 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Multimodal Generative AI with Korean Educational Standards
Feb 21, 2025This paper presents the Korean National Educational Test Benchmark (KoNET), a new benchmark designed to evaluate Multimodal Generative AI Systems using Korean national educational tests. KoNET comprises four exams: the Korean Elementary General Educational Development Test (KoEGED), Middle (KoMGED), High (KoHGED), and College Scholastic Ability Test (KoCSAT). These exams are renowned for their rigorous standards and diverse questions, facilitating a comprehensive analysis of AI performance across different educational levels. By focusing on Korean, KoNET provides insights into model performance in less-explored languages. We assess a range of models - open-source, open-access, and closed APIs - by examining difficulties, subject diversity, and human error rates. The code and dataset builder will be made fully open-sourced at https://github.com/naver-ai/KoNET.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023
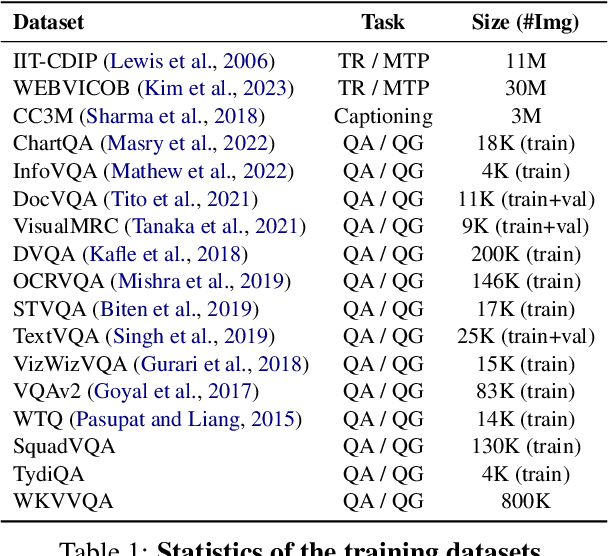
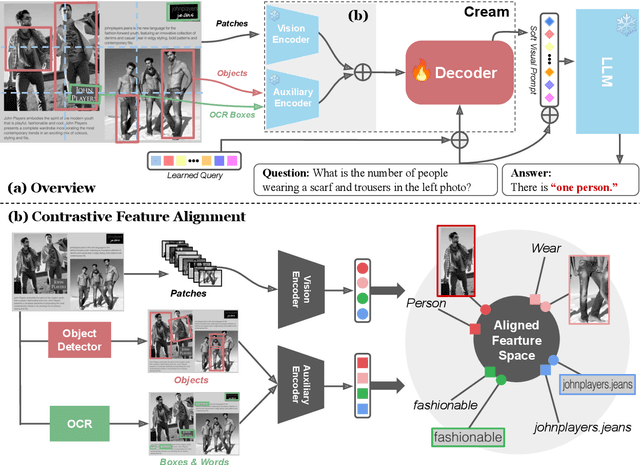

Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream