 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Failure Detection and Intervention in Video Diffusion Models
Mar 15, 2026Text-to-video (T2V) diffusion models have rapidly advanced, yet generations still occasionally fail in practice, such as low text-video alignment or low perceptual quality. Since diffusion sampling is non-deterministic, it is difficult to know during inference whether a generation will succeed or fail, incurring high computational cost due to trial-and-error regeneration. To address this, we propose an early failure detection and diagnostic intervention pipeline for latent T2V diffusion models. For detection, we design a Real-time Inspection (RI) module that converts latents into intermediate video previews, enabling the use of established text-video alignment scorers for inspection in the RGB space. The RI module completes the conversion and inspection process in just 39.2ms. This is highly efficient considering that CogVideoX-5B requires 4.3s per denoising step when generating a 480p, 49-frame video on an NVIDIA A100 GPU. Subsequently, we trigger a hierarchical and early-exit intervention pipeline only when failure is predicted. Experiments on CogVideoX-5B and Wan2.1-1.3B demonstrate consistency gains on VBench with up to 2.64 times less time overhead compared to post-hoc regeneration. Our method also generalizes to a higher-capacity setting, remaining effective on Wan2.1-14B with 720p resolution and 81-frame generation. Furthermore, our pipeline is plug-and-play and orthogonal to existing techniques, showing seamless compatibility with prompt refinement and sampling guidance methods. We also provide evidence that failure signals emerge early in the denoising process and are detectable within intermediate video previews using standard vision-language evaluators.
GaussExplorer: 3D Gaussian Splatting for Embodied Exploration and Reasoning
Jan 19, 2026We present GaussExplorer, a framework for embodied exploration and reasoning built on 3D Gaussian Splatting (3DGS). While prior approaches to language-embedded 3DGS have made meaningful progress in aligning simple text queries with Gaussian embeddings, they are generally optimized for relatively simple queries and struggle to interpret more complex, compositional language queries. Alternative studies based on object-centric RGB-D structured memories provide spatial grounding but are constrained by pre-fixed viewpoints. To address these issues, GaussExplorer introduces Vision-Language Models (VLMs) on top of 3DGS to enable question-driven exploration and reasoning within 3D scenes. We first identify pre-captured images that are most correlated with the query question, and subsequently adjust them into novel viewpoints to more accurately capture visual information for better reasoning by VLMs. Experiments show that ours outperforms existing methods on several benchmarks, demonstrating the effectiveness of integrating VLM-based reasoning with 3DGS for embodied tasks.
Patch-wise Retrieval: A Bag of Practical Techniques for Instance-level Matching
Dec 14, 2025Instance-level image retrieval aims to find images containing the same object as a given query, despite variations in size, position, or appearance. To address this challenging task, we propose Patchify, a simple yet effective patch-wise retrieval framework that offers high performance, scalability, and interpretability without requiring fine-tuning. Patchify divides each database image into a small number of structured patches and performs retrieval by comparing these local features with a global query descriptor, enabling accurate and spatially grounded matching. To assess not just retrieval accuracy but also spatial correctness, we introduce LocScore, a localization-aware metric that quantifies whether the retrieved region aligns with the target object. This makes LocScore a valuable diagnostic tool for understanding and improving retrieval behavior. We conduct extensive experiments across multiple benchmarks, backbones, and region selection strategies, showing that Patchify outperforms global methods and complements state-of-the-art reranking pipelines. Furthermore, we apply Product Quantization for efficient large-scale retrieval and highlight the importance of using informative features during compression, which significantly boosts performance. Project website: https://wons20k.github.io/PatchwiseRetrieval/
BEAF: Observing BEfore-AFter Changes to Evaluate Hallucination in Vision-language Models
Jul 18, 2024



Vision language models (VLMs) perceive the world through a combination of a visual encoder and a large language model (LLM). The visual encoder, pre-trained on large-scale vision-text datasets, provides zero-shot generalization to visual data, and the LLM endows its high reasoning ability to VLMs. It leads VLMs to achieve high performance on wide benchmarks without fine-tuning, exhibiting zero or few-shot capability. However, recent studies show that VLMs are vulnerable to hallucination. This undesirable behavior degrades reliability and credibility, thereby making users unable to fully trust the output from VLMs. To enhance trustworthiness and better tackle the hallucination of VLMs, we curate a new evaluation dataset, called the BEfore-AFter hallucination dataset (BEAF), and introduce new metrics: True Understanding (TU), IGnorance (IG), StuBbornness (SB), and InDecision (ID). Unlike prior works that focus only on constructing questions and answers, the key idea of our benchmark is to manipulate visual scene information by image editing models and to design the metrics based on scene changes. This allows us to clearly assess whether VLMs correctly understand a given scene by observing the ability to perceive changes. We also visualize image-wise object relationship by virtue of our two-axis view: vision and text. Upon evaluating VLMs with our dataset, we observed that our metrics reveal different aspects of VLM hallucination that have not been reported before. Project page: \url{https://beafbench.github.io/}
Exploiting Synthetic Data for Data Imbalance Problems: Baselines from a Data Perspective
Aug 02, 2023



We live in a vast ocean of data, and deep neural networks are no exception to this. However, this data exhibits an inherent phenomenon of imbalance. This imbalance poses a risk of deep neural networks producing biased predictions, leading to potentially severe ethical and social consequences. To address these challenges, we believe that the use of generative models is a promising approach for comprehending tasks, given the remarkable advancements demonstrated by recent diffusion models in generating high-quality images. In this work, we propose a simple yet effective baseline, SYNAuG, that utilizes synthetic data as a preliminary step before employing task-specific algorithms to address data imbalance problems. This straightforward approach yields impressive performance on datasets such as CIFAR100-LT, ImageNet100-LT, UTKFace, and Waterbird, surpassing the performance of existing task-specific methods. While we do not claim that our approach serves as a complete solution to the problem of data imbalance, we argue that supplementing the existing data with synthetic data proves to be an effective and crucial preliminary step in addressing data imbalance concerns.
Scratching Visual Transformer's Back with Uniform Attention
Oct 16, 2022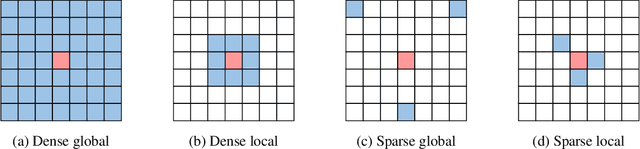

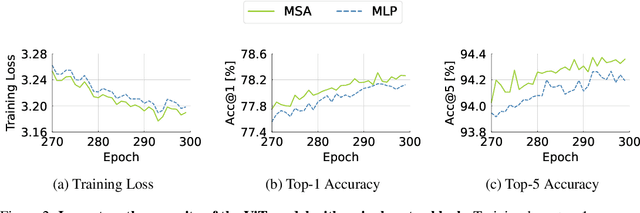
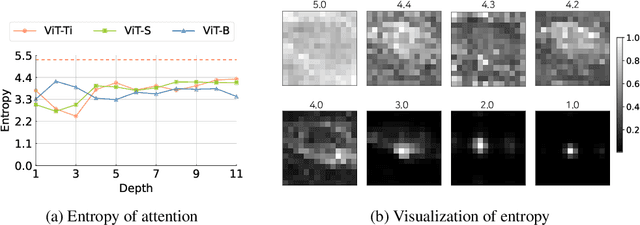
The favorable performance of Vision Transformers (ViTs) is often attributed to the multi-head self-attention (MSA). The MSA enables global interactions at each layer of a ViT model, which is a contrasting feature against Convolutional Neural Networks (CNNs) that gradually increase the range of interaction across multiple layers. We study the role of the density of the attention. Our preliminary analyses suggest that the spatial interactions of attention maps are close to dense interactions rather than sparse ones. This is a curious phenomenon, as dense attention maps are harder for the model to learn due to steeper softmax gradients around them. We interpret this as a strong preference for ViT models to include dense interaction. We thus manually insert the uniform attention to each layer of ViT models to supply the much needed dense interactions. We call this method Context Broadcasting, CB. We observe that the inclusion of CB reduces the degree of density in the original attention maps and increases both the capacity and generalizability of the ViT models. CB incurs negligible costs: 1 line in your model code, no additional parameters, and minimal extra operations.
FedPara: Low-rank Hadamard Product Parameterization for Efficient Federated Learning
Aug 13, 2021

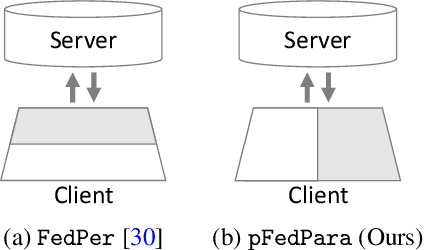

To overcome the burdens on frequent model uploads and downloads during federated learning (FL), we propose a communication-efficient re-parameterization, FedPara. Our method re-parameterizes the model's layers using low-rank matrices or tensors followed by the Hadamard product. Different from the conventional low-rank parameterization, our method is not limited to low-rank constraints. Thereby, our FedPara has a larger capacity than the low-rank one, even with the same number of parameters. It can achieve comparable performance to the original models while requiring 2.8 to 10.1 times lower communication costs than the original models, which is not achievable by the traditional low-rank parameterization. Moreover, the efficiency can be further improved by combining our method and other efficient FL techniques because our method is compatible with others. We also extend our method to a personalized FL application, pFedPara, which separates parameters into global and local ones. We show that pFedPara outperforms competing personalized FL methods with more than three times fewer parameters.