 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCReSt: A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents
May 23, 2025



Large Language Models (LLMs) have made substantial progress in recent years, yet evaluating their capabilities in practical Retrieval-Augmented Generation (RAG) scenarios remains challenging. In practical applications, LLMs must demonstrate complex reasoning, refuse to answer appropriately, provide precise citations, and effectively understand document layout. These capabilities are crucial for advanced task handling, uncertainty awareness, maintaining reliability, and structural understanding. While some of the prior works address these aspects individually, there is a need for a unified framework that evaluates them collectively in practical RAG scenarios. To address this, we present CReSt (A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents), a benchmark designed to assess these key dimensions holistically. CReSt comprises 2,245 human-annotated examples in English and Korean, designed to capture practical RAG scenarios that require complex reasoning over structured documents. It also introduces a tailored evaluation methodology to comprehensively assess model performance in these critical areas. Our evaluation shows that even advanced LLMs struggle to perform consistently across these dimensions, underscoring key areas for improvement. We release CReSt to support further research and the development of more robust RAG systems. The dataset and code are available at: https://github.com/UpstageAI/CReSt.
KIEval: Evaluation Metric for Document Key Information Extraction
Mar 07, 2025



Document Key Information Extraction (KIE) is a technology that transforms valuable information in document images into structured data, and it has become an essential function in industrial settings. However, current evaluation metrics of this technology do not accurately reflect the critical attributes of its industrial applications. In this paper, we present KIEval, a novel application-centric evaluation metric for Document KIE models. Unlike prior metrics, KIEval assesses Document KIE models not just on the extraction of individual information (entity) but also of the structured information (grouping). Evaluation of structured information provides assessment of Document KIE models that are more reflective of extracting grouped information from documents in industrial settings. Designed with industrial application in mind, we believe that KIEval can become a standard evaluation metric for developing or applying Document KIE models in practice. The code will be publicly available.
TFLOP: Table Structure Recognition Framework with Layout Pointer Mechanism
Jan 21, 2025



Table Structure Recognition (TSR) is a task aimed at converting table images into a machine-readable format (e.g. HTML), to facilitate other applications such as information retrieval. Recent works tackle this problem by identifying the HTML tags and text regions, where the latter is used for text extraction from the table document. These works however, suffer from misalignment issues when mapping text into the identified text regions. In this paper, we introduce a new TSR framework, called TFLOP (TSR Framework with LayOut Pointer mechanism), which reformulates the conventional text region prediction and matching into a direct text region pointing problem. Specifically, TFLOP utilizes text region information to identify both the table's structure tags and its aligned text regions, simultaneously. Without the need for region prediction and alignment, TFLOP circumvents the additional text region matching stage, which requires finely-calibrated post-processing. TFLOP also employs span-aware contrastive supervision to enhance the pointing mechanism in tables with complex structure. As a result, TFLOP achieves the state-of-the-art performance across multiple benchmarks such as PubTabNet, FinTabNet, and SynthTabNet. In our extensive experiments, TFLOP not only exhibits competitive performance but also shows promising results on industrial document TSR scenarios such as documents with watermarks or in non-English domain.
Technical Report on Web-based Visual Corpus Construction for Visual Document Understanding
Nov 07, 2022



We present a dataset generator engine named Web-based Visual Corpus Builder (Webvicob). Webvicob can readily construct a large-scale visual corpus (i.e., images with text annotations) from a raw Wikipedia HTML dump. In this report, we validate that Webvicob-generated data can cover a wide range of context and knowledge and helps practitioners to build a powerful Visual Document Understanding (VDU) backbone. The proposed engine is publicly available at https://github.com/clovaai/webvicob.
Donut: Document Understanding Transformer without OCR
Nov 30, 2021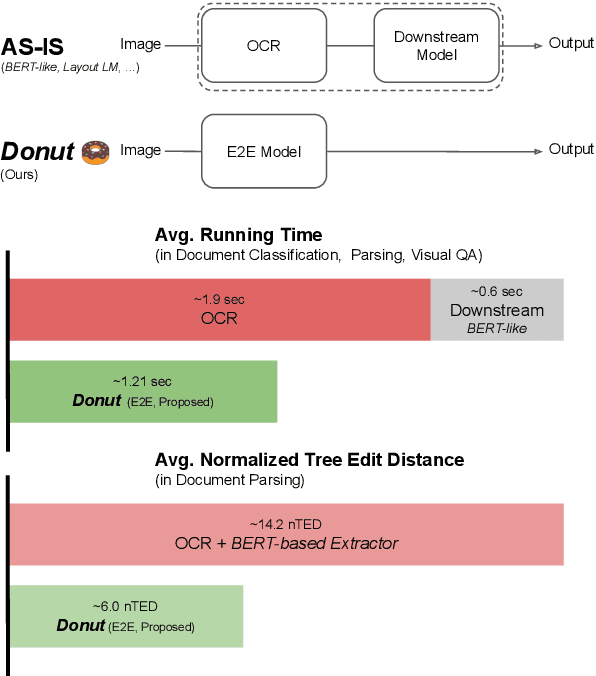
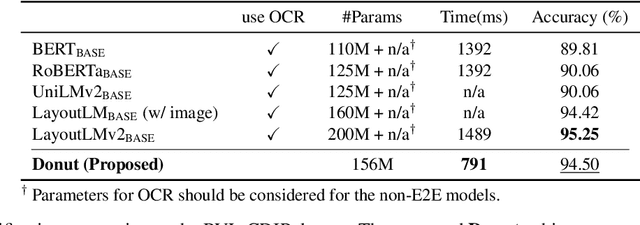
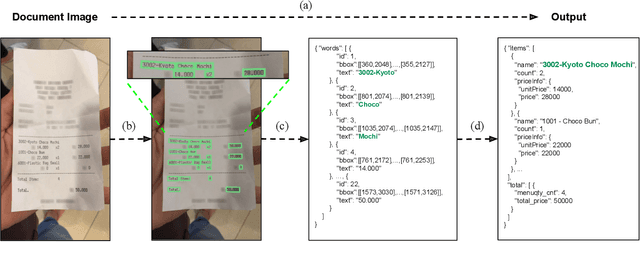

Understanding document images (e.g., invoices) has been an important research topic and has many applications in document processing automation. Through the latest advances in deep learning-based Optical Character Recognition (OCR), current Visual Document Understanding (VDU) systems have come to be designed based on OCR. Although such OCR-based approach promise reasonable performance, they suffer from critical problems induced by the OCR, e.g., (1) expensive computational costs and (2) performance degradation due to the OCR error propagation. In this paper, we propose a novel VDU model that is end-to-end trainable without underpinning OCR framework. To this end, we propose a new task and a synthetic document image generator to pre-train the model to mitigate the dependencies on large-scale real document images. Our approach achieves state-of-the-art performance on various document understanding tasks in public benchmark datasets and private industrial service datasets. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed model especially with consideration for a real-world application.
HoughCL: Finding Better Positive Pairs in Dense Self-supervised Learning
Nov 21, 2021
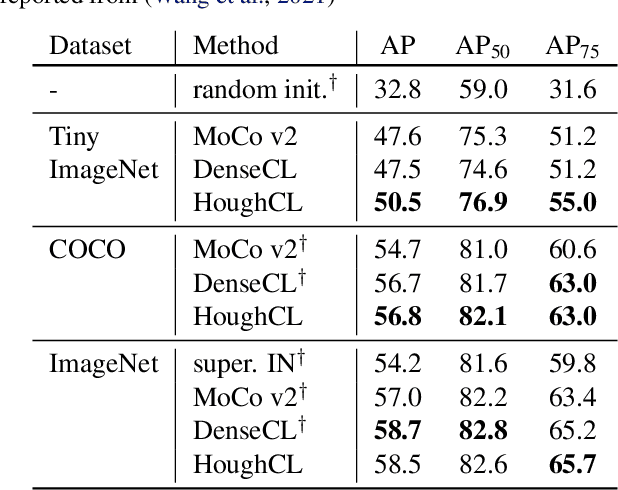
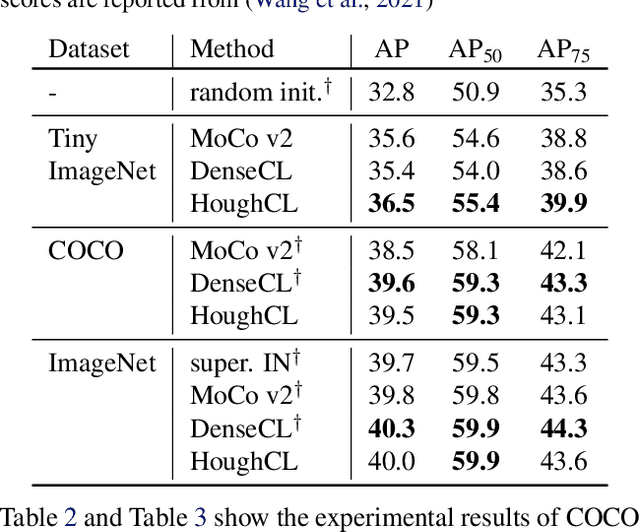
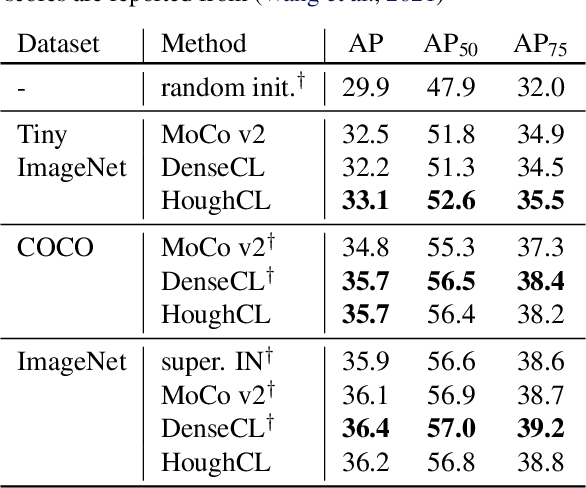
Recently, self-supervised methods show remarkable achievements in image-level representation learning. Nevertheless, their image-level self-supervisions lead the learned representation to sub-optimal for dense prediction tasks, such as object detection, instance segmentation, etc. To tackle this issue, several recent self-supervised learning methods have extended image-level single embedding to pixel-level dense embeddings. Unlike image-level representation learning, due to the spatial deformation of augmentation, it is difficult to sample pixel-level positive pairs. Previous studies have sampled pixel-level positive pairs using the winner-takes-all among similarity or thresholding warped distance between dense embeddings. However, these naive methods can be struggled by background clutter and outliers problems. In this paper, we introduce Hough Contrastive Learning (HoughCL), a Hough space based method that enforces geometric consistency between two dense features. HoughCL achieves robustness against background clutter and outliers. Furthermore, compared to baseline, our dense positive pairing method has no additional learnable parameters and has a small extra computation cost. Compared to previous works, our method shows better or comparable performance on dense prediction fine-tuning tasks.
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
Sep 10, 2021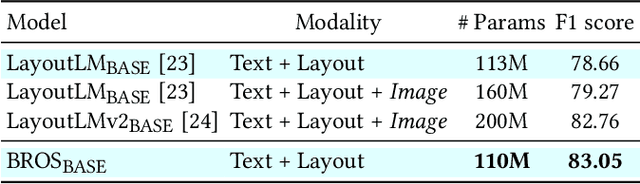
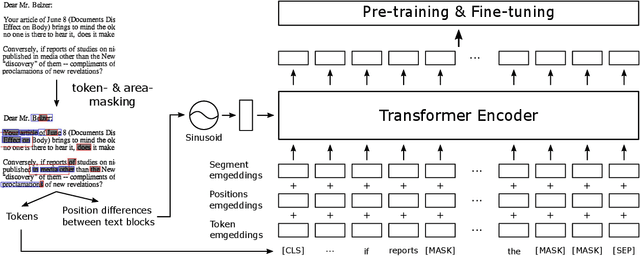

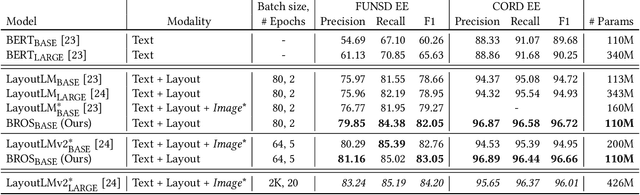
Key information extraction (KIE) from document images requires understanding the contextual and spatial semantics of texts in two-dimensional (2D) space. Many recent studies try to solve the task by developing pre-training language models focusing on combining visual features from document images with texts and their layout. On the other hand, this paper tackles the problem by going back to the basic: effective combination of text and layout. Specifically, we propose a pre-trained language model, named BROS (BERT Relying On Spatiality), that encodes relative positions of texts in 2D space and learns from unlabeled documents with area-masking strategy. With this optimized training scheme for understanding texts in 2D space, BROS shows comparable or better performance compared to previous methods on four KIE benchmarks (FUNSD, SROIE*, CORD, and SciTSR) without relying on visual features. This paper also reveals two real-world challenges in KIE tasks--(1) minimizing the error from incorrect text ordering and (2) efficient learning from fewer downstream examples--and demonstrates the superiority of BROS over previous methods. Our code will be open to the public.