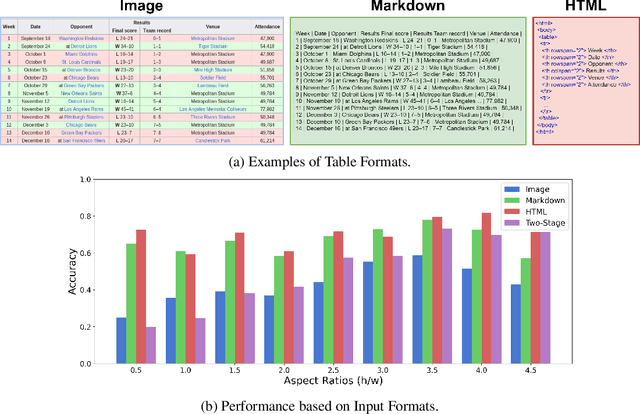
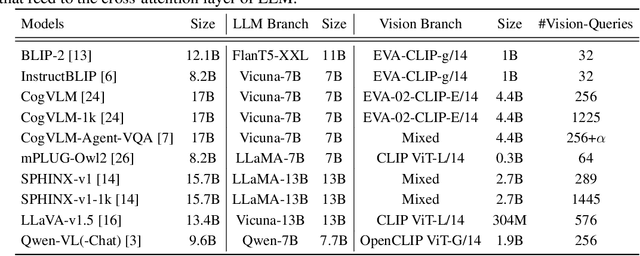
In this paper, we establish a benchmark for table visual question answering, referred to as the TableVQA-Bench, derived from pre-existing table question-answering (QA) and table structure recognition datasets. It is important to note that existing datasets have not incorporated images or QA pairs, which are two crucial components of TableVQA. As such, the primary objective of this paper is to obtain these necessary components. Specifically, images are sourced either through the application of a \textit{stylesheet} or by employing the proposed table rendering system. QA pairs are generated by exploiting the large language model (LLM) where the input is a text-formatted table. Ultimately, the completed TableVQA-Bench comprises 1,500 QA pairs. We comprehensively compare the performance of various multi-modal large language models (MLLMs) on TableVQA-Bench. GPT-4V achieves the highest accuracy among commercial and open-sourced MLLMs from our experiments. Moreover, we discover that the number of vision queries plays a significant role in TableVQA performance. To further analyze the capabilities of MLLMs in comparison to their LLM backbones, we investigate by presenting image-formatted tables to MLLMs and text-formatted tables to LLMs, respectively. Our findings suggest that processing visual inputs is more challenging than text inputs, as evidenced by the lower performance of MLLMs, despite generally requiring higher computational costs than LLMs. The proposed TableVQA-Bench and evaluation codes are available at \href{https://github.com/naver-ai/tablevqabench}{https://github.com/naver-ai/tablevqabench}.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.