 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableVQA-Bench: A Visual Question Answering Benchmark on Multiple Table Domains
Apr 30, 2024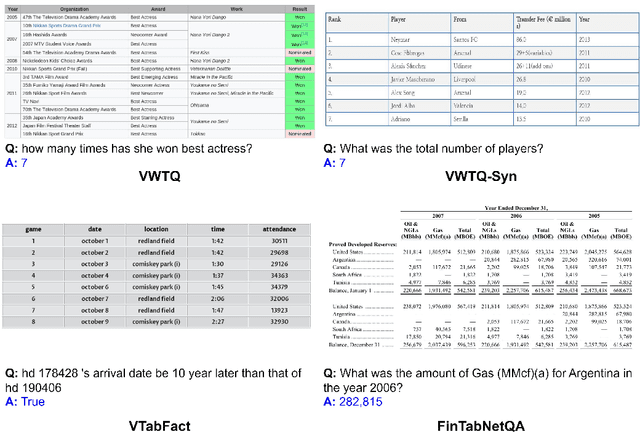
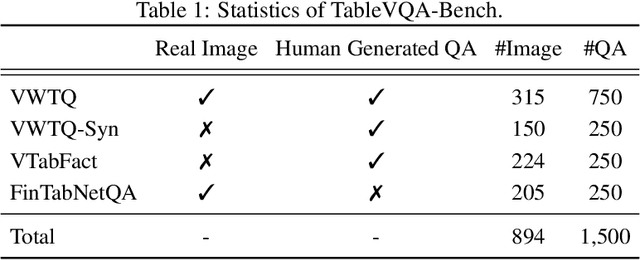
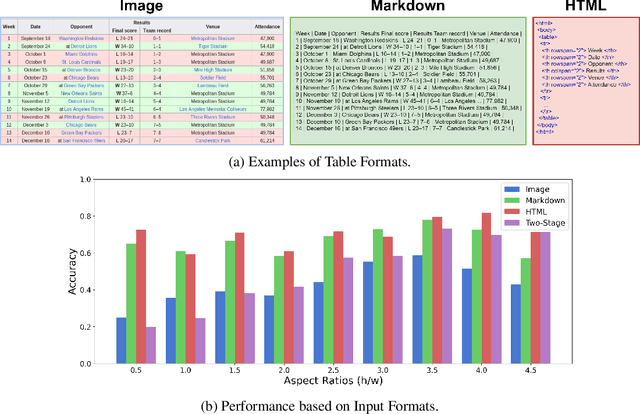
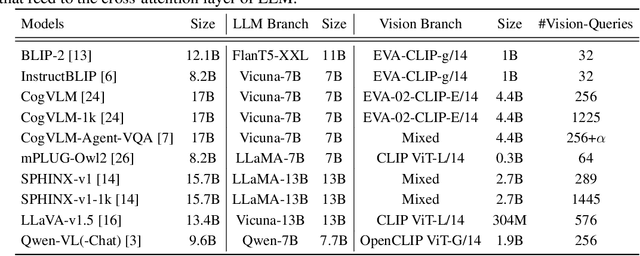
In this paper, we establish a benchmark for table visual question answering, referred to as the TableVQA-Bench, derived from pre-existing table question-answering (QA) and table structure recognition datasets. It is important to note that existing datasets have not incorporated images or QA pairs, which are two crucial components of TableVQA. As such, the primary objective of this paper is to obtain these necessary components. Specifically, images are sourced either through the application of a \textit{stylesheet} or by employing the proposed table rendering system. QA pairs are generated by exploiting the large language model (LLM) where the input is a text-formatted table. Ultimately, the completed TableVQA-Bench comprises 1,500 QA pairs. We comprehensively compare the performance of various multi-modal large language models (MLLMs) on TableVQA-Bench. GPT-4V achieves the highest accuracy among commercial and open-sourced MLLMs from our experiments. Moreover, we discover that the number of vision queries plays a significant role in TableVQA performance. To further analyze the capabilities of MLLMs in comparison to their LLM backbones, we investigate by presenting image-formatted tables to MLLMs and text-formatted tables to LLMs, respectively. Our findings suggest that processing visual inputs is more challenging than text inputs, as evidenced by the lower performance of MLLMs, despite generally requiring higher computational costs than LLMs. The proposed TableVQA-Bench and evaluation codes are available at \href{https://github.com/naver-ai/tablevqabench}{https://github.com/naver-ai/tablevqabench}.
Technical Report on Web-based Visual Corpus Construction for Visual Document Understanding
Nov 07, 2022



We present a dataset generator engine named Web-based Visual Corpus Builder (Webvicob). Webvicob can readily construct a large-scale visual corpus (i.e., images with text annotations) from a raw Wikipedia HTML dump. In this report, we validate that Webvicob-generated data can cover a wide range of context and knowledge and helps practitioners to build a powerful Visual Document Understanding (VDU) backbone. The proposed engine is publicly available at https://github.com/clovaai/webvicob.
Donut: Document Understanding Transformer without OCR
Nov 30, 2021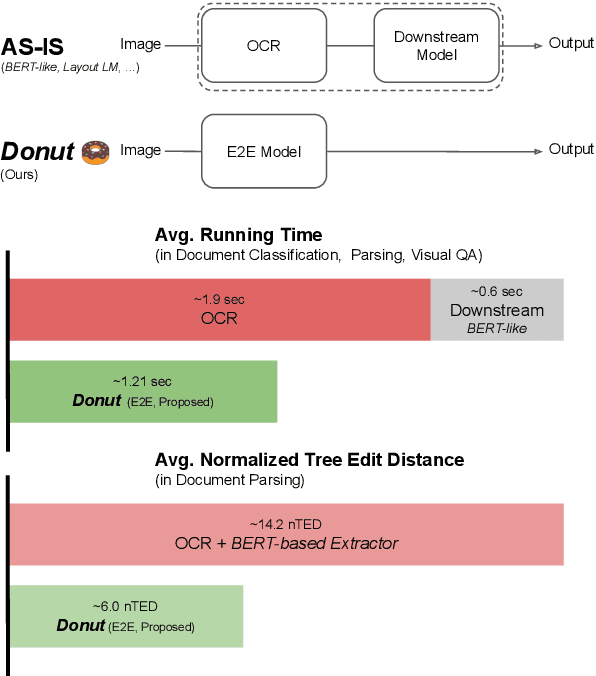
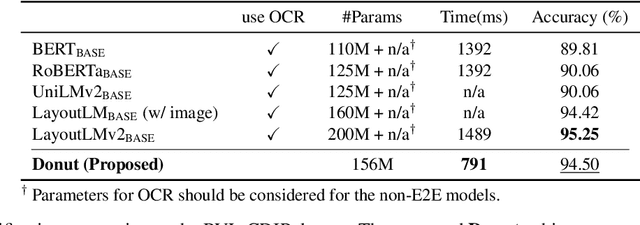
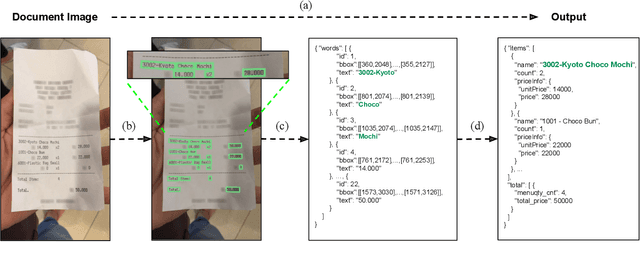

Understanding document images (e.g., invoices) has been an important research topic and has many applications in document processing automation. Through the latest advances in deep learning-based Optical Character Recognition (OCR), current Visual Document Understanding (VDU) systems have come to be designed based on OCR. Although such OCR-based approach promise reasonable performance, they suffer from critical problems induced by the OCR, e.g., (1) expensive computational costs and (2) performance degradation due to the OCR error propagation. In this paper, we propose a novel VDU model that is end-to-end trainable without underpinning OCR framework. To this end, we propose a new task and a synthetic document image generator to pre-train the model to mitigate the dependencies on large-scale real document images. Our approach achieves state-of-the-art performance on various document understanding tasks in public benchmark datasets and private industrial service datasets. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed model especially with consideration for a real-world application.
RewriteNet: Realistic Scene Text Image Generation via Editing Text in Real-world Image
Jul 23, 2021
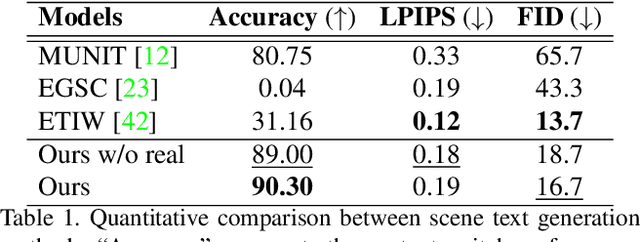
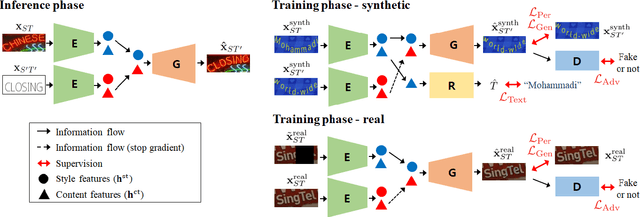
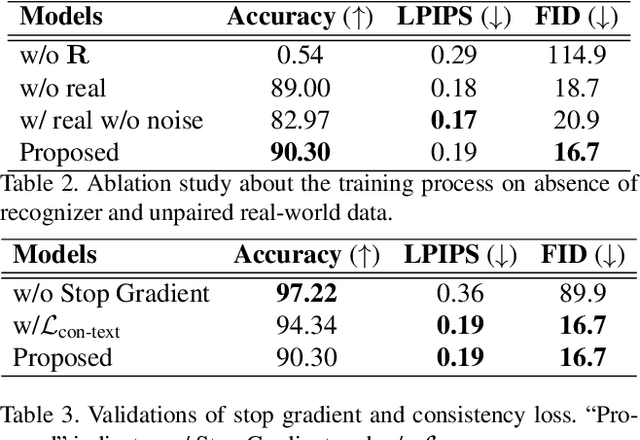
Scene text editing (STE), which converts a text in a scene image into the desired text while preserving an original style, is a challenging task due to a complex intervention between text and style. To address this challenge, we propose a novel representational learning-based STE model, referred to as RewriteNet that employs textual information as well as visual information. We assume that the scene text image can be decomposed into content and style features where the former represents the text information and style represents scene text characteristics such as font, alignment, and background. Under this assumption, we propose a method to separately encode content and style features of the input image by introducing the scene text recognizer that is trained by text information. Then, a text-edited image is generated by combining the style feature from the original image and the content feature from the target text. Unlike previous works that are only able to use synthetic images in the training phase, we also exploit real-world images by proposing a self-supervised training scheme, which bridges the domain gap between synthetic and real data. Our experiments demonstrate that RewriteNet achieves better quantitative and qualitative performance than other comparisons. Moreover, we validate that the use of text information and the self-supervised training scheme improves text switching performance. The implementation and dataset will be publicly available.
SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models
Jul 20, 2021

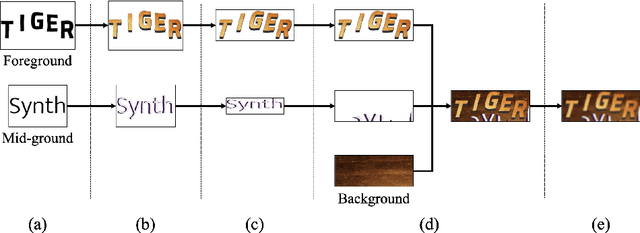
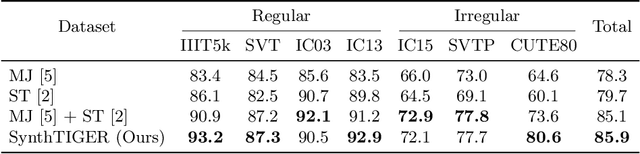
For successful scene text recognition (STR) models, synthetic text image generators have alleviated the lack of annotated text images from the real world. Specifically, they generate multiple text images with diverse backgrounds, font styles, and text shapes and enable STR models to learn visual patterns that might not be accessible from manually annotated data. In this paper, we introduce a new synthetic text image generator, SynthTIGER, by analyzing techniques used for text image synthesis and integrating effective ones under a single algorithm. Moreover, we propose two techniques that alleviate the long-tail problem in length and character distributions of training data. In our experiments, SynthTIGER achieves better STR performance than the combination of synthetic datasets, MJSynth (MJ) and SynthText (ST). Our ablation study demonstrates the benefits of using sub-components of SynthTIGER and the guideline on generating synthetic text images for STR models. Our implementation is publicly available at https://github.com/clovaai/synthtiger.