 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRFormer: Empowering Regression-Based Text Detection Transformer with Segmentation
Paper and Code
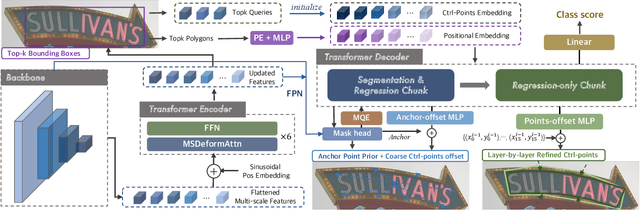
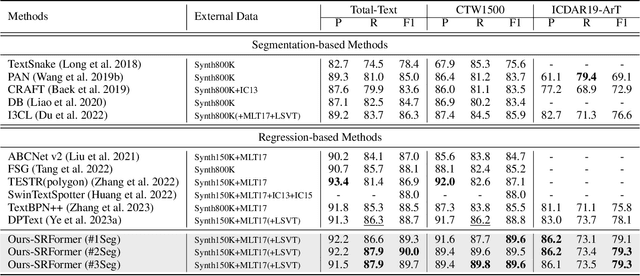
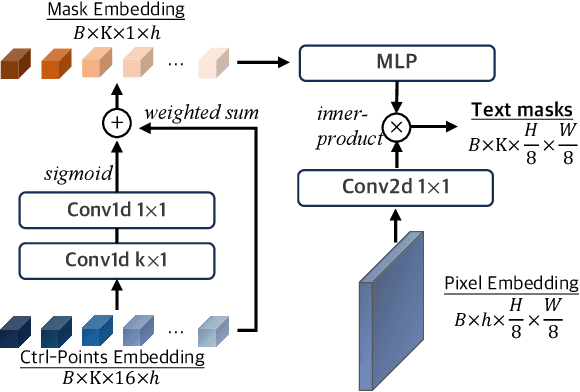
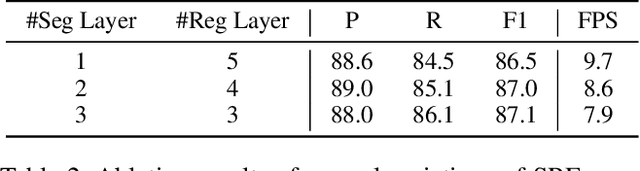
Existing techniques for text detection can be broadly classified into two primary groups: segmentation-based methods and regression-based methods. Segmentation models offer enhanced robustness to font variations but require intricate post-processing, leading to high computational overhead. Regression-based methods undertake instance-aware prediction but face limitations in robustness and data efficiency due to their reliance on high-level representations. In our academic pursuit, we propose SRFormer, a unified DETR-based model with amalgamated Segmentation and Regression, aiming at the synergistic harnessing of the inherent robustness in segmentation representations, along with the straightforward post-processing of instance-level regression. Our empirical analysis indicates that favorable segmentation predictions can be obtained at the initial decoder layers. In light of this, we constrain the incorporation of segmentation branches to the first few decoder layers and employ progressive regression refinement in subsequent layers, achieving performance gains while minimizing additional computational load from the mask. Furthermore, we propose a Mask-informed Query Enhancement module. We take the segmentation result as a natural soft-ROI to pool and extract robust pixel representations, which are then employed to enhance and diversify instance queries. Extensive experimentation across multiple benchmarks has yielded compelling findings, highlighting our method's exceptional robustness, superior training and data efficiency, as well as its state-of-the-art performance.