 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREPE: Coordinate-Aware End-to-End Document Parser
May 01, 2024



In this study, we formulate an OCR-free sequence generation model for visual document understanding (VDU). Our model not only parses text from document images but also extracts the spatial coordinates of the text based on the multi-head architecture. Named as Coordinate-aware End-to-end Document Parser (CREPE), our method uniquely integrates these capabilities by introducing a special token for OCR text, and token-triggered coordinate decoding. We also proposed a weakly-supervised framework for cost-efficient training, requiring only parsing annotations without high-cost coordinate annotations. Our experimental evaluations demonstrate CREPE's state-of-the-art performances on document parsing tasks. Beyond that, CREPE's adaptability is further highlighted by its successful usage in other document understanding tasks such as layout analysis, document visual question answering, and so one. CREPE's abilities including OCR and semantic parsing not only mitigate error propagation issues in existing OCR-dependent methods, it also significantly enhance the functionality of sequence generation models, ushering in a new era for document understanding studies.
SCOB: Universal Text Understanding via Character-wise Supervised Contrastive Learning with Online Text Rendering for Bridging Domain Gap
Sep 21, 2023


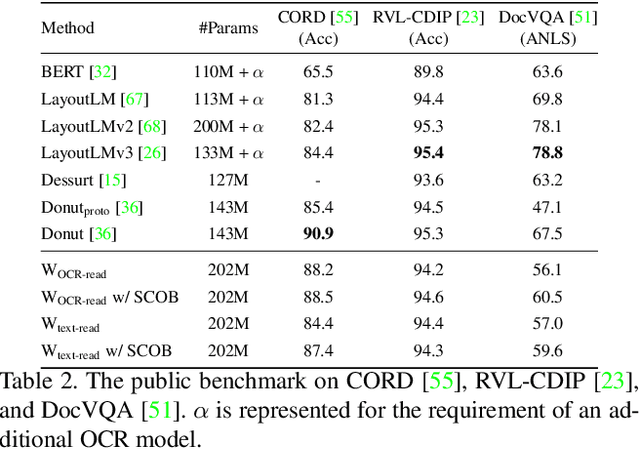
Inspired by the great success of language model (LM)-based pre-training, recent studies in visual document understanding have explored LM-based pre-training methods for modeling text within document images. Among them, pre-training that reads all text from an image has shown promise, but often exhibits instability and even fails when applied to broader domains, such as those involving both visual documents and scene text images. This is a substantial limitation for real-world scenarios, where the processing of text image inputs in diverse domains is essential. In this paper, we investigate effective pre-training tasks in the broader domains and also propose a novel pre-training method called SCOB that leverages character-wise supervised contrastive learning with online text rendering to effectively pre-train document and scene text domains by bridging the domain gap. Moreover, SCOB enables weakly supervised learning, significantly reducing annotation costs. Extensive benchmarks demonstrate that SCOB generally improves vanilla pre-training methods and achieves comparable performance to state-of-the-art methods. Our findings suggest that SCOB can be served generally and effectively for read-type pre-training methods. The code will be available at https://github.com/naver-ai/scob.