 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
CReSt: A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents
May 23, 2025



Large Language Models (LLMs) have made substantial progress in recent years, yet evaluating their capabilities in practical Retrieval-Augmented Generation (RAG) scenarios remains challenging. In practical applications, LLMs must demonstrate complex reasoning, refuse to answer appropriately, provide precise citations, and effectively understand document layout. These capabilities are crucial for advanced task handling, uncertainty awareness, maintaining reliability, and structural understanding. While some of the prior works address these aspects individually, there is a need for a unified framework that evaluates them collectively in practical RAG scenarios. To address this, we present CReSt (A Comprehensive Benchmark for Retrieval-Augmented Generation with Complex Reasoning over Structured Documents), a benchmark designed to assess these key dimensions holistically. CReSt comprises 2,245 human-annotated examples in English and Korean, designed to capture practical RAG scenarios that require complex reasoning over structured documents. It also introduces a tailored evaluation methodology to comprehensively assess model performance in these critical areas. Our evaluation shows that even advanced LLMs struggle to perform consistently across these dimensions, underscoring key areas for improvement. We release CReSt to support further research and the development of more robust RAG systems. The dataset and code are available at: https://github.com/UpstageAI/CReSt.
KIEval: Evaluation Metric for Document Key Information Extraction
Mar 07, 2025



Document Key Information Extraction (KIE) is a technology that transforms valuable information in document images into structured data, and it has become an essential function in industrial settings. However, current evaluation metrics of this technology do not accurately reflect the critical attributes of its industrial applications. In this paper, we present KIEval, a novel application-centric evaluation metric for Document KIE models. Unlike prior metrics, KIEval assesses Document KIE models not just on the extraction of individual information (entity) but also of the structured information (grouping). Evaluation of structured information provides assessment of Document KIE models that are more reflective of extracting grouped information from documents in industrial settings. Designed with industrial application in mind, we believe that KIEval can become a standard evaluation metric for developing or applying Document KIE models in practice. The code will be publicly available.
TFLOP: Table Structure Recognition Framework with Layout Pointer Mechanism
Jan 21, 2025



Table Structure Recognition (TSR) is a task aimed at converting table images into a machine-readable format (e.g. HTML), to facilitate other applications such as information retrieval. Recent works tackle this problem by identifying the HTML tags and text regions, where the latter is used for text extraction from the table document. These works however, suffer from misalignment issues when mapping text into the identified text regions. In this paper, we introduce a new TSR framework, called TFLOP (TSR Framework with LayOut Pointer mechanism), which reformulates the conventional text region prediction and matching into a direct text region pointing problem. Specifically, TFLOP utilizes text region information to identify both the table's structure tags and its aligned text regions, simultaneously. Without the need for region prediction and alignment, TFLOP circumvents the additional text region matching stage, which requires finely-calibrated post-processing. TFLOP also employs span-aware contrastive supervision to enhance the pointing mechanism in tables with complex structure. As a result, TFLOP achieves the state-of-the-art performance across multiple benchmarks such as PubTabNet, FinTabNet, and SynthTabNet. In our extensive experiments, TFLOP not only exhibits competitive performance but also shows promising results on industrial document TSR scenarios such as documents with watermarks or in non-English domain.
Model-Based Data-Centric AI: Bridging the Divide Between Academic Ideals and Industrial Pragmatism
Mar 04, 2024This paper delves into the contrasting roles of data within academic and industrial spheres, highlighting the divergence between Data-Centric AI and Model-Agnostic AI approaches. We argue that while Data-Centric AI focuses on the primacy of high-quality data for model performance, Model-Agnostic AI prioritizes algorithmic flexibility, often at the expense of data quality considerations. This distinction reveals that academic standards for data quality frequently do not meet the rigorous demands of industrial applications, leading to potential pitfalls in deploying academic models in real-world settings. Through a comprehensive analysis, we address these disparities, presenting both the challenges they pose and strategies for bridging the gap. Furthermore, we propose a novel paradigm: Model-Based Data-Centric AI, which aims to reconcile these differences by integrating model considerations into data optimization processes. This approach underscores the necessity for evolving data requirements that are sensitive to the nuances of both academic research and industrial deployment. By exploring these discrepancies, we aim to foster a more nuanced understanding of data's role in AI development and encourage a convergence of academic and industrial standards to enhance AI's real-world applicability.
SRFormer: Empowering Regression-Based Text Detection Transformer with Segmentation
Aug 21, 2023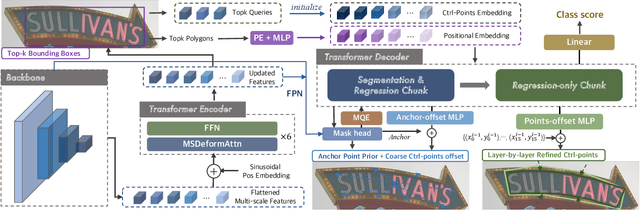
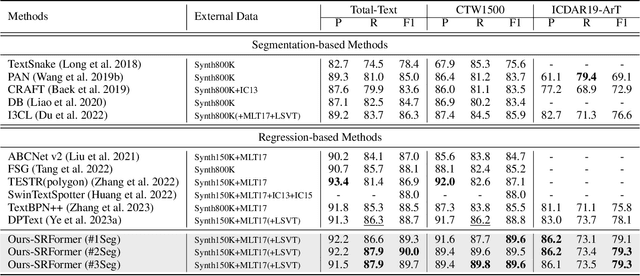
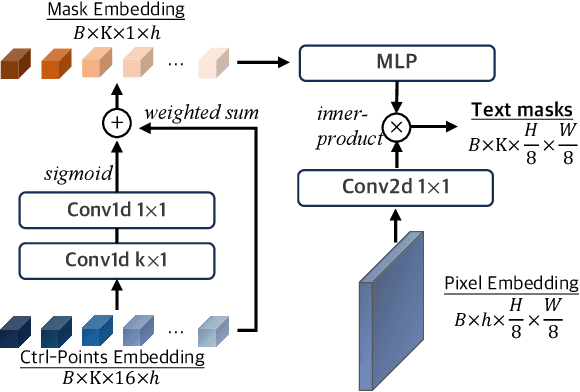
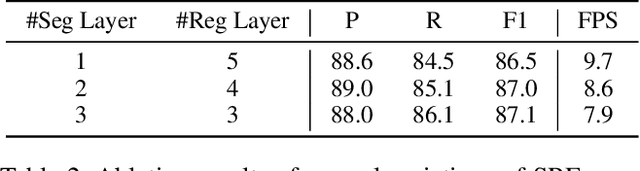
Existing techniques for text detection can be broadly classified into two primary groups: segmentation-based methods and regression-based methods. Segmentation models offer enhanced robustness to font variations but require intricate post-processing, leading to high computational overhead. Regression-based methods undertake instance-aware prediction but face limitations in robustness and data efficiency due to their reliance on high-level representations. In our academic pursuit, we propose SRFormer, a unified DETR-based model with amalgamated Segmentation and Regression, aiming at the synergistic harnessing of the inherent robustness in segmentation representations, along with the straightforward post-processing of instance-level regression. Our empirical analysis indicates that favorable segmentation predictions can be obtained at the initial decoder layers. In light of this, we constrain the incorporation of segmentation branches to the first few decoder layers and employ progressive regression refinement in subsequent layers, achieving performance gains while minimizing additional computational load from the mask. Furthermore, we propose a Mask-informed Query Enhancement module. We take the segmentation result as a natural soft-ROI to pool and extract robust pixel representations, which are then employed to enhance and diversify instance queries. Extensive experimentation across multiple benchmarks has yielded compelling findings, highlighting our method's exceptional robustness, superior training and data efficiency, as well as its state-of-the-art performance.